Toán tử Pivot (xoay trục) và Grouping Set (Nhóm tập hợp) trong SQL Server
Hình dung tình huống dữ liệu muốn hiển thị ra theo một định hướng khác với hướng dữ liệu đang lưu trữ, với các điều kiện về bố cục hàng và cột. Tiến trình biến đổi dữ liệu từ hướng dữ liệu dựa trên hàng thành dựa trên cột được gọi là pivot (xoay trục). Toán tử PIVOT và UNPIVOT trong SQL Server giúp thay đổi hướng dữ liệu từ hướng theo cột thành hướng theo hàng và ngược lại. Điều này được thực hiện bằng cách hợp nhất các giá trị có trong một cột thành một danh sách các giá trị riêng biệt và sau đó, chiếu danh sách đó dưới dạng tiêu đề cột.
Mục lục
Toán tử PIVOT
Cú pháp:
SELECT <non-pivoted column>,
[first pivoted column] AS <column name>,
[second pivoted column] AS <column name>,
...
[last pivoted column] AS <column name>
FROM
(<SELECT query that produces the data>)
AS <alias for the source query>
PIVOT
(
<aggregation function>(<column being aggregated>)
FOR
[<column that contains the values that will become column headers>]
IN ( [first pivoted column], [second pivoted column],
... [last pivoted column])
) AS <alias for the pivot table>
<optional ORDER BY clause>; Nói một cách đonw giản hơn, để sử dụng PIVOT chúng ta cần 3 thành phần trong cú pháp:
- Trong mệnh đề FROM, cột nhập vào luôn phải được cung cấp, toán tử PIVOT sử dụng các cột này để nhận diện xem cột nào sẽ được sử dụng để nhóm dữ liệu cho việc tập hợp.
- Dấu phẩy phana tách xuất hiện trong dữ liệu nguồn cung cấp sẽ được sử dụng như tieue đề cột cho dữ liệu đã được xoay trục.
- Với Aggregation function (hàm tập hợp), như là SUM, sử dụng để xử lý tính toán và nhóm các bản ghi
Ví dụ:
Xét tình huống phía dưới, khi muốn lấy ra giá cost trung bình của số ngày sửa chữa trong các tình huống 1,2,3,4 ngày, nếu sử dụng GROUP BY thông thường cú pháp sẽ như sau:
USE AdventureWorks2019 ;
GO
SELECT DaysToManufacture, AVG(StandardCost) AS AverageCost
FROM Production.Product
GROUP BY DaysToManufacture; 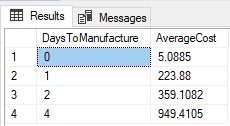
Kết quả này trả ra thiếu bản ghi DaysToManufacture là 3, vì với tình hống 3 giá COST không tính trung bình được vì không có dữ liệu. Vấn đề này có thể được xử lý thông qua PIVOT như sau:
SELECT 'AverageCost' AS Cost_Sorted_By_Production_Days,
[0], [1], [2], [3], [4]
FROM
(
SELECT DaysToManufacture, StandardCost
FROM Production.Product
) AS SourceTable
PIVOT
(
AVG(StandardCost)
FOR DaysToManufacture IN ([0], [1], [2], [3], [4])
) AS PivotTable; 
Ví dụ 2:
Lấy ra top 5 tổng SaleYTD của bảng Sales.SalesTerritory, như sau:
SELECT TOP 5 SUM(SalesYTD) AS TotalSalesYTD, Name FROM Sales.SalesTerritory GROUP BY Name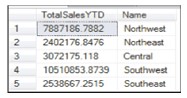
Và vì dữ liệu ít, chỉ thể hiện giá trị của từng khu vực, nên chúng ta có thể dàn ngang dữ liệu ra để khi truy vấn tới CSDL, CSDL sẽ trả ra duy nhất một dòng, gia tăng khả năng đọc phân tích cho người truy vấn:
SELECT TOP 5 'TotalSalesYTD' AS GrandTotal, [NorthWest],[NorthEast],[Central],[Southwest],[Southeast] FROM (SELECT TOP 5 Name,SalesYTD FROM Sales.SalesTerritory) AS SourceTable PIVOT (SUM(SalesYTD) FOR Name IN ([NorthWest],[NorthEast],[Central],[Southwest],[Southeast])) AS PivotTable;
Một thách thức lớn trong việc viết các truy vấn bằng PIVOT là yêu cầu cung cấp một danh sách cố định các phần tử trải rộng cho toán tử PIVOT. Sẽ không khả thi hoặc không thực tế nếu thực hiện điều này đối với một số lượng lớn các phần tử dàn trải. Để khắc phục điều này, các nhà phát triển có thể sử dụng SQL động. SQL động cung cấp một giải pháp để xây dựng một chuỗi ký tự được chuyển đến SQL Server, được hiểu như một lệnh và sau đó, SQL Server thực thi.
Toán tử UNPIVOT
Toán tử UNPIVOT hiểu như ngợc lại của PIVOT, nghĩa xoay trục từ cột thành hàng. Unpivot sẽ không lưu trữ giá trị gốc, dữ liệu chi tiết đã bị mất trong quá trình tập hợp khi pivot. UNPIVOT không có khả năng cấp phát giá trị để trả ra dữ liệu chi tiết gốc. Thay bằng việc chuyển đổi các hàng thành cột, kết quả của unpivot chuyển đổi lại từ cột thành hàng. SQL Server cung cấp toán tử UNPIVOT để chuyển đổi dữ liệu từ bảng đã pivote thành hướng dựa trên hàng.
Trong khi đang unpivot dữ liệu, một hoặc nhiều cột được định nghĩa như là nguồn sẽ được chuyển đổi thành hàng. Dữ liệu trong những hàng này được trải rộng hoặc tách ra từ một thành nhiều hàng, dựa theo có bao nhiêu cột cần unpivote.
Ví dụ:
CREATE TABLE pvt (VendorID INT, Emp1 INT, Emp2 INT,
Emp3 INT, Emp4 INT, Emp5 INT);
GO
INSERT INTO pvt VALUES (1,4,3,5,4,4);
INSERT INTO pvt VALUES (2,4,1,5,5,5);
INSERT INTO pvt VALUES (3,4,3,5,4,4);
INSERT INTO pvt VALUES (4,4,2,5,5,4);
INSERT INTO pvt VALUES (5,5,1,5,5,5);
GO
-- Unpivot the table.
SELECT VendorID, Employee, Orders
FROM
(SELECT VendorID, Emp1, Emp2, Emp3, Emp4, Emp5
FROM pvt) p
UNPIVOT
(Orders FOR Employee IN
(Emp1, Emp2, Emp3, Emp4, Emp5)
)AS unpvt;
GO 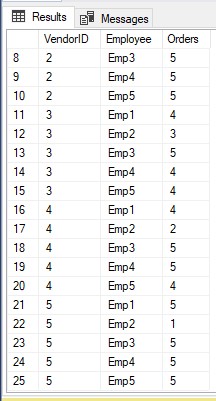
Bài viết liên quan:
Dịch vụ thiết kế Wesbite



