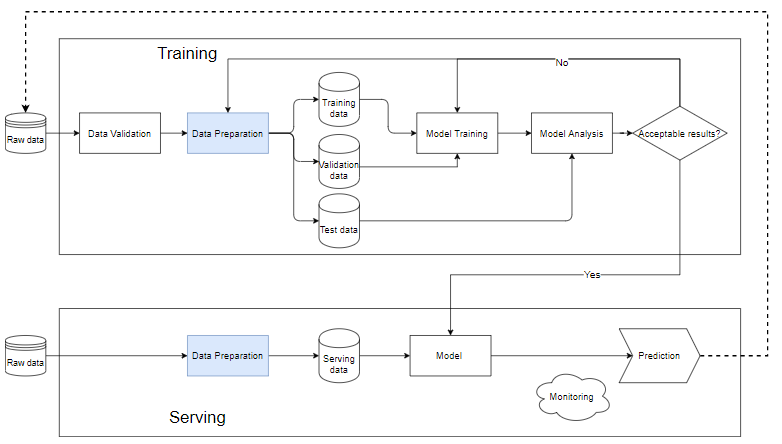
Pipeline trong machine learning
Pipeline trong ML là một cách để tư động hóa quy trình làm việc để tạo ra một mô hình học máy. Hầu như mọi hệ thống Machine Learning đều có các thành phần như sơ đồ dưới đây, nó là một machine learning pipeline.
Mục lục
Pipeline trong machine learning là gì?
Khối Training
- Data validation: Là bước kiểm định dữ liệu, xác định xem dữ liệu mới thêm vào có thỏa mãn với dữ liệu trong database không. Vì thực tế dữ liệu mới sẽ luôn được thêm vào để thực hiển train.
- Sau khi dữ liệu thô được làm sạch sang bước Data Prepration sau đó được tác ra thành tập huấn luyện (training data) và tập huấn luyện (training data) và tập kiểm định (validation data), ngoài ra cũng có thể tạo ra tập test data để xác định chất lượng mô hình sau quá trình huấn luyện.
- Dữ liệu huấn luyện được đưa vào khối “model training” để huấn luyện mô hình.
- Huấn luyện xong chúng ta thực hiện phân tích trong khối “model analysis” để phân tích chất lượng. Kiểm tra xem metrics trên tập kiểm tra có tốt không, kết quả dự đoán và kết quả thực kế có tương đương nhau không, tốc độ dự đoán,…
- Khi mà dự liệu qua khối model analysis mô hình sẽ dùng cho việc chạy dữ liệu thực tế ở bước “Serving”. Nếu không ta cần phải xem lại mô hình hoặc lọc lại dữ liệu.
Khối Serving
- Khi mô hình vẫn còn sơ khai thì chúng ta nên sử dụng một bộ dữ liệu nhỏ, chạy thử nghiệp, nếu thấy chất lượng chấp nhận được thì ta có thể thực hiện trên toàn bộ dữ liệu.
- Data Preparation giúp làm sạch và tạo dữ liệu sẽ phải giống như mô hình trong khối training.
- Mỗi bài toán khác nhau cần có một hệ thống theo dõi và cảnh báo khác nhau. Thường thì với bất kể dữ liệu đầu vào như thế nào, mô hình vẫn sẽ cho ra một kết quả dự đoán, có thể là ngẫu nhiên. Nếu các kết quả này không được theo dõi và báo động một cách kỹ lưỡng dẫn đến việc chất lượng mô hình cũng như phản ứng của người dùng thay đổi một cách đột ngột thì uy tín cũng như doanh thu của công ty sẽ bị ảnh hưởng trầm trọng.
Tại sao cần xây dựng pipeline?
- Hệ thống machine learning thường bao gồm rất nhiều các thành phần nhỏ như xử lý dữ liệu, huấn luyện mô hình, đánh giá mô hình, dự đoán với dữ liệu mới, v.v. Nếu không xây dựng một pipeline hoàn chỉnh với từng thành phần tách biệt rõ ràng, sẽ có rất nhiều vấn đề xảy ra. Việc tách hệ thống của bạn ra từng bước và ghép lại thành pipeline giúp dễ dàng tìm ra lỗi khi thực hiện training model.
