Index trong SQL Server
Mục lục
Giới thiệu về index
Index là một cấu trúc dữ liệu đặc biêt liên kết với bảng hoặc view để tăng tốc độ truy vấn. Hiểu nôm na khi bạn đánh index cho 1 trường trong tables, các giá trị của trường đó sẽ được tổ chức lưu trữ có cấu trúc, sẽ giúp việc truy vấn dữ liệu đạt hiệu quả cao hơn về hiệu năng, tốc độ . Danh sách các index phổ biến trong SQL Server như sau:
| Kiểu index | Mô tả |
| Clustered | Nó sắp xếp và lưu trữ các hàng dữ liệu của bảng hoặc view theo thứ tự dựa trên các khóa (key). Clustered index đưojc triển khai theo cấu trúc B-Tree hỗ trợ nhận về dữ liệu hàng, dựa trên các chỉ mục key values |
| Nonclustered | Non-clustered index được xóa trên một bảng hoặc view có dữ liệu trong cấu trúc clustered hoặc trên một heap. Mỗi hàng chỉ mục trong non-clustered index chứa giá trị khóa và một bộ định vị hàng. Bộ định vị trỏ đến hàng dữ liệu trong chỉ mục được nhóm hoặc heap có giá trị của key. Các hàng trong chỉ mục được lưu trữ theo thứ tự của các giá trị khóa chỉ mục, nhưng các hàng dữ liệu không được đảm bảo theo bất kỳ thứ tự cụ thể nào trừ khi một clustered index được tạo trên bảng. |
| Unique | Unique index đảm bảo rằng index key không chứa các giá trị trùng lặp và do đó, mỗi hàng trong bảng hoặc view theo một cách nào đó là duy nhất. Tính duy nhất có thể là thuộc tính của cả clustered và nonclustered index. |
| Columnstore | Index Columnstore lưu trữ và quản lý dữ liệu bằng cách sử dụng lưu trữ dữ liệu dựa trên cột và xử lý truy vấn dựa trên cột trong bộ nhớ trong Index Columnstore hoạt động khi khối lượng công việc lưu trữ dữ liệu chủ yếu thực hiện tải tích hợp và hàng đợi chỉ đọc. Sử dụng index columnstore để đạt được hiệu suất truy vấn lên đến 10 lần so với lưu trữ theo hướng hàng truyền thống và nén dữ liệu lên đến 8x đối với kích thước dữ liệu không nén |
| filtered | Clustered index được tối ưu hóa phù hợp để bao gồm các truy vấn chọn từ một tập hợp con dữ liệu được xác định rõ ràng. Nó sử dụng một vị từ bộ lọc để lập chỉ mục một phần của các hàng trong bảng. Chỉ mục được lọc được thiết kế tốt có thể cải thiện hiệu suất truy vấn, giảm chi phí duy trì chỉ mục và giảm chi phí lưu trữ chỉ mục so với chỉ mục toàn bảng. |
| Spatial | Nó cung cấp khả năng thực hiện một số hoạt động hiệu quả hơn trên các đối tượng không gian trong một cột kiểu dữ liệu hình học. |
| XML | Do kích thước cột XML lớn, các truy vấn tìm kiếm trong các cột này có thể chậm. Bạn có thể tăng tốc các truy vấn này bằng cách tạo một chỉ mục XML trên mỗi cột. Chỉ mục XML có thể là một clusted index hoặc nonclustered index. |
Ngoài ra còn có các kiểu index khác như Hash, Memory optimize nonclustered, index with included column, index on computed column, full text.
SQL Server sử dụng index tương tự với cách một cuốn sách được đánh mục lục. Ví dụ, xét tình huống chúng ta muốn tìm tất cả khóa “INSERT” trong quyển sách học SQL, cách tiếp cận ngay lập tức được thực hiện sẽ là quét từng trang của cuốn sách bắt đầu từ trang bắt đầu, sau đó đánh dấu lại mỗi lần từ “INSERT” được tìm thấy, cho tới cuối quyển sách. Cách tiếp cận này tốn thời gian và công sức. CÁch thứ 2 được sử dụng là sử dụng mục lục của sách và tìm tới trang xuất hiện kết quả nói về INSERT và tìm tới trang đó, sử dụng luôn. Cách só 2 kết quả tương tự cách một nhưng tiết kiệm thời gian công sức hơn.
Khi SQL Server không định nghĩa index, nó sẽ xử lý giống như cách thứ nhất trong ví dụ, SQL engine sẽ phải truy ấn từng bản ghi trong bác, trong thuật ngữ database, hành vi này gọi là called table scan hoặc just scan.
Table scan không phải là không hiệu quả, nhưng trong một số tình huống cụ thể chúng ta chúng ta sẽ cần sử dụng giải pháp khác là dùng index để tăng hiệu năng, vì khi bảng dữ liệu ngày càng lớn với số lượng bản ghi lên đến hàng triệu, scans sẽ chậm và tốn nhiều tài nguyên honw, trong tình huống này, indexes luôn được khuyến khích.
Tổng quan về lưu trữ dữ liệu (data storage)
Một quyển sách chứa các trang, bên trong là các đoạn văn và câu văn, tương tự SQL Server lưu trữ data trong các đơn vị được gọi là data pages ( trang dữ liệu ). Các trang này chứa dữ liệu ở dạng hàng.
Mỗi trang của quyển sách có kích thước vật lý. Tương tự, trong SQL Server tất cả trang dữ liệu có cùng kích thước 8KB. Nghĩa là một database chứa 128 trang dữ liệu trong mỗi megabyte (MB) không gian lưu trữ.
