Mệnh đề GROUP BY trong SQL Server
Mục lục
Mệnh đề Group By
Mệnh đề GROUP BY chia tập hợp kết quả thành một hoặc nhiều tập hợp con. Mỗi tập hợp con có các giá trị và biểu thức chung. Từ khóa GROUP BY được theo sau bởi một danh sách các cột, được gọi là grouped column. Mỗi grouped column hạn chế số hàng của tập kết quả. Đối với mỗi grouped column, chỉ có một hàng. Mệnh đề GROUP BY có thể có nhiều hơn một grouped column.
Cú pháp:
SELECT select_list FROM table_name GROUP BY column_name1,column_name2, ... ;Xét tình huống bảng WorkOrderRouting trong AdventureWorks2019. Tổng số giờ tài nguyên cho mỗi đơn đặt hàng công việc phải được tính toán. Để đạt được điều này, các bản ghi phải được nhóm theo số thứ tự công việc, là cột WorkOrderID
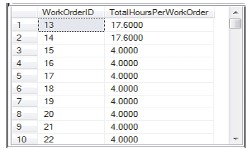
Ví dụ phía dưới truy xuất và hiển thị tổng số giờ tài nguyên cho mỗi đơn hàng công việc cùng với số thứ tự công việc. Trong truy vấn này, một hàm dựng sẵn có tên SUM() được sử dụng để tính tổng. SUM() là một hàm tính tổng các bản ghi của cột.
SELECT WorkOrderID,SUM(ActualResourceHrs) AS TotalHoursPerWorkOrder FROM Production.WorkOrderRouting GROUP BY WorkOrderIDCâu lệnh thực thi sẽ trả về toàn bộ các WorkOrder cùng tổng giờ tài nguyên.
Mệnh đề GROUP BY cũng có thể sử dụng để kết hợp với các mệnh đề khác như:
GROUP BY với WHERE
Mệnh đề WHERE có thể sử dụng với mệnh đề GROUP BY để để hạn chế các hàng cho việc nhóm dữ liệu. Các hàng thỏa mãn điều kiejen tìm kiểm sẽ được xét để nhóm lại. Những hàng không thỏa mãn điều kiện tìm kiếm sẽ được loại bỏ trước khi quá trình grouping hoàn thành.
Ví dụ:
SELECt WorkOrderID,SUM(ActualResourceHrs) AS TotalHoursPerWorkOrder FROM Production.WorkOrderRouting WHERE WorkOrderID < 50 GROUP BY WorkOrderIDGROUP BY với NULL
Nếu cột nhóm chứa giá trị rỗng, hàng đó sẽ trở thành một nhóm riêng biệt trong tập kết quả. Nếu cột nhóm chứa nhiều hơn một giá trị NULL, thì các giá trị NULL được đưa vào một hàng duy nhất. Hãy xem xét bảng Production.Product. Có một số hàng trong đó có giá trị NULL trong cột Class.
Sử dụng GROUP BY cho truy vấn bảng sẽ cũng sẽ sử dụng các giá trị NULL. Ví dụ: mã bên dưới truy xuất và hiển thị giá trung bình của giá niêm yết cho mỗi Class
SELECT Class, AVG(ListPrice) AS 'AverageListPrice' FROM Production.Product GROUP BY Class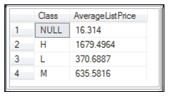
GROUP BY với ALL
Từ khóa ALL có thể sử dụng với mệnh đề GROUP BY. Nó chỉ có ý nghĩa khi SELECT có mệnh đề WHERE. Khi ALL được sử dụng, nó bao gồm tất cả các nhóm mà mệnh đề GROUP BY tạo ra. Nó thậm chí bao gồm những nhóm không đáp ứng các điều kiện tìm kiếm.
