Các tính năng nâng cao SQL trong SQL Server 2019
Mục lục
Chi tiết cảnh báo truncate (Verbose Truncation Warnings)
Đây là một trong những tính năng nâng cao mới trong SQL Server 2019 cung cấp. Nó tiết kiệm thời gian khi báo cáo, thêm mới, cập nhật một lượng lớn dữ liệu.
Ví dụ:
Bước 1 – tạo Sample DB 2017
USE [master]
GO
CREATE DATABASE [SampleDB2017]
GO
ALTER DATABASE [SampleDB2017]
SET COMPATIBILITY_LEVEL = 140
GOBước 2 – thêm bảng một vài bản ghi vào database trên
USE [SampleDB2017]
GO
CREATE TABLE [dbo].[tbl_Color](
[ColorID] int IDENTITY not null,
[ColorName] varchar(3) NULL
)
GO
INSERT INTO dbo.tbl_Color (ColorName) values ('Red'), ('Blue'),('Green')
GOVới các phiên bản cũ, lỗi sẽ trả ra như sau:
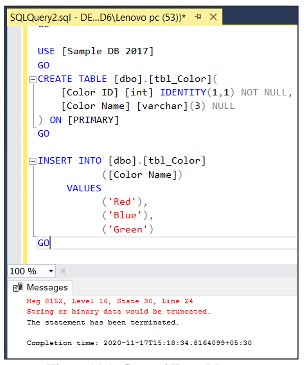
Lỗi xảy ra khi bản ghi ‘Green’ đưa vào cột có dữ liệu nvarchar(3) dù lỗi đã thể hiện, nhưng nếu số lượng bản ghi nhều, chúng ta sẽ khó xác định lỗi bắt gặp khi insert bản ghi nào, ở phiên bản 2019, thông báo lỗi được fix và thể hiện chi tiết hơn, giúp dễ dàng nhận diện lỗi.
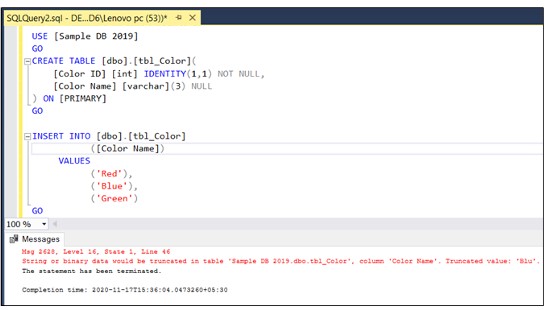
Đánh giá lỗ hổng (Vulnerability Assessment)
Đây là một nghiệp vụ dễ dàng cấu hình (easy-to-configure) giúp khám phá, theo dõi đảo ngược hoặc giảm các lỗ hổng cơ sở dữ liệu.
Database admin có thể sử dụng nó để chủ động phát triển bảo mật cho database.
Vulnerability Assement là một phần của Azure Defenđẻ cho SQL, là một gói hợp nhất cho các khả năng bảo mật SQL nâng cao. Nó có thể được truy cập và quản trị thông qua Azure Defender cho cổng thông tin SQL.
Lưu ý SQL vulnerability sử dụng trong Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics (SQL Data Warehouse).
SQL Vulnerability Assement bao gồm các bước thao tác để nâng cao bảo mật cho database, có thể giúp bạn:
- Đáp ứng các yêu cầu tuân thủ yêu cầu báo cáo quét cơ sở dữ liệu
- Đáp ứng các tiêu chuẩn về quyền riêng tư của dữ liệu
- Giám sát môi trường cơ sở dữ liệu động nơi khó theo dõi các thay đổi
Các quy tắc dựa trên các phương pháp hay nhất của Microsoft và tập trung vào các vấn đề bảo mật rủi ro lớn nhất cho cơ sở dữ liệu của bạn và dữ liệu có giá trị của nó. Kết quả của việc quét bao gồm những bước có thể thao tác để giải quyết mỗi vấn đề và cung cấp các kịch bản sửa chữa tùy chỉnh có thể áp dụng.