Một trang bắt đầu với 96byte header, lưu trữ thông tin hệ thống về trang, các thông tin này bao gồm:
- Số trang
- Kiểu trang
- Số lượng không gian còn trống trong trang
- ID đơn vị phân bổ của đối tượng cho trang được phân bổ
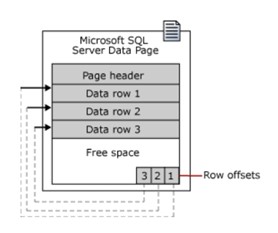
Lưu ý: data page là đơn vị nhỏ nhất của data storage. Một đơn vị phân bổ (allocation unit) là một tập hợp các data pages được nhóm lại cùng nhau dựa trên page type. Việc nhóm lại sẽ giúp hiệu quả hơn cho việc quản trị dữ liệu.
Data files
Tất cả tác vụ nhập và xuất trong database được xử lý trên tầng page. Có nghĩa là database engine đọc hoặc ghi các data pages. Một tập 8 trang nối tiếp nhau được gọi là một extent ( có thể dịch là khu vực).
SQL Server lưu trữ data pages trong các files được gọi là data files. Không gian được phân bổ cho data file được chia thành số lượng các data page sắp xếp tuần tự, các trang bắt đầu chạy từ 0 , biểu diễn hình học như hình dưới
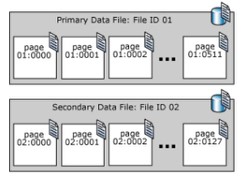
Có 3 loại 3 data files giải thích như sau:
- Primary: file chính được tự động tạo tại thời điểm tạo database, file này có tham chiếu tới tất cả các file còn lại trong database. Đuôi mở rộng được khuyến khích và mặc định cho primary data file là .mdf
- Secondary: là các user-defined data files tùy chọn. Dữ liệu có thể trải rộng trên nhiều ổ đĩa bằng cách đặt mỗi tệp trên một ổ đĩa khác nhau. Đuôi mở rộng được khuyến khích cho secondary data files là .ndf
- Transaction Log: Log files lưu trữ thông tin về các lịch sử sửa đổi trong database. Thông tin này hữu dụng cho việc phục hồi dữ liệu dự phòng như mất điện đột ngột hoặc cần chuyển database sang máy chủ khác. Có ít nhất 1 file log trong mỗi database. Đuôi mở rộng được khuyến khích cho log files là .ldf
Requirement cho indexes
Để tạo điều kiện truy xuất nhanh dữ liệu từ cơ sở dữ liệu, SQL Server cung cấp tính năng index (chỉ mục), tương tự như mục lục quyển sách, index trong SQL Server database chứa thông tin cho phép bạn tìm kiếm data một cách chính xác mà không cần quét (scan) tooàn bộ bảng.

Index
Trong một bảng, các bản ghi được lưu trữ theo thứ tự khi chúng được nhập vào, chúng được lưu trữ trong database mà không được sắp xếp hay theo cách hiểu khác là nó sắp xếp theo lịch sử nhập liệu. Khi dữ liệu được lấy ra từ bảng, toàn bộ bảng sẽ cần được quét, điều này làm chậm tiến trình. Để tăng tốc độ tiến trình, chúng ta thực hiện nghiệp vụ gọi là đánh index.
Khi index được tạo trong bảng, nó sẽ tạo một phiên bản sắp xếp cho cho bản ghi, giúp tăng tốc độ định vị và lấy dữ liệu ra trong quá trình tìm kiếm.
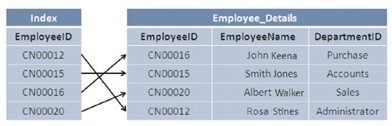
Index sẽ tự động được tạo khi ràng buộc PRIMARY KEY và UNIQUE được định nghĩa trong bảng, index giúp giảm thiểu tác vụ đọc ghi ổ đĩa và tốn ít tài nguyên hệ thống hơn.
Cú pháp:
CREATE INDEX <index_name> ON <table_name> (<column_name>)Index trỏ tới vị trí của bản ghi trong data page thay cho việc tìm kiếm thông qua bảng. Một số đặc tính của index:
- Indexes tăng tốc độ truy vấn nối bảng hoặc xử lý tác vụ sắp xếp.
- Index triển khai tính duy nhất của các hàng nếu được xác định khi bạn tạo chỉ mục.
- Index được tạo và duy trì theo sắp xếp xuôi (ascending) và ngược (descending).
Kịch bản
Xét ví dụ trong một danh bạ điện thoại, sẽ có một lượng lớn dữ liệu được sắp xếp và truy cập thường xuyên, dữ liệu sẽ lưu trữ theo sắp xếp alphabet. Nếu dữ liệu không đưojc sắp xếp, gần như không thể tìm kiếm một số điện thoại cụ thể một cách nhanh chóng.
Tương tự, trong database table có một lượng lớn bản ghi và cần truy vấn thường xuyên, dữ liệu sẽ được sắp xếp để truy vấn nhanh honw. Khi index được tạo cho bảng, chỉ mục sắp xếp vật lý hoặc logic các bản ghi. Vì vậy, việc tìm kiếm bản ghi xác định sẽ trở nên nhannh hơn và giảm tải tài nguyên hệ thống.
