
Giới thiệu về XML
Mục lục
Khái niệm XML
XML là một ngôn ngữ đánh dấu được sử dụng để xác định ý nghĩa và sắp xếp cấu trúc của tài liệu văn bản. Ngôn ngữ đánh dấu giúp tài liệu bằng cách cung cấp cho chúng góc nhìn mới và giải pháp để định dạng văn bản.
Ngôn ngữ đánh dấu được phân loại thành các loại sau:
Đánh dấu trình bày (Presentational Markup): Ngôn ngữ đánh dấu trình bày tập trung vào cấu trúc của tài liệu.
Đánh dấu thủ tục (Procedural Markup): Đánh dấu theo thủ tục tương tự như đánh dấu bản trình bày nhưng trước đây, Người dùng sẽ có thể chỉnh sửa tệp văn bản. Tại đây, người dùng được phần mềm trợ giúp sắp xếp văn bản. Các ngôn ngữ đánh dấu này được sử dụng trong các tổ chức xuất bản chuyên nghiệp.
Đánh dấu mô tả (Descriptive Markup): Đánh dấu mô tả còn được gọi là đánh dấu ngữ nghĩa. Loại đánh dấu này xác định nội dung của tài liệu.
Hai kiểu ngôn ngữ đánh dấu phổ biến trong thời gian gần đây như sau:
- Ngôn ngữ đánh dấu tổng quát: Những loại ngôn ngữ này mô tả cấu trúc và ý nghĩa của văn bản trong tài liệu.
- Ngôn ngữ đánh dấu cụ thể: Các loại ngôn ngữ đánh dấu này được sử dụng để tạo mã dành riêng cho ứng dụng.
Ngôn ngữ đánh dấu tổng quát (Generalized Markup Language – GML), một dự án của IBM, đã giúp các tài liệu được chỉnh sửa, định dạng và tìm kiếm bởi các chương trình khác nhau bằng cách sử dụng các thẻ dựa trên nội dung của nó. Ngôn ngữ đánh dấu tổng quát (GML) được phát triển để thực hiện những điều sau:
- Phần đánh dấu chỉ nên mô tả cấu trúc của tài liệu chứ không mô tả cấu trúc của nó.
- Cú pháp của ngôn ngữ đánh dấu phải được tuân thủ nghiêm ngặt để chương trình phần mềm hoặc con người có thể đọc được mã một cách rõ ràng.
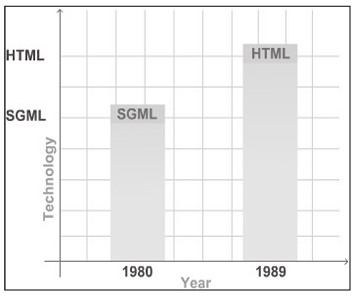
Năm 1980, Ủy ban ANSI đã tạo ra Ngôn ngữ đánh dấu tổng quát hóa tiêu chuẩn (Standard Generalized Markup Language – SGML), một sơ đồ mã hóa toàn diện và bộ công cụ linh hoạt để phát triển các ngôn ngữ đánh dấu chuyên biệt. SGML là sự kế thừa của GML. Năm 1986, Tổ chức Tiêu chuẩn hóa Quốc tế (International Organization for Standardization – ISO) đã lấy nó làm tiêu chuẩn. SGML là một siêu ngôn ngữ vì các ngôn ngữ khác được tạo ra từ nó. SGML có một cú pháp để bao gồm đánh dấu trong tài liệu. SGML cũng có cú pháp để mô tả những thẻ nào được phép ở các vị trí khác nhau. Ứng dụng SGML bao gồm khai báo SGML và Định nghĩa loại tài liệu SGML (Document Type Definition – DTD).
Năm 1989, Ngôn ngữ đánh dấu siêu văn bản (HTML), một công nghệ chia sẻ thông tin bằng cách sử dụng các tài liệu văn bản siêu liên kết đã được phát triển. HTML được tạo từ SGML. Trong những năm đầu, nó được sử dụng rộng rãi được các nhà khoa học và kỹ thuật viên tiếp cận. HTML ban đầu được tạo ra để đánh dấu các tài liệu kỹ thuật, để chúng có thể được chuyển qua các nền tảng khác nhau. Tuy nhiên, theo thời gian, nó cũng có thể được sử dụng để đánh dấu các tài liệu phi kỹ thuật. Khi việc sử dụng Intemet trở nên phổ biến, các nhà sản xuất trình duyệt bắt đầu phát triển các thẻ khác nhau để hiển thị tài liệu một cách sáng tạo hơn. Tuy nhiên, điều này tạo ra các vấn đề khi triển khai trong các trình duyệt khác nhau với sự gia tăng số lượng thẻ được sử dụng.
Các ưu điểm và nhược điểm của các ngôn ngữ đánh dấu trước đó là:
Ưu điểm
- GML mô tả tài liệu theo định dạng, cấu trúc và các thuộc tính khác.
- SGML đảm bảo rằng hệ thống có thể biểu diễn dữ liệu theo cách riêng của nó.
- HTML đã sử dụng văn bản ASCII, cho phép người dùng sử dụng bất kỳ trình soạn thảo văn bản nào.
Nhược điểm
- GML và SGML không phù hợp để trao đổi dữ liệu qua Web.
- HTML sở hữu các hướng dẫn về cách hiển thị nội dung hơn là nội dung mà chúng mang theo.
Sự phát triển của XML
Để giải quyết các vấn đề do các ngôn ngữ đánh dấu trước đó đưa ra, Ngôn ngữ đánh dấu mở rộng (XML) đã được tạo. XML là một khuyến nghị của W3C.