Bạn có thể tùy chrinh một báo cáo lỗ hổng cho môi trường bằng cách cài đặt đường cơ sở (baseline) cho:
- Cấu hình quyền
- Cấu hình tính năng
- Cài đặt database
Các bước triển khai vulnerability assessment:
Chạy scan
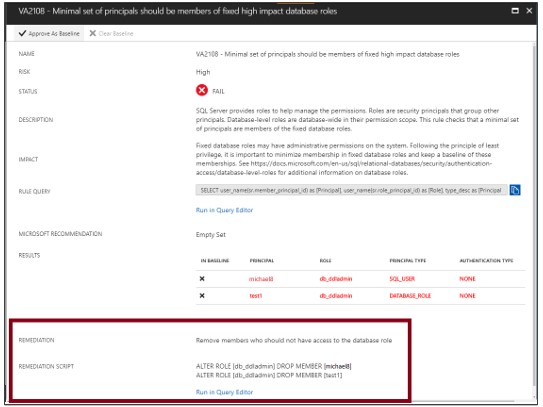
Lưu ý: quá trình chạy scan nhẹ và an toàn, chỉ mất vài giây và read-only toàn bộ quá trình scan, sẽ không có sự thay đổi nào trong database của bạn.
Xem báo cáo
Khi quá trình scan kết thúc, báo cáo sẽ tự động hiển thị trên Azure portal
Kết quả bao gồm các cảnh báo về sự sai lệch so với các phương pháp hay nhất và ảnh chụp nhanh các cài đặt liên quan đến bảo mật của bạn, chẳng hạn như các nguyên tắc và vai trò của cơ sở dữ liệu cũng như quyền liên quan của chúng.
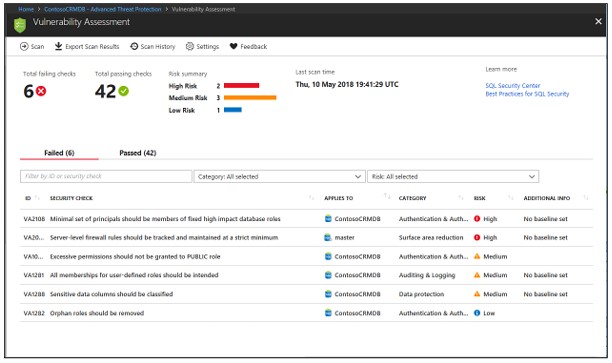
Phân tích kết quả và giải quyết vấn đề
Kiểm tra lại kết quả và nhận diện trong báo cáo xem có bất kỳ vấn đề nào trong môi trường của bạn không.
Đi sâu vào từng kết quả không thành công để hiểu tác động của phát hiện và lý do tại sao mỗi lần kiểm tra bảo mật không thành công.
Sử dụng thông tin khắc phục có thể hành động được cung cấp bởi báo cáo để giải quyết vấn đề.
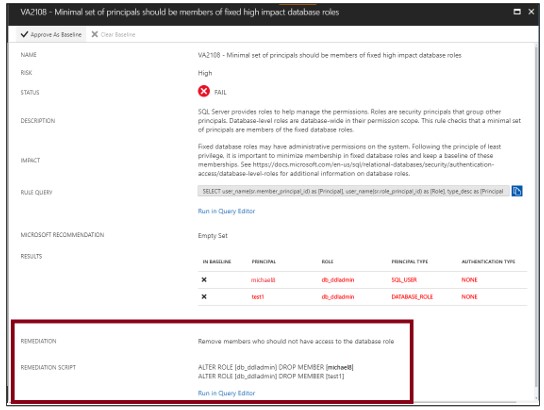
Đặt đường cơ sở (set baseline)
Khi xem xét kết quả đánh giá của mình, bạn có thể đánh dấu các kết quả cụ thể là đường cơ sở có thể chấp nhận được. Kết quả phù hợp với đường cơ sở được coi là vượt qua trong các lần quét tiếp theo. Sau khi bạn đã thiết lập trạng thái bảo mật cơ sở của mình, đánh giá lỗ hổng chỉ báo cáo về những sai lệch so với đường cơ sở.