Truy cập dữ liệu theo nhóm ( accessing data group-wise)
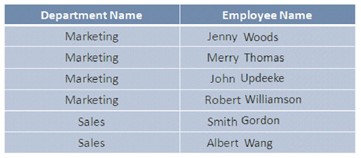
Index hữu dụng khi dữ liệu được truy cập theo nhóm. Ví dụ, bạn muốn tạo một sửa đổi là chuyển đổi phòng ban cho nhóm nhân sự dựa trên phòng ban các nhân sự đang làm việc trong cơ sở dữ liệu. Trong tình huống này có thể tạo một index cho cột DepartmentName trước khi truy cập các bản ghi.
Index này sẽ tạo ra các mảnh dữ liệu logic và nhóm các bản ghi vào theo các phòng ban, sẽ giới hạn số lượng dữ liệu thực sự được quét trong quá trình truy xuất dữ liệu.
Kiến trúc index
Trong SQL Server, dữ liệu trong database có thể được lưu trữ bên theo một cách sắp xếp nhất định hoặc ngẫu nhiên. Nếu dữ liệu được lưu trữ theo cách sắp xếp, dữ liệu được gọi là biểu diễn theo cấu trúc clustered. Nếu dữ liệu được lưu trữ ngẫu nhiên, được gọi là theo cấu trúc heap.
Ảnh minh họa 2 cấu trúc Heap và Clustered:
B-Tree
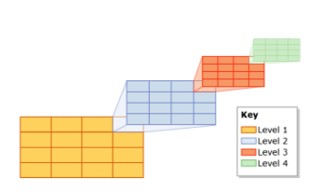
Trong SQL Server, index được tổ chức theo cấu trúc B-Tree, mỗi trang trong một index B-tree được gọi là index node. Node cao nhất được gọi là root node. Note dưới đáy trong index được gọi là là leaf nodes. Bất kỳ tầng nào nằm giữa root node (node gốc) và leaf node (node lá) được gọi là intermediate node (node trung gian).
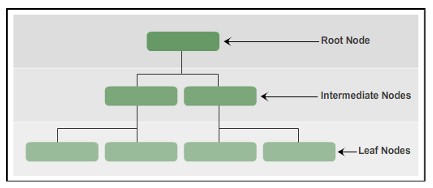
B-Tree index đi từ đỉnh node xuống đáy bằng con trỏ.
Cấu trúc index B-Tree
Trong cấu trúc B-Tree của một index, rooot node bao gồm một index page. Index page chứa con trỏ và trỏ vào index page (trang chỉ mục) biểu diễn ở tầng intermidiate đầu tiên. Các index pages này lần lượt trỏ đến các index page hiện diện ở cấp độ trung gian (intermediate levels) tiếp theo. Có thể có nhiều tầng intermediate trong một index B-Tree. Leaf node trong index B-Tree có trang dữ liệu chứa dữ liệu bản ghi hoặc chứa trang dữ liệu lưu trữ các bản ghi index trỏ tới bản ghi dữ liệu trên bảng.
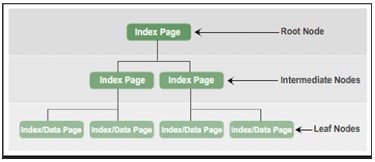
Tóm lại các kiểu nodes trong index B-tree tuân thủ:
- Root Node: chứa một trang index với con trỏ trỏ toiws index pages ở tầng intermediate (trong gian)
- Intermediate Nodes: chứa các trang index với con trỏ trỏ tới index pages ở tầng intermediate hoặc index hoặc data page ở tầng leaf.
- Leaf Nodes: Chứa trang dữ liệu (data pages) hoặc trang index (index pages) trỏ tới data pages.
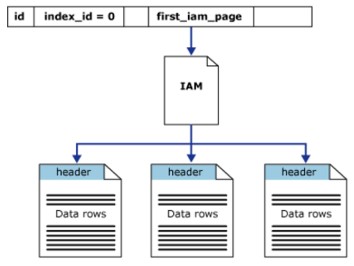
Cấu trúc Heap
Heap là một bảng mà không có clustered index. Điều này có nghĩa là, trong cấu trúc heap, các trang dữ liệu và ban ghi không được sắp xếp . Chỉ có sư liên kết giữa các trang dữ liệu là thông tin được ghi lại trong trang Index Allocation Map (IAM).
Xem thêm về thuật ngữ cấu trúc heap trong cấu trúc dữ liệu: https://vi.wikipedia.org/wiki/%C4%90%E1%BB%91ng_(c%E1%BA%A5u_tr%C3%BAc_d%E1%BB%AF_li%E1%BB%87u)#:~:text=Trong%20khoa%20h%E1%BB%8Dc%20m%C3%A1y%20t%C3%ADnh,%C4%91%C6%B0%E1%BB%A3c%20g%E1%BB%8Di%20l%C3%A0%20max%2Dheap.
Heap có một hàng trong sys.partitions, với index_id = 0 cho mỗi phân vùng sử dụng bởi heap. Mặc định, một heap có một phân vùng/phần (partion) riêng, khi heap có nhiều phân vùng, mỗi phân vùng sẽ có một cấu trúc heap mà chứa dữ liệu được xác định. Ví dụ, heap có 4 phân vùng, sẽ có 4 cấu trúc heap, mỗi cấu trúc trong một phân vùng (partition).