XML là một tập hợp các quy tắc để xác định các thẻ ngữ nghĩa chia tài liệu thành các phần và xác định các phần khác nhau của tài liệu. XML được phát triển trên HTML vì những khác biệt cơ bản giữa chúng được đưa ra trong bảng dưới
| HTML | XML |
| HTML được thiết kế để hiển thị dữ liệu | XML được thiết kế để nắm giữ dữ liệu |
| HTML hiển thị dữ liệu và tập trung vào cách dữ liệu trông như thế nào | XML mô tả dữ liệu và tập trung xác định nghữ nghĩa dữ liệu là gì |
| HTML hiển thị thông tin | XML mô tả thông tin |
Ví dụ về XML
<?xml version="1.0" encoding="iso-8859-1" ?>
<Watch>
<name>Titan</name>
<price>$50</price>
<description>Waterproof</description>
</Watch>
Đặc điểm của XML
Các đặc điểm của XML như sau:
- XML là viết tắt của Extensible Markup Language
- XML là một ngôn ngữ đánh dấu giống như HTML
- XML được thiết kế để mô tả dữ liệu
- Các thẻ XML không được xác định trước, lập trình viên phải xác định các thẻ của riêng mình
XML sử dụng DTD hoặc XML Schema để mô tả dữ liệu - XML với DTD hoặc XML schema được thiết kế để có thể tự mô tả
XML Markup
XML Markup xác định bố cục vật lý và logic của tài liệu. XML có thể được coi là một thùng chứa thông tin. Nó chứa các hình dạng, nhãn, cấu trúc và cũng bảo vệ thông tin. XML sử dụng cấu trúc dựa trên cây để biểu diễn một tài liệu. Nền tảng cơ bản của XML được đặt ra bởi các ký hiệu nhúng trong văn bản được gọi là đánh dấu. Đánh dấu kết hợp văn bản và thông tin bổ sung về văn bản, chẳng hạn như cấu trúc và cách trình bày của nó. Đánh dấu phân chia thông tin thành một hệ thống phân cấp dữ liệu ký tự và các phần tử giống như vùng chứa và các thuộc tính của nó. Một số chương trình phần mềm xử lý tài liệu điện tử sử dụng đánh dấu.
Đơn vị cơ bản của XML là một ký tự. Sự kết hợp của các ký tự được gọi là một thực thể. Các thực thể này có mặt trong khai báo thực thể hoặc trong tệp văn bản được lưu trữ bên ngoài. Tất cả các ký tự được nhóm lại với nhau để tạo thành một tài liệu XML
XML Markup chia tài liệu thành các vùng chứa thông tin riêng biệt được gọi là các phần tử. Một tài liệu bao gồm một phần tử ngoài cùng được gọi là phần tử gốc chứa tất cả các phần tử khác, cộng với một số thông tin quản trị tùy chọn ở trên cùng, được gọi là khai báo XML. Đoạn mã sau thể hiện các phần tử:
<?xml version="1.0" encoding="iso-8859-1" ?>
<FlowerPlanet>
<Name>Rose</Name>
<Price>$1</Price>
<Description>Red in color</Description>
<Number>700</Number>
</FlowerPlanet>Trong đó:
Name, Price, Description, Number bên trong các thẻ là các phần tử.
FlowerPlanet là phần tử gốc.
Việc sử dụng XML có thể được quan sát thấy trong nhiều tình huống thực tế. Nó có thể được sử dụng trong các lĩnh vực chia sẻ thông tin, sử dụng ứng dụng đơn lẻ, phân phối nội dung, sử dụng lại dữ liệu, phân tách dữ liệu và trình bày, ngữ nghĩa, v.v. Các hãng thông tấn là nơi phổ biến sử dụng XML. Các nhà sản xuất tin tức và người tiêu dùng tin tức thường sử dụng một đặc tả tiêu chuẩn có tên XMLNews để sản xuất, truy xuất và chuyển tiếp thông tin qua các hệ thống khác nhau trên thế giới.
Lưu ý: XML là một tập hợp con của SGML, có cùng mục tiêu, nhưng loại bỏ càng nhiều độ phức tạp càng tốt. Điều này có nghĩa là bất kỳ tài liệu nào tuân theo các quy tắc cú pháp của XML cũng sẽ tuân theo các quy tắc cú pháp của SGML và do đó có thể được đọc bởi các công cụ SGML hiện có.
Ưu điểm và nhược điểm của XML
Ưu điểm
Độc lập dữ liệu
Độc lập dữ liệu là đặc điểm cơ bản của XML. Nó tách nội dung khỏi phần trình bày của nó. Vì một tài liệu XML mô tả dữ liệu nên nó có thể được xử lý bởi bất kỳ ứng dụng nào.
Dễ phân tích cú pháp hơn
Việc không có hướng dẫn định dạng giúp dễ dàng phân tích cú pháp. Điều này làm cho XML trở thành một khuôn khổ lý tưởng để trao đổi dữ liệu.
Giảm Tải Máy Chủ
Thông tin cấu trúc và ngữ nghĩa của XML cho phép nó được thao tác bởi bất kỳ ứng dụng nào.
Quá trình xử lý trước đây chỉ giới hạn ở các máy chủ giờ đây có thể được thực hiện bởi các máy khách. Điều này làm giảm tải máy chủ và lưu lượng mạng, dẫn đến Web nhanh hơn, hiệu quả hơn.
Dễ tạo hơn
Nó dựa trên văn bản, vì vậy rất dễ dàng để tạo một tài liệu XML với ngay cả những công cụ xử lý văn bản thô sơ nhất. Tuy nhiên, XML cũng có thể mô tả hình ảnh, đồ họa vector, hoạt hình hoặc bất kỳ loại dữ liệu nào khác mà nó mở rộng.
Nội dung trang web
W3C sử dụng XML để viết các thông số kỹ thuật của nó và chuyển đổi nó sang một số định dạng trình bày khác. Một số trang Web cũng sử dụng XML cho nội dung của chúng và biến nó thành HTML bằng cách sử dụng XSLT và CSS và hiển thị nội dung trực tiếp trong trình duyệt.
Remote Procedure Calls (Thủ tục gọi từ xa)
XML cũng được sử dụng như một giao thức cho các cuộc gọi thủ tục từ xa (RPC). RPC là một giao thức cho phép các đối tượng trên một máy tính gọi các đối tượng trên máy tính khác để thực hiện công việc, cho phép tính toán phân tán.