Kết quả phù hợp với đường cơ sở được coi là vượt qua trong các lần quét tiếp theo. Sau khi bạn đã thiết lập ngày bảo mật cơ sở của mình, đánh giá lỗ hổng chỉ báo cáo về những sai lệch so với đường cơ sở.
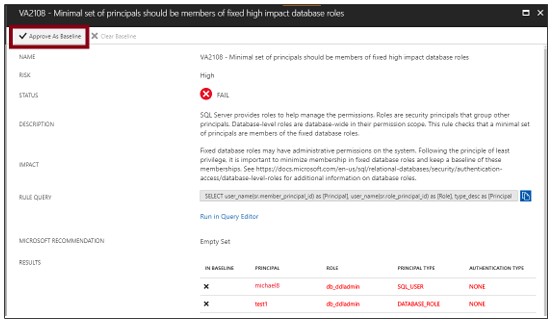
Chạy một bản quét mới để xem báo cáo theo dõi tùy chỉnh của bạn.
Sau khi cài đặt Rule Baselines, chạy một lần quét để xem các báo cáo tùy crinh, vulnerability assessment sẽ báo cáo chỉ những vấn đề về bảo mật lệch khỏi trạng thái cơ bản đã được phê duyệt của bạn.
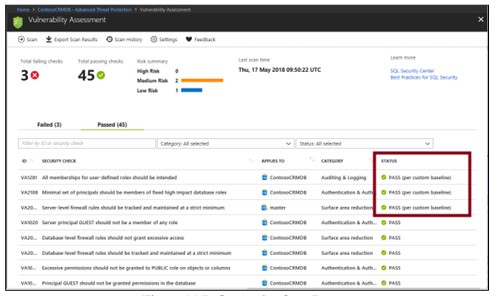
Big Data Clusters
Trong SQL Server 2019 Big Data Cluster cho phép triển khai các cụm có thể mở rộng SQL Server, Spark và Hệ thống tệp phân tán Hadoop (HDFS)…
Big Data Cluster sử dụng chủ yếu để:
- Triển khai các cụm vùng chứa SQL Server, Spark và HDFS có thể mở rộng chạy trên Kubernetes.
- Đọc, ghi , xử lý big data từ T-SQL hoặc Spark SQL.
- Dễ dàng kết hợp và phân tích các dữ liệu quan hệ giá trị lớn cùng big data giá trị lớn.
- Truy vấn nguồn dữ liệu bên ngoài.
- Lưu trữ big data trong HDFS quản lý bởi SQL Server.
- Truy vấn dữ liệu từ nhiều nguồn dữ liệu bên ngoài thông qua cluster.
- Sử dụng dữ liệu cho AI, ML hoặc các tác vụ phân tích khác.
- Triển khai và chạy các ứng dụng trong Big Data Cluster, ảo hóa dữ liệu với PolyBase.
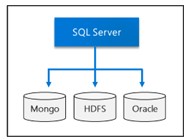
- Truy vấn dữ liệu từ các nguồn dữ liệu SQL Server, Oracle Teradata, MongoDB, ODBC bên ngoài với các bảng bên ngoài.
- Cung cấp tính khả dụng cao cho phiên bản chính của SQL Server và tất cả cơ sở dữ liệu bằng cách sử dụng nhóm công nghệ Always On availability.
Data Virtualization (ảo hóa dữ liệu)
SQL Server Big Data Clusters có thể truy vấn nguồn dữu liệu bên ngoài mà không cần dịch chuyển hoặc copy dữ liệu.
Data Lake
Data Lake là một kho vùng chứa, chứa một lượng lớn dữ liệu thô với định dạng gốc.
Nó là một HDFS storate pool có thể mở rộng.