Ở mức tối thiểu, mỗi heap sẽ có một IN_ROW_DATA phân bổ ở mỗi đơn vị partition. Heap cũng có LOB_DATA phân bổ ở mỗi đơn vị partition, nếu nó chứa mội large object (LOB) column. Nó cũng sẽ có một ROW_OVERFLOW_DATA phân bổ mỗi đơn vị partition, nếếu nó chưa cột có độ dài biết thiên, giới hạn kích thước đạt tối đa là 8060 bản ghi
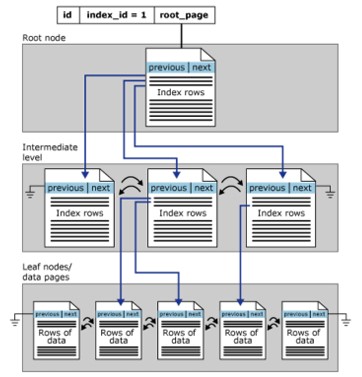
Cấu trúc index Clustered
Clustered index được tổ chức theo dạng B-Tree. Mỗi trang trong index B-Tree được gọi là index node. Tương tự khái niệm, Top node của clustered index cũng là root node và bottom node là leaf node,
- Leaf nodes chứa các trang dữ liệu cơ bản của bảng, tầng root, intermediate chứa các trang index (chỉ mục) nắm giữ index rows (chỉ mục hàng). Mỗi index rơ chứa một giá trị key (khóa) và con trỏ trỏ tới một trang trầng intermediate trong B-tree hoặc data row trong tầng leaf của index.
- Mặc định, một clustered index có một phân vùng đơn (single partition). Khi một clustered index có nhiều phân vùng, mỗi phân vùng sẽ là một cấu trúc B-Tree chứa giá trị của một phân vùng xác định.
- Clustered index cũng có một LOB_DATA phân bổ cho mỗi phân vùng nếu nó chứa bên trong một LOB column (large object). Và nó cũng có một ROW_OVERFLOW_DATA phân bổ trong mỗi phân vùng (partition) đơn.
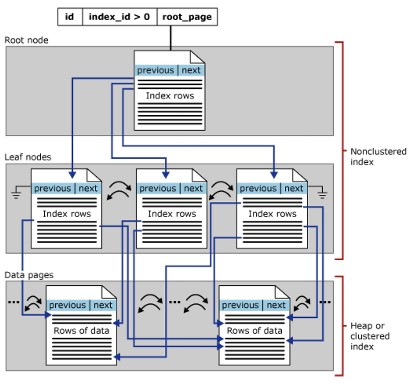
Cấu trúc NonClustered Index
Một nonclustered index có các cấu trúc B-Tree tương tự như clustered index, nhưng có các sự khác biệt sau:
- Các hàng dữ liệu của bảng không được lưu trữ vật lý theo thứ tự được xác định bởi các khóa không phân biệt của chúng.
- Trong cấu trúc nonclustered index, tầng leaf sẽ chứa các index rows (chỉ mục hàng).
- Nonclustered indexes hữu dụng khi bạn cần nhiều cách để tìm kiếm dữ liệu.
- Khi một clustered index được tạo lại hoặc tùy chọn DROP_EXISTING được sử dụng, SQL Server sẽ xây dựng các nonclustered index hiện có,
- Một bảng có thể có tới 888 noneclustered index
- Tạo clustered index trước khi tạo nonclustered index.
Column Store Index (Index lưu trữ cột)
Columnstore index là tính năng của SQL Server nhằm mục đích lưu trữ, lấy ra, quản trị dữ liệu bằng cách sử dụng dữ liệu dạng cột (columnar), đưojwc gọi là columnstore.
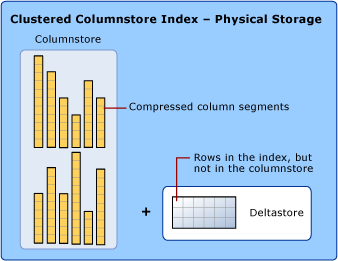
Columnstore index sử dụng 2 kiểu lưu trữ dữ liệu là format rowstore và columnstore.
Columstore index chủ yếu sử dụng vì các lý do:
- Giảm thiếu chi phí lưu trữ
- Cải thiện hiệu năng
Chi tiết về các định dạng columnstore,rowstore,deltastore như sau:
- Columnstore: dữ liệu được tổ chức một cách hợp lý trong bảng với hàng và cột lưu trữ vật lý trong định dạng dữ liệu nhóm cột.
- Rowstore: Dữ liệu được tổ chức hợp lý như một bảng với hàng và cột, sau đó lưu trữ vật lý trong định dạng dữ liệu nhóm hàng.
- Deltastore: Nó nắm giữ vị tri của các hàng khi chúng có quá ít dữ liệu để nén lại thành columnstore. Deltastore lưu trữ các hàng theo định dạng rowstore.
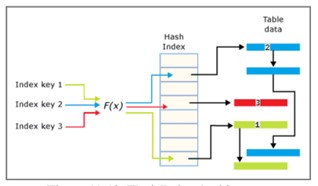
Hash Index
Hash index bao hồm một mảng các còn trỏ và mỗi phần tử trong mảng đưojc gọi là hash bucket.
- Mỗi bucket kích thớc 8 bytes, sử dụng để lưu trữ vị trí vùng nhớ của key trong một cấu trúc link list entry.
- Mỗi entry là một giá trị cho index key, là địa chư tương ứng là hàng trong memory-optimized table.
- Mỗi entry trỏ toiws entry tiếp theo trong một link list entries, tất cả đều có xếp chuỗi ( có thể hiểu giống khóa xích lại với bucket hiện tại)
Số lượng của bucket sẽ phải được xác định vào thời điểm định nghĩa và có một số đặc tính sau:
- Link list ngắn xử lý nhanh hơn link list dài.
- Tốiđa có thể có 1.073.741.824 bucket trong hash index.
