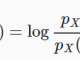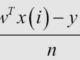Phân loại các thuật toán trong Machine Learning
Có nhiều loại thuật toán học khác nhau, được phân loại theo nhiều tiêu chí khác nhau. Chẳng hạn dựa và cách mà mô hình đó học (learning style) hoặc là theo chức năng (function) thì có thế tóm gọn lại cới các tiêu chí như sau:
- Quá trình huấn luyện có cần sự giám sát của con người hay không? Supervised (có giám sát), Unsupervised (không giám sát), Semi-supervised ( nửa giám sát) và Reinforcement Learning (học tăng cường).
- So sánh về sự thay đổi của dữ liệu so sách các điểm dữ liệu cũ so với các điểm dữ liệu mới từ đó đưa ra kết luận hoặc xây dựng các mẫu quy tắc cho dữ liệu huấn luyện rồi xây dựng các model để đoán giống như một số thuật toán(Instance-based, model-based learning).
Mục lục
Supervised/Unsupervised Learning
Thuật toán này thường được dùng trong các bài toán phân cụm/gán nhãn cho dữ liệu.
Supervised learning
Từ cặp dữ liệu đầu vào là (data, label) và sẽ dự đoán được đầu ra là của dữ liệu mới new input. Nghĩa là khi đầu vào là tập X={x1, x2,…, xn} và tập nhãn tương ứng Y = {y1, y2, .., yn} trong đó X, Y là 2 vector. Cho X và Y là tập training data, từ tập train này ta sẽ cần một hàm giúp ánh xạ mỗi phần tử của X sang một phẩn tử y dự đoán với y_pre ~ f(xi).

Bài toán kiểm tra email có phải spam hay không là một ứng dụng thực tế đối với mô hình này. Thuật toán sẽ có đầu vào là các email với nhãn là spam hoặc không. Và từ đó thuật toán dự theo các feartures xác định được một email với dữ liệu mới có phải là spam hay không. Một số bài thuật toán học có giám sát như Linear Regression, Logistic regression, Neural Networks, …
Unsupervised Learning
Trong thuật toán này, chúng ta chúng ta sẽ không biết outcome mà chỉ biết dữ liệu đầu vào. Xác định dựa vào cấu trúc dữ liệu để thực hiện một công việc nào đó ví dụ như clustering. Hệ thống sẽ học mà không cần ai dạy.
Có thể kể tới 2 thuật toán trong mô hình unsupervised learning như: Clustering hay Association
- Clustering: Giúp chia nhỏ dữ liệu dựa trên sự liên quan giữa chúng. Ví dụ việc phân nhóm khách hàng trên mạng xã hội từ đó phân tích hành vi người dùng và đưa dữ liệu tới một nhóm người có sự tương đồng với nhau.
- Một số thuật toán phân cụm phổ biến
- K-Means
- k-Medians
- Expectation Maximization
- Hierarchical Cluster Analysis (HCA)
- Một số thuật toán phân cụm phổ biến
- Association: Xác định quy luật của dữ liệu.
Semi-Supervised Learning (Học bám giám sát)
Các bài toán khi chúng ta có một lượng lớn dữ liệu nhưng chỉ một phần trong đó chúng ta được gán nhãn thì đó được gọi là Semi-Supervised Learning. Cái này thì nó ở giữa Unsupervised và Supervised Learning. Ví dụ như bài toán chỉ có một phần ảnh hoặc văn bản được gán nhãn (ví dụ bức ảnh về người, động vật hoặc các văn bản khoa học, chính trị) và phần lớn các bức ảnh/văn bản khác chưa được gán nhãn được thu thập từ internet. Thực tế cho thấy rất nhiều các bài toán Machine Learning thuộc vào nhóm này vì việc thu thập dữ liệu có nhãn tốn rất nhiều thời gian và có chi phí cao. Rất nhiều loại dữ liệu thậm chí cần phải có chuyên gia mới gán nhãn được (ảnh y học chẳng hạn). Ngược lại, dữ liệu chưa có nhãn có thể được thu thập với chi phí thấp từ internet.
Reinforcement Learning (Học tăng cường)
Dữ liều đầu vào của học tăng cường gần như là không xác định được đúng sai. Mà thuật toán sẽ học một cách trực tiếp. Khi đó việc học càng nhiều sẽ khiến sự đúng đắn của dữ liệu đầu ra càng cao do mỗi lần học máy sẽ được thưởng một phần thưởng nào đó. Ví dụ như AlphaGo là một hệ thống sử dụng học tăng cường và đã chiến thằng cả người chơi cờ vây giỏi nhất thế giới.
Tóm lại
Việc xác định được dữ liệu của mình thuộc vào mô hình nào là bước rất quan trọng để tìm ra thuật toán training phù hợp với dữ liệu và yêu cầu bài toán. Qua bài viết này hi vọng mọi người sẽ hiểu thêm về các thuật toán trong ML. Ở những bài sau mình sẽ đi sâu vào giải thích và phân tích từng thuật toán mà đã nêu ra ở trên.