Thương mại điện tử
XML có thể được sử dụng làm định dạng trao đổi để gửi dữ liệu từ công ty này sang công ty khác.
Lưu ý: Quá trình xử lý một tài liệu XML được gọi là Phân tích cú pháp XML (XML Parsing). Trình phân tích cú pháp tải tài liệu vào bộ nhớ. Sau khi tài liệu được tải vào bộ nhớ, Mô hình đối tượng tài liệu (DOM) sẽ thao tác dữ liệu.
Nhược điểm
Việc sử dụng XML dẫn đến tăng kích thước dữ liệu và thời gian xử lý. Vì XML sử dụng bộ mã hóa Unicode cho các ký tự nên nó cũng tiêu tốn nhiều bộ nhớ hơn.
- XML thiếu số lượng đầy đủ các hướng dẫn xử lý. Nếu quá trình dịch không được sử dụng, thì các nhà phát triển trên toàn cầu buộc phải chuẩn bị các hướng dẫn xử lý của riêng họ để hiển thị XML ở dạng được yêu cầu.
- XML đòi hỏi khắt khe hơn và khó hơn so với HTML.
- XML dài dòng vì các thẻ được sử dụng trong đó được xác định trước,
- Các phiên bản Internet Explorer (IE) cũ hơn 5.0 không hỗ trợ XML
Khám phá XML
Cấu trúc tài liệu XML
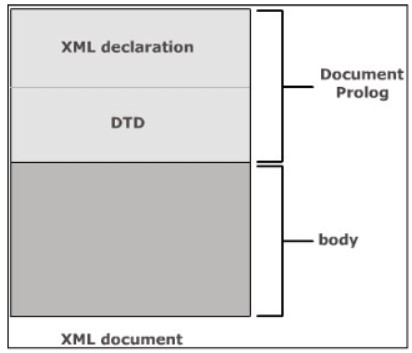
Các tài liệu XML thường được lưu trữ trong các tệp văn bản có phần mở rộng xml. Hai phần của một tài liệu XML là:
Document Prolog: Trình phân tích cú pháp XML lấy thông tin về nội dung trong tài liệu với sự trợ giúp của Document Prolog. Document Prolog chứa siêu dữ liệu và bao gồm hai phần – Khai báo XML và Khai báo kiểu tài liệu. Khai báo XML chỉ định phiên bản XML đang được sử dụng. Khai báo loại tài liệu xác định các giá trị của thực thể hoặc thuộc tính, đồng thời kiểm tra ngữ pháp và từ vựng của đánh dấu.
Root Element (Phần tử gốc) một phần tử được gọi là phần tử gốc. Phần tử gốc còn được gọi là phần tử tài liệu. Nó phải chứa tất cả các yếu tố và nội dung khác trong tài liệu. Một phần tử XML có thẻ bắt đầu và thẻ kết thúc.
Sau đây là một số mối quan hệ:
Parent (cha): Đây là một phần tử chứa các phần tử khác,
Child (Con): Nó là một phần tử hiện diện trong một phần tử khác.
Sibling (Anh chị em): Chúng là những phần tử có cùng phần tử cha.
Nesting (Lồng ghép): Đây là một quá trình trong đó một phần tử chứa các phần tử khác.
Một tài liệu XML bao gồm một tập hợp các “thực thể” được đặt tên rõ ràng. Mọi tài liệu XML đều bắt đầu bằng “root” hoặc thực thể tài liệu. Tất cả các thực thể khác là tùy chọn. Các thực thể là bí danh cho các chức năng phức tạp hơn.
Một tên thực thể duy nhất có thể đại diện cho một lượng lớn văn bản. Tên bí danh được sử dụng mỗi khi một số văn bản được tham chiếu và bộ xử lý mở rộng nội dung của bí danh.
Ví dụ mẫu đoạn code mô tả cấu trúc XML:
<?xml version="1.0" encoding="iso-8859-1" ?>
<!DOCTYPE Music_Library [
<!ELEMENT Music_Library (Title, Artist, Country, Price, Year)>
<!ELEMENT Title (#PCDATA)>
<!ELEMENT Artist (#PCDATA)>
<!ELEMENT Country (#PCDATA)>
<!ELEMENT Price (#PCDATA)>
<!ELEMENT Year (#PCDATA)>
]>
<Music_Library>
<Title>ABC</Title>
<Artist>Son Tung</Artist>
<Country>Viet Nam</Country>
<Price>$20</Price>
<Year>2023</Year>
</Music_Library>Trong đó:
Khối đầu tiên cho biết khai báo xml và khai báo loại tài liệu (document Prolog).
Music_Library là phần tử gốc.
Cấu trúc logic
Cấu trúc logic của một tài liệu XML cung cấp thông tin về các phần tử và thứ tự mà chúng sẽ được đưa vào tài liệu.
Nó chỉ ra cách một tài liệu được xây dựng hơn là những gì nó chứa.
Document Prolog tạo cơ sở cho cấu trúc logic của tài liệu XML. Khai báo XML và Định nghĩa kiểu tài liệu là hai thành phần cơ bản và tùy chọn của nó như trong hình dưới
Đoạn mã sau minh họa khai báo XML
<?xml version="1.0" encoding="iso-8859-1" ?>Khai báo XML đưa ra phiên bản của đặc tả XML và cũng xác định lược đồ mã hóa ký tự.
Mã sau minh họa việc sử dụng DTD.
<!DOCTYPE Music_Library SYSTEM "Mlibrary.dtd">Định nghĩa kiểu tài liệu xác định một bộ quy tắc mà tài liệu XML tuân theo. Một DTD có thể là bên ngoài hoặc bên trong. Trong trường hợp này, DTD là một tệp bên ngoài.