XML Index
XML index có thể được tạo cho cột có kiểu dữ liệu XML. Chúng sẽ đánh chỉ mục các thẻ, giá trị, đường dẫn bên trong các XML instance bên trong cột và tăng hiệu năng truy vấn. Ứng dụng của bạn có thể có lợợi thế hơn với XML index trong các trường hợp:
Truy vấn cột XML là phổ biến trong khối lượng công việc. Chi phí tài nguyên duy trì xml chỉ mục trong quá trình thay đổi dữ liệu phải được xem xét.
Khi các giá trị XML tương đối lớn và các phần được truy xuất tương đối nhỏ, xây dựng index giúp tránh phải phân tích cú pháp toàn bộ dữ liệu trong thời gian chạy và có lợi cho việc tra cứu chỉ mục để xử lý truy vấn hiệu quả.
Có 2 loai XML index là:
- Primary XML index
- Secondary XML index
Spartial Index (index không gian)
Trong SQL Server, index không gian sử dụng B-tree, có nghĩa là các index phải được biểu diễn ở 2 chiều không gian trong tuyến tính sắp xếp của B-tree. Vì vậy, trước khi đọc dữ liệu bên trong index không gian, SQL Server triển khai một môn hình phân tầng không gian thống nhất theo thứ bậc. Quá trình tạo chỉ mục phân tách không gian thành một hệ thống phân cấp lưới bốn cấp.
Full-text index
Tạo và duy trì full-text index liên quan đến việc đánh chỉ mục bằng cách sử dụng một quy trình được gọi là tập hợp còn được gọi là thu thập thông tin (crawl).
Các kiểu thu thập thông tin:
- Full population
- Automatic / manual population dựa trên việc theo dõi sự thay đổi
- Incremental population dữ trên timestamp
Create Clustered Index
Câu lệnh CREATE CLUSTERED index cho phép người dùng tạo index CLUSTERED cho cột và bảng xác định.
Cú pháp:
CREATE CLUSTERED INDEX index_name ON table_name (column1,column2,...);Ví dụ:
USE AdventureWorks2019
CREATE TABLE Production.Parts(
part_id INT NOT NULL,
part_name VARCHAR(100)
)
CREATE CLUSTERED INDEX ix_parts_id ON Production.parts (part_id);RENAME INDEX
sp_rename là một system stored procedure cho phép bạn có thể đổi tên bất kỳ object nào mà người dùng đã tạo trong database hiện thời bao gồm table, index, column
Cú pháp:
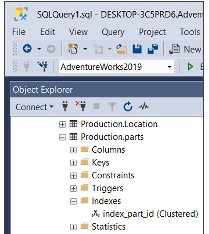
EXEC sp_rename index_name,new_index_name, N'INDEX';Ví dụ:
EXEC sp_rename N'Production.parts.ix_parts_id', N'index_part_id',N'INDEX';Hoặc click chuột phải vào index trên object explorer và chọn tùy chọn rename
DISABLE INDEX
Để disable index, câu lệnh ALTER INDEX được sử dụng.
Cú pháp
ALTER INDEX index_name ON table_name DISABLE;Ví dụ:
ALTER INDEX index_part_id
ON Production.Parts
DISABLE;
select * from Production.PartsSau khi disable index, khi truy vấn dữ liệu sẽ gặp lỗi:
The query processor is unable to produce a plan because the index 'index_part_id' on table or view 'Parts' is disabled.ENABLE INDEX
Để enable index, câu lệnh ALTER INDEX được sử dụng.
Cú pháp:
ALTER INDEX index_name ON table_name REBUILD;Ví dụ:
ALTER INDEX index_part_id ON Production.Parts REBUILD;DROP INDEX
Câu lệnh DROP INDEX sẽ gỏ bỏ index ở database hiện tại.
Cú pháp:
DROP INDEX [IF EXISTS] index_name ON table_name;Ví dụ:
DROP INDEX IF EXISTS index_part_id ON Production.Parts; NonClustered Index
Một noncluster index là một cấấu trúc dữ liệu giúp gia tăng tộc độ lấy dữ liệu từ bảng. Không giống clustered index, nonclustered index sắp xếp và lưu trữ dữ liệu từng phần từ các hàng dữ liệu trong bảng.
Cú pháp:
CREATE [NONCLUSTERED] INDEX index_name ON table_name(column1,column2,...);Ví dụ:
CREATE NONCLUSTERED INDEX index_customer_storeid ON Sales.Customer(StoreID);Unique Index
Unique index đảm bảo các cột indexkey không chứa các giá trị trùng lặp.
Nó có thể chứa một hoặc nhiều cột, nếu unique index có một cột, giá trị của cột sẽ là duy nhât, trong trường hợp unique index có nhiều cột, sự kết hợp các giá trị các cột này là duy nhất.
Lưu ý: unique index có thể là clustered hoặc non-clustered.
Cú pháp tạo unique index:
CREATE UNIQUE INDEX index_name ON table_name(column_list);Ví dụ:
CREATE UNIQUE INDEX AK_Customer_rowguid ON Sales.Customer(rowguid);Filtered Index
Filtered index là một nonclustered index cho phép bạn xác định row nào được thêm vào index.
Cú pháp:
CREATE INDEX index_name ON table_name(column_list) WHERE predicate;Ví dụ:
CREATE INDEX index_cust_personID
ON sales.Customer(PersonID)
WHERE PersonID IS NOT NULL;Partitioned Table and indexes
SQL Server hỗ trợ 2 kiểu table và index partition (phân vùng). Dữ liệu của một bảng đã phân vùng và index được chia thành cách đơn vị có thể tùy chọn có thể tùy ý trải rộng trên nhiều nhóm tệp trong cơ sở dữ liệu. Dữ liệu được phân vùng theo hàng ngang, vì vậy sẽ nhóm các hàng được map (kết nối) vào một phân vùng riêng biêt.Tất cả phân vùng của một bảng đơn hoặc index phải ở cùng trên một database. Bảng hoặc index được coi như một đối tượng khi truy vấn hoặc cập nhật dữ liệu.