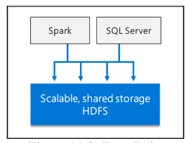
Scale-out data mart
Cung cấp khả năng tính toán và lưu trữ theo quy mô để cải thiện hiệu suất phân tích bất kỳ dữ liệu nào.
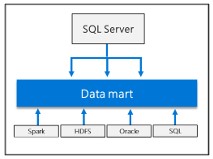
Tích hợp AI và Machine Learning
Cho phép thực thi các tác vụ AI và machine learning với dữ liệu lưu trữ trong HDFS storage pools và data pools.
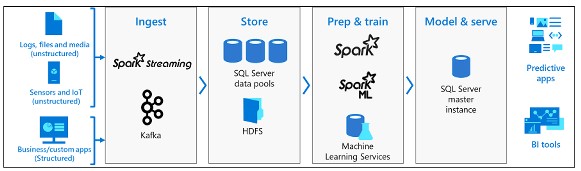
Cụm dữ liệu lớn (big data cluster) SQL Server là một cụm các vùng chứa Linux do nền tảng Kubernetes tổ chức.
Thuật ngữ Kubernetes
Kubernetes là một open source điều phối vùng chứa, có thể mở rộng quy mô triển khai vùng chứa theo nhu cầu. Một số thuật ngữ quan trọng của Kubernetes:
| Thuật ngữ | Mô tả |
| Cluster | Kubernetes cluster là một tập hợp các máy móc, hiểu là nodes, một node kiểm soát cluster và chỉ định là master node, các nodes còn lại là worker nodes. Kubernetes master chịu trách nhiệm phân phối công việc giữa các workers và theo dõi sức khỏe của cluster. |
| Node | Một nút chạy ứng dụng được chứa trong vùng chứa. Nó có thể là máy vật lý hoặc máy ảo. Kubernetes cluster có thể chứa cả các node máy vật lý và máy ảo. |
| Pod | Pod là đơn vị triển khai nguyên tử của Kubernetes. Nhóm là nhóm logic của một hoặc nhiều vùng chứa và các tài nguyên liên quan bắt buộc |
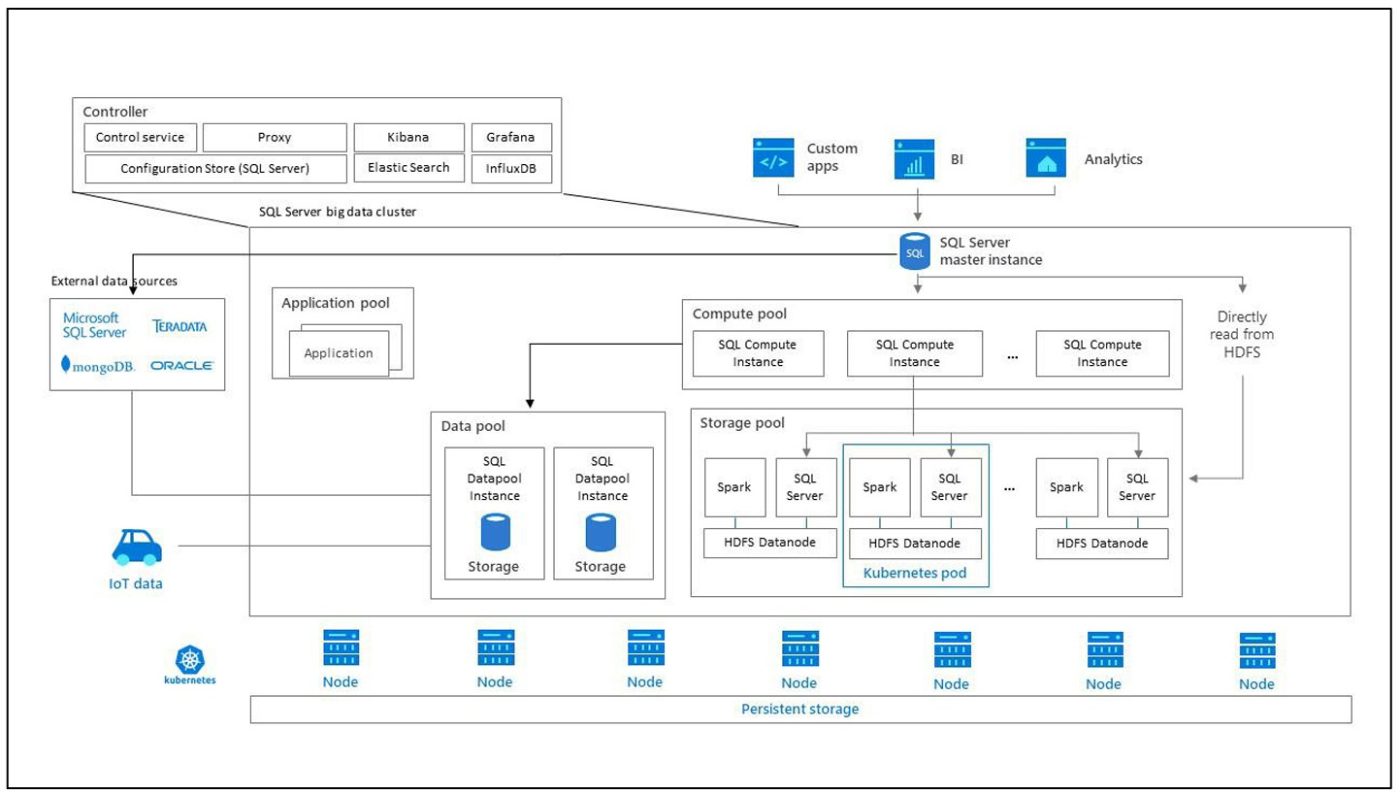
Controller
Controller cung cấp khả năng quản trị và bảo mật cho cluster. Nó bao gồm nghiệp vụ điều khiển, lưu cấu hình, và các nghiệp vụ tầng cluster như Kibana, Grafana, Elastic Search.
Compute pool
Compute pool cung cấp tài nguyên tính toán cho cluster. Nó bao gồm các node SQL Server đang chạy trên Linux pods. Pods trong computed pool được chia thành các SQL Compute instances cho các nghiệp vụ xử lý xác định.