Vòng đời tài liệu XML
Trình soạn thảo XML đề cập đến DTD và tạo tài liệu XML. Sau khi tài liệu được tạo, tài liệu được quét để tìm các thành phần và thuộc tính trong Tài liệu. Giai đoạn này được gọi là quét. Trình phân tích cú pháp XML xây dựng cấu trúc dữ liệu hoàn chỉnh sau khi phân tích cú pháp. Dữ liệu sau đó được trích xuất từ các phần tử và thuộc tính của tài liệu. Giai đoạn này được gọi là truy cập. Sau đó nó được chuyển đổi thành chương trình ứng dụng. Cấu trúc tài liệu cũng có thể được sửa đổi trong quá trình này bằng cách chèn hoặc xóa các phần tử hoặc bằng cách thay đổi nội dung văn bản của phần tử hoặc thuộc tính. Giai đoạn này được gọi là sửa đổi. Dữ liệu sau đó được tuần tự hóa thành dạng văn bản và được chuyển đến trình duyệt hoặc bất kỳ ứng dụng nào khác có thể hiển thị dữ liệu đó. Giai đoạn này được gọi là tuần tự hóa.
Lưu ý: Trình phân tích cú pháp XML tạo, thao tác và cập nhật tài liệu XML. Nó sẽ đọc danh sách các bản ghi trong tài liệu XML và trình xử lý lưu trữ nó dưới dạng cấu trúc dữ liệu. Trình xử lý sau đó xử lý nó và hiển thị nó trong HTML.
Trình soạn thảo XML
Trình soạn thảo XML được sử dụng để tạo và chỉnh sửa tài liệu XML. Bất kỳ ứng dụng nào cũng có thể được sử dụng làm trình soạn thảo trong XML. Vì tất cả các tài liệu XML đều là ngôn ngữ đánh dấu dựa trên văn bản, nên cũng có thể sử dụng Windows Notepad tiêu chuẩn (hoặc Wordpad. Tuy nhiên, vì nhiều lý do, Notepad không nên được sử dụng để viết XML chuyên nghiệp. Notepad không biết rằng văn bản được viết bằng XML Để một tài liệu XML không có lỗi và có các tính năng dành riêng cho XML, chẳng hạn như khả năng chỉnh sửa các thành phần và thuộc tính, nên sử dụng một trình soạn thảo XML chuyên nghiệp.
Các chức năng chính mà trình soạn thảo cung cấp như sau:
- Thêm thẻ đóng mở vào code
- Kiểm tra tính hợp lệ của XML
- Xác minh XML dựa trên DTD/Schema
- Thực hiện hàng loạt phép biến đổi trên tài liệu
- Tô màu cú pháp XML
- Hiển thị số dòng
- Trình bày nội dung và ẩn mã
- Hoàn thiện văn bản
Các trình soạn thảo được sử dụng phổ biến là:
- XMLWriter
- XML Spy
- XML Pro
- XMLmind
- XMetal
Trình phân tích cú pháp
Trình phân tích cú pháp XML/bộ xử lý XML đọc tài liệu và xác minh xem nó có đúng định dạng hay không.
Trình phân tích cú pháp XML giữ toàn bộ biểu diễn dữ liệu XML trong bộ nhớ với sự trợ giúp của Mô hình đối tượng tài liệu (DOM). Trình phân tích cú pháp in-built được sử dụng trong IE 5.0 còn được gọi là Trình phân tích cú pháp XML của Microsoft (MSXML). Nó là thành phần, có sẵn sau khi IE 5.0 được cài đặt.
Trình phân tích cú pháp XML của Microsoft đi qua toàn bộ cấu trúc dữ liệu và truy cập các giá trị của các thuộc tính trong các phần tử. Trình phân tích cú pháp cũng tạo hoặc xóa các phần tử và chuyển đổi cấu trúc cây thành XML.
MSXML hỗ trợ một số đối tượng COM để có khả năng tương tác ngược.
Một số trong số chúng là đối tượng XSLProcessor, đối tượng XSLTemplate, đối tượng XMLDOMSelection, đối tượng XMLSchemaCache và đối tượng XMLDOMDocument2.
MSXML 3.0 hỗ trợ các biến đổi XSL, chứa các thao tác thao tác dữ liệu. Trình phân tích cú pháp XML bỏ qua khoảng trắng theo mặc định, nhưng nếu giá trị mặc định của Boolean bảo toàn thuộc tính WhiteSpace của đối tượng DOMDocument là đúng, thì trình phân tích cú pháp XML sẽ bảo toàn khoảng trắng. Sử dụng Lược đồ kiểu dữ liệu của Microsoft, MSXML 3.0 chỉ định một kiểu dữ liệu cho phần tử hoặc thuộc tính. MSXML cũng cải thiện hiệu suất của các ứng dụng với sự trợ giúp của các tính năng bộ nhớ đệm khác nhau.
Phân tích cú pháp XML trong Mozilla thực hiện các chức năng như duyệt qua các phần tử, truy cập các giá trị của chúng, v.v. Sử dụng JavaScript, một phiên bản của trình phân tích cú pháp XML có thể được tạo trong trình duyệt Mozilla. Phân tích cú pháp XML trong Firefox sẽ tự động phân tích cú pháp dữ liệu thành Mô hình đối tượng tài liệu (DOM). Opera chỉ sử dụng những trình phân tích cú pháp XML không xác thực DTD theo mặc định.
Tốc độ và hiệu suất là các tiêu chí để chọn các trình phân tích cú pháp XML. Các trình phân tích cú pháp thường được sử dụng là:
- Crimson
- Xerces
- Oracle XML Parser
- JAXP(Java API for XML)
- MSXML
Hai loại trình phân tích cú pháp là:
Trình phân tích cú pháp không xác thực (Non Validating parser)
Nó kiểm tra tính hợp lệ của tài liệu.
Đọc tài liệu và kiểm tra sự phù hợp của nó với các tiêu chuẩn XML.
Trình phân tích cú pháp xác thực (Validating parser)
Kiểm tra tính hợp lệ của của tài liệu bằng DTD.