SQL Seerver 2019 mặc định hỗ trợ lên tới 15.000 phân vùng.
Lợi ích của phân vùng:
- Chuyển đổi hoặc truy vấn dữ liệu nhanh và hiệu quả.
- Xử lý các tác vụ duy trì trên một hoặc nhiều phân vùng, các tác vụ sẽ hiệu quả hơn vì mục tiêu của chúng chỉ trên tập dữ liệu trên phân vùng, thay vì toàn bộ bảng.
- Tăng hiệu năng truy vấn, dữ trên kiểu truy vấn bạn thường xuyên chạy và cấu hình phần cứng.
Ví dụ tạo một bảng mẫu với thông tin sau:
CREATE TABLE testing_table(receipt_id BIGINT, date DATE)Xác định chính xác bảng sẽ được phân vùng như thế nào, trong tình huống này, cột date, cùng với
khoảng giá trị sẽ được thêm vào trong mỗi phân vùng. Về ranh giới phân vùng, bạn có thể chỉ định LEFT hoặc RIGHT (phía trái hoặc phải)
CREATE PARTITION FUNCTION partition_function (int) AS RANGE LEFT FOR VALUES (20200630,20200731,20200831);Có nghĩa là chia ra 4 phân vùng như sau:
- Phân vùng 1: tất cả bản ghi với date <= 2020-06-30
- Phân vùng 2: tất cả bản ghi với date > 2020-06-30 và date <= 2020-07-31
- Phân vùng 3: tất cả bản ghi với date > 2020-07-31 và date <= 2020-08-31
- Phân vùng 4: tất cả bản ghi với date > 2020-08-31
Đoạn code phía dưới sẽ cho phép bạn nhận diện phana vùng mỗi bản ghi được đặt vào
(SELECT 20200613 date, $PARTITION.partition_function(2020613) AS PartitionNumber)
UNION
(SELECT 20200713 date, $PARTITION.partition_function(2020713) AS PartitionNumber)
UNION
(SELECT 20200813 date, $PARTITION.partition_function(20200813) AS PartitionNumber)
UNION
(SELECT 20200913 date, $PARTITION.partition_function(20200913) AS PartitionNumber)
XML Index
Dữ liệu XML được lưu trữ trong kiểu cột có kiểu dữ liệu XML là một kiểu dữ liệu tốn nhiều kích thước, gọi là Large binary object (BLOBs)
Để biểu diễn dữ liệu xml, kích thước kiểu dữ liệu có thể lên tới 2GB.
XML index được tạo trên cột chứa dữ liệu xml và lưu trữ trong bảng và database.
Ví dụ:
CREATE PRIMARY XML INDEX PXML_PRoduct_Model_Catalog_Description ON Production.ProductModel (CatalogDescription);Primary XML index chứa toàn bộ dữ liệu trong cột XML. Để cung cấp thêm hiệu năng cho câu truy vấn XML, bạn có thể thêm các index secondary.Secondary XML index cũng sử dụng cùng một tập dữ liệu vì nó là chỉ mục chính cơ bản, nhưng nó tạo ra một chỉ mục cụ thể hơn, dựa trên chỉ mục chính.
Ví dụ:
CREATE XML INDEX IXML_ProductModel_CatalogDescription_Path
ON Production.ProductModel (CatalogDescription)
USING XML INDEX PXML_ProductModel_CatalogDescription
FOR PATH;Columnstore Index
Cú pháp:
CREATE COLUMNSTORE INDEX
IX_SalesOrderDetail_ProductIDOrderQty_ColumnStore
ON Sales.SalesOrderDetail (ProductID,OrderQty);Việc tạo index này sẽ cải thiện truy vấn group by khi sử dụng các hàm tổng hợp.
SELECT ProductID,SUM(OrderQty)
FROM Sales.SalesOrderDetail
GROUP BY ProductId;
Bài tập
Bài 1:
Houseton State Library là một thư viện giả định tại Houston, Texas. Thư viện có khoảng trên 1.000.000
quyển sách với các thể lo khác nhau. Thư viện cung cấp sách cho sinh viên đại học xung quanh đó. Khi sinh viên nhiều hơn, thư viện quyết định tự đg hóa toàn bộ quy trình phát hành sách cho sinh viên.
Thư viện đã tăng số lượng sách lên 10 bản copy, dựa theo nhu cầu sinh viên.
Dựa vào thông tin trên, làm các yêu cầu sau:
a. Tạo database có tên HoustonStateLibrary
b. Tạo bảng có tên BooksMaster để lưu trữ chi tiết sách trong thư viện như sau:
| Field Name | Data Type | Key Field | Description |
| BookCode | varchar(50) | Primary key | Mã sách |
| Title | varchar(max) | Tiêu đề sách | |
| ISBN | varchar(50) | ISBN | |
| Author | varchar(40) | Tác giả | |
| Price | money | Giá sách | |
| Publisher | char(30) | Nhà xuất bản | |
| NumPages | numberic(10,0) | Số trang |
c. Tạo một clustered index tên là IX_Title trên cột Title của bảng BooksMaster.
d. Tạo bảng BookMaster1 có trường BookCode,Title,BookDetails
e. Xác định kiểu dữ liệu bookDetails là XML. Tạo một tài liệu XML với chi tiết ISBN,Author,Price,Publisher,NumPages.
f. Tạo primary XML index PXML_BBooks trên cột BookCode của bảng BooksMaster.