Data Pool
Data pool được sử dụng cho việc duy trì dữ liệu bền vững và caching (bộ nhớ đệm). Data pool chứa một hoặc nhiều pods chạy SQL Server trên Linux. Nó sử dụng để lấy dữ liệu từ truy vấn SQL hoặc Spark. SQL Server big data cluster data marts giữ được tính bền vững trong data pool.
Storage Pool
Storage pool bao gồm các storage pool pods bao gồm SQL Server trên Linux, Spark và HDFS. Tất cả storage nodes trong SQL Server bigdata cluster là thành viên của HDFS cluster.
Bài tập
Bà tập ôn luyện 1
I. Tạo một Cơ sở dữ liệu có tên 'BookStore'.
II. Tạo 4 bảng và chèn dữ liệu như sau:
Bảng Students:
|
StudentID (int, primary key, identity) |
Name (VarChar (50)) |
Age (tinyint) |
stGender (bit) |
|---|---|---|---|
|
1 |
Henry |
25 |
1 |
|
2 |
Britney |
20 |
0 |
|
3 |
Beckham |
16 |
Null |
|
4 |
Madona |
17 |
0 |
|
5 |
Effenberg |
30 |
1 |
Bảng Books:
|
BookID (int, primary key, identity) |
Name (Varchar (50)) |
TotalPage (int) |
Type (Varchar(10)) |
Quantity (int) |
|---|---|---|---|---|
|
1 |
Access 2K |
100 |
Null |
3 |
|
2 |
Logic C |
60 |
Null |
4 |
|
3 |
HTML |
200 |
Null |
2 |
|
4 |
Core Java |
50 |
Null |
1 |
|
5 |
SQL 2K |
1000 |
Null |
6 |
Bảng Borrows:
|
BorrowID (int) |
StudentID (int) |
BookID (int) |
BorrowDate (datetime) |
|---|---|---|---|
|
1 |
1 |
5 |
15/09/07 |
|
2 |
2 |
2 |
14/09/07 |
|
3 |
2 |
3 |
20/09/07 |
|
4 |
2 |
1 |
16/09/07 |
|
5 |
2 |
1 |
16/09/07 |
|
6 |
3 |
4 |
19/09/07 |
|
7 |
4 |
4 |
21/09/07 |
Bảng ReturnBooks:
|
ReturnID (int) |
StudentID (int) |
BookID (int) |
BorrowDate (datetime) |
ReturnDate (datetime) |
|---|---|---|---|---|
|
|
|
|
|
|
Các ràng buộc:
a. Ràng buộc Check cho cột TotalPage của bảng Books với yêu cầu TotalPage phải lớn hơn 0.