Trình duyệt
Sau khi tài liệu XML được đọc, trình phân tích cú pháp sẽ chuyển cấu trúc dữ liệu tới ứng dụng khách. Ứng dụng này có thể là một trình duyệt Web. Trình duyệt sau đó định dạng dữ liệu và hiển thị nó cho người dùng. Các chương trình khác như cơ sở dữ liệu, chương trình MIDI hoặc chương trình bảng tính cũng có thể nhận dữ liệu và trình bày dữ liệu tương ứng.
Đầu ra cuối cùng của dữ liệu XML có thể xem được trong trình duyệt.
Trong IE, XML có thể được xem trực tiếp bằng biểu định kiểu. Nó cung cấp hỗ trợ cho các không gian tên và xử lý một cơ chế được gọi là đảo dữ liệu nơi XML được nhúng vào HTML.
Mozilla 5.0 sử dụng giao diện với XML DOM (Mô hình đối tượng tài liệu) thông qua JavaScript và các phần bổ trợ. Nó cũng hỗ trợ các phần tử từ HTML namespace.
Các trình duyệt Web thường được sử dụng như sau:
- Mozilla FireFox
- Google Chrome
- Internet Explorer
- Opera
Làm việc với XML
Một tài liệu XML có ba thành phần chính:
- Thẻ (đánh dấu) và văn bản (nội dung)
- DTD hoặc Schema
- Thông số kỹ thuật định dạng hoặc hiển thị
Các bước xây dựng một tài liệu XML như sau:
Tạo tài liệu XML trong trình soạn thảo
Để tạo một tài liệu XML đơn giản, bạn nhập mã XML vào bất kỳ văn bản hoặc trình soạn thảo XML nào như được minh họa trong đoạn mã sau.

Lưu tệp XML
Sau khi gõ xong, bạn lưu nội dung của tệp. Để lưu tệp, bạn nhấp vào menu Tệp, nhấp vào tùy chọn “Lưu” và cung cấp tên tệp, chẳng hạn như Soft_Drink.xml. Phần mở rộng .xml là bắt buộc nếu bạn đang nhập mã trong Notepad hoặc bất kỳ loại trình xử lý văn bản nào, chẳng hạn như Microsoft Word.
Tải tài liệu XML trong trình duyệt
Sau khi tài liệu được lưu, bạn có thể mở tệp trực tiếp trong trình duyệt hỗ trợ XML. Trình duyệt phổ biến được sử dụng là Intemet Explorer 5.0 trở lên.
Khám phá tài liệu XML
Các khối xây dựng khác nhau bên trong cấu trúc của một tài liệu XML như sau:
- Khai báo phiên bản XML
- Định nghĩa loại tài liệu
- Phiên bản tài liệu trong đó nội dung được định nghĩa bởi markup
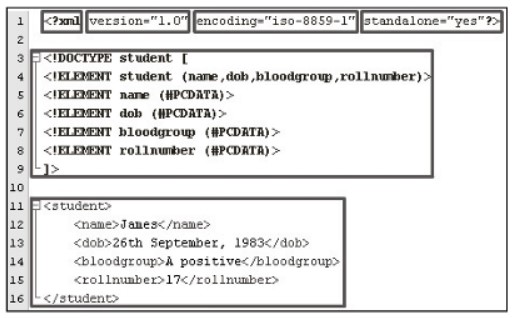
Giải thích cho các khu vực được đánh dấu trong mã:
<?xmlKhai báo XML phải bắt đầu bằng chuỗi năm ký tự, <?xml Nó chỉ ra rằng tài liệu là một tài liệu XML.
version="1.0"Khai báo XML cho biết phiên bản XML, kiểu mã hóa ký tự đang được sử dụng và khai báo đánh dấu được sử dụng trong tài liệu XML.
encoding="iso-8859-1"Các ký tự được mã hóa bằng các định dạng mã hóa khác nhau. Mã hóa ký tự được khai báo trong khai báo mã hóa.
standalone="yes"Khai báo standalone (độc lập) chỉ ra sự hiện diện của khai báo đánh dấu bên ngoài. “Yes” cho biết rằng không có khai báo đánh dấu bên ngoài nào và “không” cho biết có thể tồn tại các khai báo đánh dấu bên ngoài.
Khai báo kiểu tài liệu khai báo và định nghĩa các thành phần được sử dụng trong lớp tài liệu. Đây là một DTD được sử dụng nội bộ như được minh họa trong đoạn mã sau:

Nếu cùng một DTD được sử dụng bên ngoài, thì mã là:

Phần này xác định nội dung của tài liệu XML được gọi là markup (đánh dấu). Nó mô tả mục đích và chức năng của từng phần tử.
Lưu ý: Các thẻ trong XML không được xác định trước, XML cho phép người dùng tạo các thẻ khi cần thiết
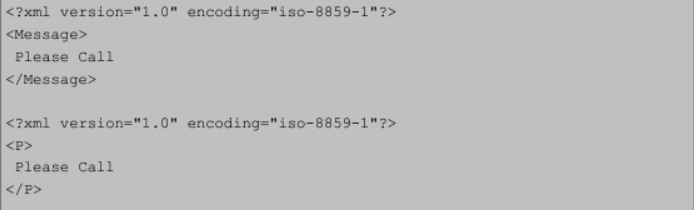
Hai đoạn mã XML được liệt kê hiển thị cùng một đầu ra với các tên khác nhau. Chúng bình đẳng vì chúng có cùng cấu trúc và nội dung.
Ý nghĩa trong markup
Markup có thể được chia thành ba phần sau:
Cấu trúc
Nó mô tả hình thức của tài liệu bằng cách xác định mối quan hệ giữa các phần tử khác nhau trong tài liệu. Nó nhấn mạnh để chỉ định một phần tử gốc, không trống, có chứa các phần tử khác và nội dung.
Ngữ nghĩa
Ngữ nghĩa mô tả cách mỗi phần tử được chỉ định cho thế giới bên ngoài của tài liệu. Ví dụ: trình duyệt Web hỗ trợ HTML gán “đoạn văn” cho các thẻ.