Bài 2:
Dựa vào bài tập: https://hocvietcode.com/constraint-rang-buoc-table-strong-sql-server/#content_baitap
Tạo một nonclustered index cho bảng student cho cột StudentName, đặt tên là ncix_Student_StudentName
Bài 3:
Dựa vào bài tập số 1 của link: https://hocvietcode.com/cau-lenh-select-nang-cao-ket-hop-cung-cac-ham-tong-hop-du-lieu/#content_baitap
Tạo một clusteredindex có tên [CI_NhaTrenPho_NhaID] trên cột [NhaID] trên bảg NhaTrenPho
Tạo mộ unique non-clustered index có tên [UI_QuanHuyen_TenQH] trên cột [TenQH] của bảng QuanHuyen
Bài 4:
1. Tạo một file có tên: Lab6.sql
2. Tạo một Cơ sở dữ liệu có Lab6.
3. Tạo ba bảng và chèn dữ liệu như sau:
Students (chứa danh sách Sinh viên).
|
StudentID (int) |
Name (VarChar(50)) |
Age (tinyint) |
stGender (bit) |
|---|---|---|---|
|
1 |
Joe Hart |
25 |
1 |
|
2 |
Colin Doyle |
20 |
1 |
|
3 |
Paul Robinson |
16 |
Null |
|
4 |
Luis Garcia Paulson |
17 |
0 |
|
5 |
Ben Foster |
30 |
1 |
Projects (chứa danh sách dự án).
|
PID(int) |
PName (Varchar (50)) |
Cost (float) |
Type (Varchar(10)) |
|---|---|---|---|
|
1 |
NewYork Bridge |
100 |
Null |
|
2 |
Tenda Road |
60 |
Null |
|
3 |
Google Road |
200 |
Null |
|
4 |
The Star Bridge |
50 |
Null |
StudentProject (chứa danh sách Sinh viên làm việc cho các Dự án). Ví dụ: hàng đầu tiên của bảng dưới đây thể hiện rằng ‘Joe Hart’ (có mã 1 ở bảng Students) làm việc cho dự án ‘The Star Bridge’ (có mã là 4 ở bảng Projects) từ ngày ‘15/05/09’ và làm việc trong 3 tháng.
|
StudentID (int) |
PID (int) |
WorkDate (date) |
Duration (int) |
|---|---|---|---|
|
1 |
4 |
15/05/09 |
3 |
|
2 |
2 |
14/05/09 |
5 |
|
2 |
3 |
20/05/09 |
6 |
|
2 |
1 |
16/05/09 |
4 |
|
3 |
1 |
16/05/09 |
6 |
|
3 |
4 |
19/05/09 |
7 |
|
4 |
4 |
21/05/09 |
8 |
4. Các ràng buộc cần tạo:
a. Ràng buộc Check trên cột Age của bảng Students để kiểm tra độ tuổi nhập vào phải nằm trong khoảng (Age > 15 và Age < 33).
b. Ràng buộc khóa chính trên các cột: StudentID của bảng Students, PID của bảng Projects, (StudentID,PID) của bảng StudentProject.
c. Ràng buộc Default trên cột Duration của bảng StudentProject với giá trị mặc định là 0.
d. Ràng buộc khóa ngoại trên các cột: StudentID của bảng StudentProject tham chiếu đến bảng Students, PID của bảng StudentProject tham chiếu đến bảng Projects.
5. Cập nhật giá trị trên cột Type của bảng Projects như sau:
- Type=’Education’ nếu Cost < 80.
- Type=’Normal’ nếu Cost >= 80 và Cost <= 150.
- Type=’Government’ nếu Cost > 150.
6. Hiển thị những Sinh viên làm việc cho hơn một Dự án.
7. Hiển thị những Sinh viên có tổng số thời gian làm việc cho các dự án là lớn nhất (gợi ý: dựa vào cột Duration).
8. Hiển thị những Sinh viên có tên chứa cụm từ ‘Paul’ làm việc cho Dự án ‘The Star Bridge’.
9. Hiển thị những Sinh viên không làm việc cho dự án nào.
10. Tạo View có tên ‘vwStudentProject’ để hiển thị thông tin như sau (lưu ý phải sắp xếp dữ liệu tăng dần theo tên sinh viên): Tên sinh viên, tên dự án, workdate và duration.
11.Tạo Index có tên ‘ixStudentName’ trên hai cột [Student Name] và [Project Name] của View ‘vwStudentProject’.
12. Tạo thủ tục lưu trữ có tên ‘spWorkin’ có một tham số, tham số này nhận vào tên của Sinh viên.
- Nếu tên này có trong bảng Students thì hiển thị thông tin về Sinh viên tương ứng và những Dự án mà Sinh viên đó đã làm việc.
- Nếu tham số nhận vào chuỗi ‘any’ thì hiển thị tên của tất cả các Sinh viên cùng những Dự án mà họ đã làm.
13. Tạo Trigger có tên ‘tgUpdateTrig’ trên bảng Students, trigger này có nhiệm vụ như sau: nếu sửa giá trị trên cột StudentID của bảng Students thì giá trị tương ứng trên cột StudentID của bảng StudentProject củng phải được sửa theo.
14. Tạo thủ tục lưu trữ có tên ‘spDropOut’ có một tham số, tham số này nhận vào tên của Dự án. Nếu tên này có trong bảng Projects thì sẽ xóa tất cả thông tin liên quan đến dự án đó trong tất cả các bảng liên quan của Cơ sở dữ liệu.