b. Ràng buộc khóa chính cho các cột StrudentID, BookID, BorrowID và ReturnID của các bảng tương ứng.
c. Ràng buộc Indetity(1,1) cho cột ReturnID của bảng ReturnBooks.
Các yêu cầu truy vấn:
- Cập nhật trường Type trong bảng Books theo tiêu chí:
- Type='Thin' nếu TotalPage < 100
- Type='Normal' nếu TotalPage nằm trong đoạn 100 đến 1000
- Type='Thick' nếu TotalPage > 1000
- Hiển thị danh sách sinh viên (danh sách này phải sắp xếp theo trường Age).
- Hiển thị tên của sinh viên nhiều tuổi nhất.
- Hiển thị tổng số sách trong kho.
- Hiển thị tên của những sinh viên có stGender là Null.
- Hiển thị tên của những sinh viên có ký tự đầu tiên là 'B'.
- Hiển thị bookID, borrowDate của những quyển sách được mượn hơn 10 ngày tính đến thời điểm hiện tại.
- Hiển thị ½ tổng số sách.
- Viết câu lệnh SQL mô tả hành động: quyển sách 'Access 2K' được trả bởi 'Britney'.
- Viết câu lệnh SQL mô tả hành động: quyển sách 'SQL2K' được trả bởi 'Henry'.
- Viết câu lệnh SQL mô tả hành động: Madona mượn quyển sách 'SQL2K' vào ngày 28/01/2016.
- Viết câu lệnh SQL mô tả hành động: Madona trả quyển sách 'SQL2K' vào ngày 28/03/2016.
- Hiển thị bookID, borrowDate của những quyển sách được mượn hơn 10 ngày tính từ lúc mượn đến lúc trả.
- Tạo Unique Index trên cột Name của bảng Books.
- Tạo một View chứa các thông tin mã sinh viên, tên sinh viên, mã sách, tên sách, ngày mượn, với điều kiện ngày mượn sách phải >= 15/09/07
- Tạo một thủ tục lưu trữ để tìm và hiển thị những cuốn sách được mượn. Thủ tục lưu trữ có một tham số đầu vào là tên của cuốn sách.
- Tạo một trigger để khi xóa một cuốn sách thì những thông tin liên quan đến cuốn sách đó trong bảng Borrows và ReturnBooks cũng được xóa.