Định kiểu (style)
Nó chỉ định cách hiển thị nội dung của thẻ hoặc phần tử. Nó cho biết thẻ được in đậm, bình thường và có màu hồng hay với cỡ chữ 10.
Well-formed XML Document
Định dạng tốt đề cập đến các tiêu chuẩn mà các tài liệu XML phải tuân theo. Định dạng tốt làm cho bộ xử lý XML và trình duyệt đọc tài liệu XML. Một tài liệu được định dạng tốt nếu nó đáp ứng các quy tắc sau:
Cần tối thiểu một phần tử
Mọi tài liệu XML được định dạng tốt nên bao gồm tối thiểu một phần tử.
Các thẻ XML phân biệt chữ hoa chữ thường
Tất cả các thẻ được sử dụng đều phân biệt chữ hoa chữ thường, nghĩa là khác với .
Mọi thẻ bắt đầu phải kết thúc bằng thẻ kết thúc
Tất cả các thẻ trong XML phải bắt đầu bằng thẻ bắt đầu và thẻ kết thúc phù hợp. Các thẻ kết thúc chỉ có một dấu gạch chéo bổ sung so với thẻ bắt đầu của chúng.
Các thẻ XML phải được lồng vào nhau đúng cách
Tất cả các thẻ XML được sử dụng phải được lồng vào nhau đúng cách.
Ví dụ:

Các thẻ XML phải hợp lệ
- Các thẻ phải bắt đầu bằng chữ cái, dấu gạch dưới (_), dấu hai chấm ()
- Các thẻ phải chứa sự kết hợp của các chữ cái, số, dấu chấm (.), dấu hai chấm, dấu gạch dưới hoặc dấu gạch nối (-).
- Các thẻ phải chứa khoảng trắng.
- Các thẻ không nên bắt đầu bằng các từ dành riêng như “xml”
Độ dài của tên markup
Độ dài của các thẻ phụ thuộc vào bộ xử lý XML.
Các thuộc tính XML phải hợp lệ
- Các thuộc tính không được trùng lặp
- Các thuộc tính được xác định bởi một cặp tên và giá trị được phân cách bằng dấu bằng (=). Các giá trị được phân định bằng dấu ngoặc kép.
Ví dụ:
<DOLL NAME="BARBIE" COLOR="PINK">- Các thuộc tính phải tuân theo các quy tắc tương tự như các thẻ theo sau.
Tài liệu XML cần được xác minh
Để các trình duyệt XML có thể đọc được, tài liệu phải được kiểm tra theo các quy tắc XML.

Cú pháp XML
Comment
Comment trong XML được sử dụng để mọi người cung cấp thông tin về mã khi không có nhà phát triển. Nó giúp tài liệu dễ đọc hơn. Comment không bị hạn chế đối với các định nghĩa loại tài liệu nhưng có thể được đặt ở bất kỳ đâu trong tài liệu. Comment trong XML tương tự như trong HTML. Comment chỉ nên được sử dụng khi cần thiết, vì chúng không được xử lý. Comment chỉ được sử dụng để nhằm mục đích giải thích ngữ nghĩa cho con người hơn là của máy. Vì các comment không được phân tích cú pháp nên sự hiện diện hay vắng mặt của chúng không tạo ra bất kỳ sự khác biệt nào đối với bộ xử lý.
Chúng được chèn vào tài liệu XML và không phải là một phần của mã XML. Chúng có thể xuất hiện trong document prolog, DTD hoặc trong nội dung văn bản. Những nhận xét này sẽ không xuất hiện bên trong các thẻ hoặc giá trị thuộc tính.
Ví dụ comment trong XML:

Comment cần tuân thủ một số quy tắc:
- Comment không nên có dấu “-” hoặc “—” vì có thể gây nhầm lẫn cho trình phân tích cú pháp XML.
- Comment không được đặt trong thẻ hoặc khai báo thực thể.
- Không nên đặt comment trước phần khai báo XML.
- Comment có thể được sử dụng để bình luận các bộ thẻ.
Ví dụ:

Ví dụ 2:

Processing Instruction (Hướng dẫn xử lý)
Processing Instruction là thông tin dành riêng cho ứng dụng. Các hướng dẫn này không tuân theo các quy tắc XML hoặc cú pháp nội bộ. Với sự trợ giúp của trình phân tích cú pháp, các hướng dẫn này được chuyển đến ứng dụng. Ứng dụng có thể sử dụng các hướng dẫn xử lý hoặc chuyển chúng sang ứng dụng khác.
Mục tiêu chính của hướng dẫn xử lý là trình bày một số hướng dẫn đặc biệt cho ứng dụng. Tất cả hướng dẫn xử lý phải bắt đầu bằng <? và kết thúc bằng ?>
Mặc dù cú pháp khai báo XML cũng bắt đầu bằng <? và ?> nhưng không được coi là lệnh xử lý. đó là vì một khai báo XML chỉ cung cấp thông tin cho bộ phân tích cú pháp chứ không phải cho ứng dụng. Trong một số trường hợp, ứng dụng có thể chỉ cần thông tin trong hướng dẫn xử lý nếu nó hiển thị đầu ra cho người dùng.
Cú pháp:
<?PITarget <instruction>?>Trong đó:
PITarget là tên của ứng dụng sẽ nhận hướng dẫn xử lý.
instruction Là hướng dẫn cho ứng dụng.
Đoạn mã sau minh họa ví dụ về Processing instruction:
<?xml version="1.0" encoding="utf-8" ?>
<Name Nickname='Toan'>
<!-- Toan is yet to pay the term fees -->
<Last>Ngo</Last>
<?feesprocessor SELECT fees FROM STUDENTFEES ?>
<Semester>Final</Semester>
</Name>Trong đó:
feesprocessor là tên của ứng dụng nhận hướng dẫn xử lý.
SELECT fees FROM STUDENTFEES là hướng dẫn.
Phân loại dữ liệu ký tự (Classified character data)
Một tài liệu XML được chia thành dữ liệu đánh dấu (markup) và ký tự (character).