Bài 5:
1. Tạo một file có tên dạng: Họ_và_tên_Lab7.sql, ví dụ: DangTranLongLab7.sql.
2. Tạo một Cơ sở dữ liệu tên trùng với tên file, ví dụ: DangTranLongLab7.
3. Tạo ba bảng và chèn dữ liệu như sau:
Customer (lưu trữ Khách hàng)
|
CustomerID (int) |
Name (varchar (30)) |
Birth (date) |
Gender (bit) |
|---|---|---|---|
|
1 |
Jonny Owen |
10/10/1980 |
1 |
|
2 |
Christina Tiny |
10/03/1989 |
0 |
|
3 |
Garry Kelley |
16/03/1990 |
Null |
|
4 |
Tammy Beckham |
17/05/1980 |
0 |
|
5 |
David Phantom |
30/12/1987 |
1 |
Product (Lưu trữ Sản phẩm)
|
ProductID (int) |
Name (varchar (30)) |
Pdesc (text) |
Pimage (varchar(200)) |
PStatus (bit) |
|---|---|---|---|---|
|
1 |
Nokia N90 |
Mobile Nokia |
image1.jpg |
1 |
|
2 |
HP DV6000 |
Laptop |
image2.jpg |
NULL |
|
3 |
HP DV2000 |
Laptop |
image3.jpg |
1 |
|
4 |
SamSung G488 |
Mobile SamSung |
image4.jpg |
0 |
|
5 |
LCD Plasma |
TV LCD |
image5.jpg |
0 |
Comment (lưu trữ bình luận của Khách đối với Sản phẩm). Ví dụ: bản ghi đầu tiên của bảng dưới thể hiện rằng ‘Jonny Owen’ (mã là 1 ở bảng Customer) đã bình luận cho sản phẩm ‘Nokia N90’ (mã là 1 ở bảng Product) vào ngày ‘15/03/09’).
|
ComID(int identity(1,1)) |
ProductID (int) |
CustomerID (int) |
Date (datetime) |
Title (varchar(200) |
Content (text) |
Status (bit) |
|---|---|---|---|---|---|---|
|
1 |
1 |
1 |
15/03/09 |
Hot product |
null |
1 |
|
2 |
2 |
2 |
14/03/09 |
Hot price |
Very much |
0 |
|
3 |
3 |
2 |
20/03/09 |
Cheapest |
Unlimited |
0 |
|
4 |
4 |
2 |
16/04/09 |
Sale off |
50% |
1 |
Các ràng buộc phải tạo:
- Ràng buộc Default cho cột Date của bảng Comment với giá trị mặc định là ngày hiện tại.
- Ràng buộc khóa chính trên cột: CustomerID của bảng Customer, ProductID của bảng Product và ComID của bảng Comment.
- Ràng buộc khóa ngoại trên cột: ProductID của bảng Comment tham chiếu đến bảng Product và CustomerID cũng của bảng Comment tham chiếu đến bảng Customer.
- Ràng buộc Unique cho cột Pimage trên bảng Product.
4. Hiển thị những sản phẩm có PStatus là null hoặc 0.
5. Hiển thị những sản phẩm không có bình luận nào.
6. Hiển thị những Khách có nhiều bình luận nhất.
7. Tạo View có tên ‘vwFull_Information’ để xem tất cả các bình luận gồm các cột sau:
Mã bình luận, tên Khách, tên Sản phẩm, ngày bình luận, tiêu đề bình luận, nội dung bình luận và trạng thái bình luận, trong đó trạng thái bình luận hiển thị là ‘Accept’ thay cho 1 và ‘Not Accept’ thay cho 0.
8. Tạo View có tên ‘vwCustomerList’ để liệt kê thông tin của tất cả các Khách hàng gồm tất cả các cột của bảng Customer và cột Status, trong đó cột Gender hiển thị là ‘Male’ thay cho 1, ‘Female’ thay cho 0 và ‘Unknow’ thay cho Null, cột Status hiển thị là ‘Old’ nếu tuổi của khách>=30 và ‘Young’ nếu tuổi của khách<30.
9. Sửa View ‘vwCustomerList’ để nó chỉ chứa các cột CustomerID, Customer Name, Birth, Gender của bảng Customer và tạo chỉ mục (index) có tên ixCustomerName trên cột [Customer Name] của view này.
10. Tạo thủ tục lưu trữ có tên ‘spStudent’ có một tham số tên @Name.
- Nếu tìm thấy @Name trong cột Name của bảng Product thì sẽ liệt kê tất cả những bình luận cho những Sản phẩm có tên tương tự (like) @Name.
- Nếu không thì kiểm tra @Name nếu tìm thấy trong Name của bảng Customer thì sẽ liệt kệ tất cả những bình luận của những Khách có tên tương tự (like) @Name
- Còn nếu @Name nhận giá trị ‘*’ thì sẽ liệt kê tất cả các bình luận đang có.
11. Tạo Trigger có tên ‘tgUpdateProduct’ trên bảng Product để khi cập nhật giá trị trên cột ProductID của bảng Product thì trigger sẽ tự cập nhật giá trị tương ứng lên trên cột ProductID của bảng Comment.
12. Tạo thủ tục lưu trữ có tên ‘spDropOut’ có một tham số là tên của Khách hàng, nếu tìm thấy tên này trong cột Name của bảng Customer thì sẽ xóa tất cả những thông tin của tất cả những Khách hàng có tên tương ứng đó trên tất cả các bảng liên quan của Cơ sở dữ liệu.
Bài viết liên quan:
Dịch vụ thiết kế Wesbite