Cú pháp:
SELECT <column_name> FROM <table_name> WHERE <condition> GROUP BY ALL <column_name>Xét bảng Sales.SalesTerritory, bảng này có cột tên là Group chỉ ra vị trí toạ độ của khu vực bán hàng. Đoạn code dưới sẽ tính toán và hiển thị tổng các đơn hàng bán được cho mỗi nhóm. Đầu ra cần phải hiển thị toàn bộ các nhóm bất kể họ có bán hàng hay không. Để đạt được điều này, mã sử dụng GROUP BY với ALL
SELECT [Group], SUM(SalesYTD) AS 'TotalSales' FROM Sales.SalesTerritory WHERE [Group] LIKE 'N%' OR [Group] LIKE 'E%' GROUP BY ALL [Group]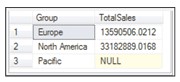
GROUP BY với HAVING
Mệnh đề HAVING được sử dụng với câu lệnh SELECT để chỉ định điều kiện tìm kiếm cho một nhóm. Mệnh đề HAVING hoạt động như một mệnh đề WHERE ở những nơi mà mệnh đề WHERE không thể được sử dụng để chống lại các hàm tổng hợp như SUM (). Khi bạn đã tạo các nhóm với mệnh đề GROUP BY, bạn có thể muốn lọc thêm kết quả. Mệnh đề HAVING hoạt động như một bộ lọc trên các dòng, tương tự như cách mệnh đề WHERE hoạt động như một bộ lọc trên các hàng được trả về bởi mệnh đề FROM.
Cú pháp:
SELECT <column_name> FROM <table_name> GROUP BY <column_name> HAVING <search_condition>Ví dụ:
SELECT [Group],SUM(SalesYTD) AS 'TotalSales' FROM Sales.SalesTerritory WHERE [Group] LIKE 'P%' GROUP BY ALL [Group] HAVING SUM (SalesYTD) < 6000000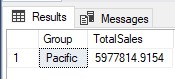
Tổng hợp dữ liệu (Summarizing Data)
Mệnh đề GROUP BY cũng sử dụng các toán tử là CUBE và ROLLUP để trả về dữ liệu tóm tắt. Số cột trong mệnh đề GROUP BY xác định số hàng tóm tắt trong tập kết quả. Các toán tử được mô tả như sau:
CUBE
CUBE là toán tử tổng hợp tạo ra một hàng siêu tổng hợp. Ngoài các hàng thông thường được cung cấp bởi GROUP BY, nó cũng cung cấp tóm tắt các hàng mà mệnh đề GROUP BY tạo ra.
Hàng tóm tắt được hiển thị cho mọi sự kết hợp có thể có của các nhóm là tập kết quả. Hàng Tóm tắt hiển thị NULL trong tập kết quả, nhưng đồng thời trả về tất cả các giá trị cho những giá trị đó.
Cú pháp:
SELECT <column_name> FROM <table_name> GROUP BY <column_name> WITH CUBEVí dụ:
Nghiệp vụ hiển thị tổng bán cho mỗi quốc gia, ngoại trừ Úc và Canada
SELECT Name, CountryRegionCode, SUM(SalesYTD) AS TotalSales FROM Sales.SalesTerritory WHERE Name <> 'Australia' AND Name <> 'Canada' GROUP BY Name,CountryRegionCode WITH CUBE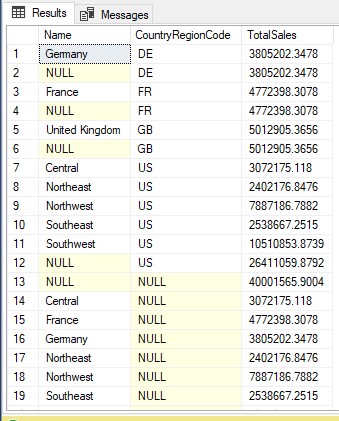
CUBE giống như một phần mở rộng của mệnh đề GROUP BY. CUBE cho phép bạn tạo tổng phụ cho tất cả các tổ hợp group column được chỉ định trong mệnh đề GROUP BY.
ROLLUP
Ngoài các hàng thông thường được tạo bởi GROUP BY, nó cũng đưa các hàng tóm tắt vào tập kết quả. Nó tương tự như toán tử CUBE, nhưng tạo ra một tập kết quả hiển thị các nhóm được sắp xếp theo thứ tự phân cấp. Nó sắp xếp các nhóm từ thấp nhất đến cao nhất. Phân cấp nhóm trong kết quả phụ thuộc vào thứ tự mà các cột được nhóm được chỉ định
Cú pháp:
SELECT <column_name1>[,<column_name2>] FROM <table_name> GROUP BY < WITH ROLLUPVí dụ:
SELECT [Name], SUM(SalesYTD) AS TotalSales FROM Sales.SalesTerritory GROUP BY [Name] WITH ROLLUP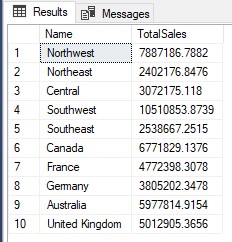
Bài viết liên quan:
Dịch vụ thiết kế Wesbite