Dữ liệu ký tự mô tả nội dung thực tế của tài liệu với khoảng trắng. Văn bản trong dữ liệu ký tự không được trình phân tích cú pháp xử lý và do đó, không được coi là văn bản thông thường. Dữ liệu ký tự có thể được phân loại thành:
- CDATA (character data)
- PCDATA (parse character data)
PCDATA
Dữ liệu được trình phân tích cú pháp phân tích cú pháp được gọi là dữ liệu ký tự được phân tích cú pháp (parse character data) (PCDATA). PCDATA chỉ định rằng phần tử đã phân tích cú pháp dữ liệu ký tự. Nó được sử dụng trong khai báo phần tử.
Ví dụ sau đây sẽ báo lỗi:
<?xml version="1.0" encoding="utf-8" ?>
<Name Nickname='Toan'>
<!-- Toan is yet to pay the term fees -->
<Last>Ngo</Last>
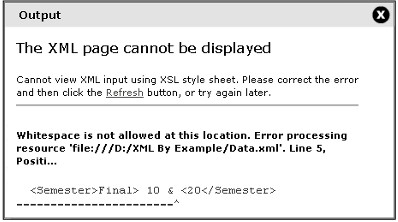
<Semester>10 & <20</Semester>
</Name>Ký tự thoát như “<” khi được sử dụng trong tài liệu XML sẽ khiến trình phân tích cú pháp diễn giải nó như một phần tử mới. Kết quả là sẽ tạo ra một lỗi như trong hình dưới:
CDATA
CDATA là viết tắt của dữ liệu ký tự có ký tự dành riêng và khoảng trắng trong đó. Mặc dù văn bản bên trong CDATA không được trình phân tích cú pháp phân tích cú pháp, nó thường được sử dụng cho mã kịch bản. Trình phân tích cú pháp XML bỏ qua tất cả các thẻ và tham chiếu thực thể bên trong các khối CDATA. Khối CDATA cho trình phân tích cú pháp biết rằng nó chỉ là một văn bản chứ không phải là một đánh dấu (markup). Một khối CDATA luôn bắt đầu bằng dấu phân cách <! [CDATA[ và kết thúc bằng dấu phân cách ]]> Do dấu phân cách kết thúc đánh dấu phần cuối của khối CDATA, chuỗi ký tự ]]> không được phép ở giữa khối CDATA. Điều này sẽ báo hiệu kết thúc phần CDATA.
Cú pháp:
<![CDATA [ data ]]>Ví dụ:
<?xml version="1.0" encoding="utf-8" ?>
<Sample>
<![CDATA[
<Document>
<Name>Core XML</Name>
<Company>Tech888 Viet Nam</Company>
</Document>
]]>
</Sample>Entities (thực thể)
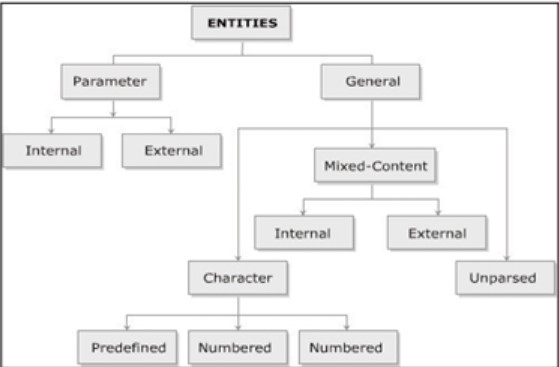
Tài liệu XML được tạo thành từ một lượng lớn thông tin được gọi là các thực thể. Các thực thể được sử dụng để tránh gõ lặp đi lặp lại các đoạn văn bản dài trong tài liệu. Chúng có thể được phân loại thành như sau:
- Các thực thể ký tự (Character entites): Chúng tạo thành cơ chế, được sử dụng thay cho dạng chữ của một ký tự, Chúng cung cấp ý nghĩa của ‘>’ khi ký hiệu ‘>’ được gõ. Các thực thể ký tự cũng có thể được sử dụng với các giá trị thập phân hoặc thập lục phân với điều kiện là các số hỗ trợ mã hóa Unicode. Một chương trình xử lý XML thay thế các thực thể ký tự bằng các ký tự tương đương của chúng.
- Thực thể nội dung (Content entities): Các thực thể này được sử dụng để thay thế các giá trị nhất định. Chúng tương tự như macro thay thế văn bản trong các ngôn ngữ lập trình như C. Thực thể nội dung có cú pháp sau:
- <!Entity name value>
- Các thực thể chưa được phân tích cú pháp (Unparsed entities): Các thực thể này khi được sử dụng sẽ tắt quá trình phân tích cú pháp. Chúng có thể được sử dụng để đưa nội dung đa phương tiện vào tài liệu XML.
Mỗi thực thể bao gồm một tên và một giá trị. Giá trị nằm trong phạm vi từ một ký tự đơn đến tệp đánh dấu XML. Khi tài liệu XML được phân tích cú pháp, nó sẽ kiểm tra các tham chiếu thực thể. Đối với mọi tham chiếu thực thể, trình phân tích cú pháp kiểm tra bộ nhớ để thay thế tham chiếu thực thể bằng văn bản hoặc đánh dấu.
Tham chiếu thực thể bao gồm dấu và (&), tên thực thể và dấu chấm phẩy (;)
Tất cả các thực thể phải được khai báo trước khi chúng được sử dụng trong tài liệu. Một thực thể có thể được khai báo trong prolog tài liệu hoặc trong DTD.
Một số thực thể được xác định trong hệ thống và được gọi là thực thể được xác định trước. Các thực thể này được mô tả trong bảng dưới:

Ví dụ entities:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE Letter [
<!ENTITY address "123 Main Street">
<!ENTITY city "Beverly Hills">
]>
<Letter>
<To>"Tom Smith"</To>
<Address>&address;</Address>
<City>&city;</City>
<Body>
hi ! How are you ?
The sum is > $1000
</Body>
<From>ARNOLD</From>
</Letter>Entity categories (Danh mục thực thể)
Các thực thể được sử dụng làm lối tắt để tham chiếu đến các trang dữ liệu.