Bài tập ôn luyện 2
CSDL BANHANG lưu trữ thông tin về quản lý bán hàng tại siêu thị Bình Minh ở Hà Nội gồm 6 bảng có cấu trúc như sau:
 Dữ liệu mẫu trong bảng NhaCungCap:
Dữ liệu mẫu trong bảng NhaCungCap:

Dữ liệu mẫu trong bảng KhachHang:

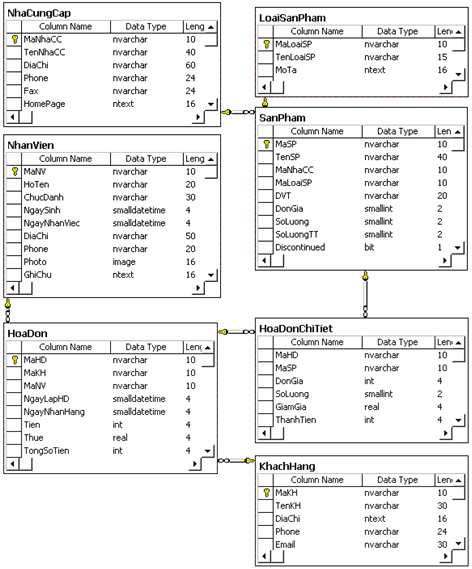
Dữ liệu mẫu trong bảng NhanVien:
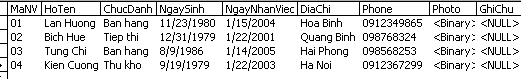
Dữ liệu mẫu trong bảng LoaiSanPham:
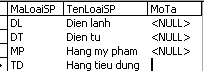
Dữ liệu mẫu trong bảng SanPham:
Lưu ý: Trường SoLuongTT có nghĩa là số lượng tối thiểu phải có trong kho. Nếu số lượng đến mức này thì phải nhập hàng từ nhà cung cấp.
Dữ liệu mẫu trong bảng HoaDon:

Dữ liệu mẫu trong bảng HoaDonChiTiet:
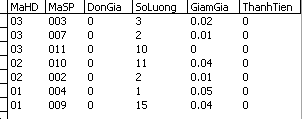
Hãy viết các lệnh T-SQL thực hiện các công việc sau:
1. Cập nhật đơn giá bảng hóa đơn chi tiết dựa theo đơn giá bảng sản phẩm.
1.1. Trong bảng HoaDonChiTiet cột thành tiền còn chưa được tính toán, hãy cập nhật trường ThanhTien= DonGia*SoLuong*(1-GiamGia).
2. Sau khi đã có thông tin về ThanhTien trong HoaDonChiTiet, hãy cập nhật thông tin của trường Tien trong hóa đơn = tổng số tiền của các mặt hàng có trong hóa đơn = tổng của cột ThanhTien của các bản ghi trong HoaDonChiTiet có cùng số hóa đơn (MaHD). Cập nhật trường TongSoTien=Tien*(1+Thue).
3. Hiển thị danh sách các mặt hàng với đầy đủ các thông tin sau: Loại hàng, mã hàng, tên hàng sắp xếp tăng dần theo tên hàng.
4. Liệt kê từng mặt hàng và tổng số hàng đã bán (có trong hóa đơn chi tiết) theo từng mặt hàng.
5. Liệt kê từng mặt hàng và tổng số tiền đã bán (có trong hóa đơn chi tiết) theo từng mặt hàng.
6. Liệt kê chi tiết các mặt hàng đã bán bao gồm các thông tin sau:
Số hóa đơn, Mã sản phẩm (hàng), tên sản phẩm, đơn giá, số lượng, giảm giá và thành tiền. Chỉ liệt kê những mặt hàng có giảm giá trên 1% (tức là trường GiamGia > 0.01), và ThanhTien <10000.
7. Hãy liệt kê danh sách khách hàng với đầy đủ các thông tin như: Mã khách hàng, tên khách hàng, địa chỉ, điện thoại, số hóa đơn đã đặt mua hàng trong tháng 3 năm 1997. (Chỉ liệt kê các khách hàng này và sắp xếp theo thứ tự tăng dần của họ và tên).
8. Liệt kê danh sách các mặt hàng đã bán theo từng loại hàng. Với mỗi loại hàng tính tổng số mặt hàng đã bán, tổng số tiền và cuối cùng có tổng số tất cả mặt hàng đã bán và tổng số tiền.
9. Liệt kê danh sách tất cả các khách hàng đã mua hàng trong tháng 11/2006 và tổng số tiền mà họ đã mua.
10 Liệt kê danh sách tất cả các nhân viên và số tiền hàng họ bán được trong tháng 11/2006.
Bài viết liên quan:
Dịch vụ thiết kế Wesbite