- Việc xây dựng pipeline còn giúp chúng ta làm việc nhóm với nhau tốt hơn. Nếu có nhóm lớn, ta có thể chia ra thành từng nhóm nhỏ: một nhóm chuyên làm sạch dữ liệu, một nhóm chuyên tạo các đặc trưng, nhóm khác đi xây dựng và huấn luyện mô hình và một nhóm khác tập trung vào đánh giá và theo dõi hoạt động của mô hình. Những khối công việc này nếu được tách nhỏ và chuyên biệt sẽ giúp các nhóm đi sâu vào cải thiện chất lượng của từng khối mà không lo đến việc làm hỏng code của nhóm khác.
Ví dụ đơn giản
Sau đây tôi sẽ giới thiệu một pipeline hoàn thiện, tôi sẽ không đi sâu vào từng dòng lệnh mà muốn dùng ví dụ này để các bạn có cái nhìn tổng quát về một pipeline. Bạn có thể xem toàn bộ code ở đây
Bước đầu import những thư viện cần thiết.
from pathlib import Path
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import KNNImputer, SimpleImputer
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, RobustScalerLoad dữ liệu
titanic_path = ( "https://github.com/CongSon01/titanic_pipeline/" ) df_train_full = pd.read_csv(titanic_path + "train.csv") df_test = pd.read_csv(titanic_path + "test.csv")
Drop những dữ liệu missing, không mang lại hiệu quả cho mô hình.
df_train_full.drop(columns=["Cabin"])
df_test.drop(columns=["Cabin"]);Trước khi đi vào bước xây dựng đặc trưng, ta cần phân chia dữ liệu huấn luyện/kiểm định. Ở đây, 10% ngẫu nhiên của dữ liệu có nhãn ban đầu được tách ra làm dữ liệu kiểm định (validation data), 90% còn lại được giữ làm dữ liệu huấn luyện (training data). Cột Survived là cột nhãn được tách ra làm một biến riêng chứa nhãn:
df_train, df_val = train_test_split(df_train_full, test_size=0.1)
X_train = df_train.copy()
y_train = X_train.pop("Survived")
X_val = df_val.copy()
y_val = X_val.pop("Survived")Xử lý feature với kiểu categorical hay dữ liệu số sẽ có các cách xử lý khác nhau. Đâu tiên ta xử lý dữ diệu dạng categorical.
cat_cols = ["Embarked", "Sex", "Pclass"]
cat_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("onehot", OneHotEncoder(handle_unknown="ignore", sparse=False)),
]
)Tiếp theo ta áp dụng num_transformer lên hai đặc trưng số:
num_cols = ["Age", "Fare"]
num_transformer = Pipeline(
steps=[("imputer", KNNImputer(n_neighbors=5)), ("scaler", RobustScaler())]
)Kết hợp hai bộ xử lý ta có được bộ xử lý hoàn thiện. Lớp ColumnTransformer trong scikit-learn giúp kết hợp các transformers lại:
preprocessor = ColumnTransformer(
transformers=[
("num", num_transformer, num_cols),
("cat", cat_transformer, cat_cols),
]
)Cuối cùng ta kết hợp bộ xử lý đặc trung preprocessor với một bộ phân loại đơn giản hay được sử dụng với dữ liệu dạng bảng là RandomForestClassifier để được một pipeline full_pp hoàn trình bao gồm cả xử lý dữ liệu và mô hình. Full_pp được fit với dữ liệu huấn luyên (X_train, y_train) sau đó được dùng để áp dụng lên dữ liệu kiểm định.
# Full training pipeline
full_pp = Pipeline(
steps=[("preprocessor", preprocessor), ("classifier", RandomForestClassifier())]
)
# training
full_pp.fit(X_train, y_train)
# training metric
y_train_pred = full_pp.predict(X_train)
print(
f"Accuracy score on train data: {accuracy_score(list(y_train), list(y_train_pred)):.2f}"
)
# validation metric
y_pred = full_pp.predict(X_val)
print(
f"Accuracy score on validation data: {accuracy_score(list(y_val), list(y_pred)):.2f}"
)Accuracy score on train data: 0.98 Accuracy score on validation data: 0.83
Như vậy, cả hệ thống này cho độ chính xác 98% trên tập huấn luyện và 83% trên tập kiểm định. Sự chênh lệch này chứng tỏ đã xảy ra hiện tượng overfitting (mình sẽ nói ở những bài viết sau).
Bài viết liên quan:







Dịch vụ thiết kế Wesbite