Có hai loại thực thể như sau:
General Entity (Thực thể chung)
Đây là những thực thể được sử dụng trong nội dung tài liệu. Các thực thể chung có thể được khai báo bên trong hoặc bên ngoài. Các tham chiếu cho các thực thể chung bắt đầu bằng dấu và (&) và kết thúc
bằng dấu chấm phẩy (;). Tên của thực thể có mặt trong hai ký tự này.
Mọi thực thể chung bên trong được định nghĩa trong DTD. Nó được khai báo với từ khóa <!ENTITY>. Cú pháp như sau:
<!ENTITY Name "text that is to replaced">Trong đó:
Name: giá trị cho văn bản sẽ được thay thế.
Các thực thể bên ngoài đề cập đến các đơn vị lưu trữ bên ngoài tài liệu có chứa phần tử gốc. Sử dụng các tham chiếu thực thể bên ngoài, các thực thể bên ngoài có thể được nhúng bên trong tài liệu. Tham chiếu thực thể bên ngoài cho biết vị trí mà trình phân tích cú pháp sẽ chèn thực thể bên ngoài vào tài liệu. Thực thể bên ngoài có Bộ định vị tài nguyên thống nhất (URL) trong khai báo của nó; URL được chỉ định cho biết tài liệu có văn bản của thực thể. Cú pháp như sau:
<!ENTITY Name SYSTEM "URL">Đoạn mã minh họa một ví dụ về thực thể chung:

Parameter Entity (thực thể tham số)
Các loại thực thể này chỉ được sử dụng trong DTD. Các loại thực thể này được khai báo trong DTD. Không nên sử dụng cả hai thực thể tham số bên trong và bên ngoài trong nội dung của tài liệu XML vì bộ xử lý không nhận ra chúng. Thực thể tham số được định dạng tốt tương tự như thực thể chung, ngoại trừ việc nó sẽ bao gồm phần xác định %. Tham chiếu cũng tương tự như tham chiếu thực thể chung.
Tham chiếu đến các thực thể này được thực hiện bằng cách sử dụng dấu phần trăm (%) và dấu chấm phẩy (;) làm dấu phân cách
Mã sau minh họa một ví dụ về thực thể tham số:
<!ENTITY % ADDRESS "text that is to be represented by an entity">Thực thể tham số được định dạng tốt sẽ trông giống như một thực thể chung, ngoại trừ việc nó sẽ bao gồm phần xác định “%”.
Khai báo DOCTYPE
Khai báo DOCTYPE xác định các phần tử sẽ được sử dụng trong tài liệu.
Khai báo DOCTYPE được khai báo để cho biết tài liệu tuân theo DTD nào. Nó có thể được khai báo khác trong tài liệu XML hoặc có thể tham chiếu đến một tài liệu bên ngoài.
Cú pháp khai báo kiểu tài liệu như sau:

Trong đó:
name_of_root_element: tên của phần tử gốc.
SYSTEM: URL chứa DTD.
[Internal DTD subset]: là những khai báo có trong tài liệu.
Đoạn mã dưới ví dụ mô tả về khai báo kiểu tài liệu:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE program SYSTEM "HelloToan.dtd">
<Program>
<Comments>
This is a simple Java program
</Comments>
<Code>
public static void main(String[] args) {
System.out.println("Hello, World");
}
</Code>
</Program>DTD file:
<!ELEMENT Program (Comments,Code) >
<!ELEMENT Comments (#PCDATA) >
<!ELEMENT Code (#PCDATA) >Attributes (thuộc tính)
Các thuộc tính là một phần của các phần tử. Chúng cung cấp thông tin về phần tử và được nhúng trong thẻ bắt đầu phần tử. Một thuộc tính bao gồm một tên thuộc tính và một giá trị thuộc tính. Cái tên luôn
đứng trước giá trị của nó, được phân tách bằng dấu bằng. Giá trị thuộc tính được đặt trong dấu ngoặc kép để phân định nhiều thuộc tính trong cùng một phần tử. Một thuộc tính có thể là CDATA, ENTITY, ENUMERATION, ID, IDREF, NMTOKEN hoặc NOTATION.
Giá trị thuộc tính liệt kê (enumerated) được sử dụng khi các giá trị thuộc tính là một trong các giá trị pháp lý cố định. Thuộc tính của loại định danh (ID) phải là duy nhất. Nó được sử dụng để tìm kiếm một thể hiện cụ thể của một phần tử. Mỗi phần tử chỉ có thể có một thuộc tính loại ID. IDREF cũng là một loại định danh và nó chỉ nên trỏ đến một phần tử. Các thuộc tính IDREF có thể được sử dụng để chỉ một phần tử từ các phần tử khác. Thuộc tính loại NMTOKEN cho phép bất kỳ sự kết hợp nào của các ký tự name tokens. Các ký tự có thể là chữ cái, số, dấu chấm, dấu gạch ngang, dấu hai chấm hoặc dấu gạch dưới. Thuộc tính loại NMTOKENS cho phép nhiều giá trị nhưng được phân tách bằng khoảng trắng. Thuộc tính loại NOTATION phải tham chiếu đến một ký hiệu được khai báo ở nơi khác trong DTD. Một khai báo cũng có thể là một ví dụ cho một danh sách các ký hiệu.
Cú pháp:
<elementName attName1="attValue1" attName2="attvalue2" ... >Ví dụ:
<?xml version="1.0" ?>
<Player gender="male" number="10">
<FirstName>John</FirstName>
<LastName>Doe</LastName>
</Player>Các thuộc tính có một số hạn chế như sau:
- Không giống như các phần tử con, chúng không chứa nhiều giá trị và không mô tả cấu trúc.
- Chúng không thể mở rộng cho những thay đổi trong tương lai.
- Chúng không dễ dàng sử dụng bởi mã.
- Chúng không dễ kiểm tra với DTD.
Bài viết liên quan:

Dịch vụ thiết kế Wesbite




