
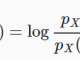



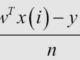






Giới thiệu
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: [email protected]
Thì gần đây mình có làm một dự án nhỏ nhỏ sử dụng LSTMs mà đọc tài liệu tiếng việt để hiểu sâu về nói thì chưa thấy rõ lắm, có bài viết này https://dominhhai.github.io/vi/2017/10/what-is-lstm/ được dịch từ trang nước ngoài mình thấy cũng khá hay. Thì trả qua dự án mình đã làm thì mình xin ở đây để chia sẻ về một số thứ cho mọi người và cả mình trong tương lai khi lâu không dùng nói rồi đọc lại để ngẫm.
Mục lục
Trước khi giải thích về LSTMs mình nghĩ nên biết một chút về gốc của nói RNN (Recurrent Neural Networks) được minh họa dưới đây:
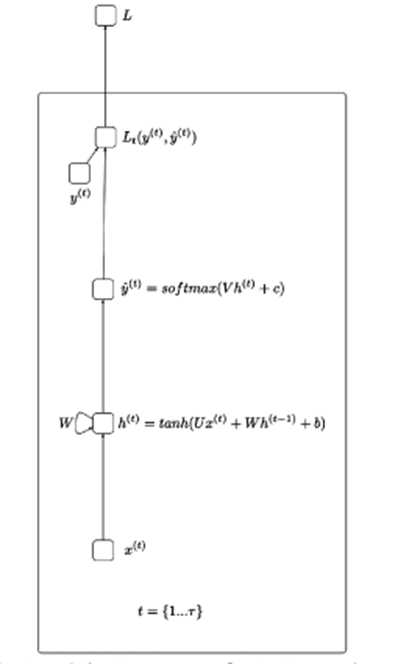
Hiểu đơn giản thì RNN giúp xử lý dữ liệu có dạng chuỗi tuần tự – như xử lý dọng nói, hành động,… Ý tưởng của hình trên là đầu vào x sẽ đi qua các hidden layer và trả ra giá trị đầu ra (có thể là 1 mảng) Từ kết quả đầu ra đi qua hàm loss sẽ được y_hat.
X(t): Giá trị đầu vào tại bước thời gian t
H(t): Trạng thái ẩn tại bước thời gian t
O(t): Giá trị đầu ra tại bước thời gian t
Y_hat: Vector xác suất đã chuẩn hóa qua hàm softmax tại bước thời gian t
U, V, W: Các ma trận trọng số trong mạng RNN tương ứng với các kết nối theo chiều từ đầu đến trạng thái ẩn, từ trạng thái ẩn đến đầu ra và từ trạng thái ẩn đến trạng thái ẩn.
B, c: Độ lệch (bias)
LSTM giúp khắc phục tình trạng Vanishing gradient của mạng RNN. Khi mà ta sử dụng gradient để huấn luyện nơ-ron và RNN còn bị ảnh hưởng bởi khả năng ghi nhớ ngắn hạn ( short term memory ) khi dữ liệu đầu vào dài thì RNN có thể quên những thông tin quan trọng được truyền ngay từ đầu.
Ví dụ như khi xem seris phim thì bộ não chúng ta sẽ lưu lại những thông tin nội dung của những phần trước kết hợp với tập đang xem để tạo ra câu truyện.
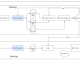
LSTM giúp giảm bớt những điểm dữ liệu không cần thiết bằng những gate được cài đặt bên trong và có một cell state chạy xuyên suốt

Có rất nhiều bài viết và hình ảnh đã giải thích về hoạt động của từng gate và các hàm active function. Thì ở đây mình thử sử dụng toán để giải thích về thằng này. Tóm gọn nhanh thì LSTM sử dụng 1 cell state và 3 gate để xử lý dữ liệu đầu vào. Công thức mình để ở ảnh dưới:


Đây là hoạt động của LSTM trong 1 time step, ý là các công thức này sẽ được tính lại khi ở một time step khác. Và những trọng số (Wf, Wi, Wo, Wc, Uf, Ui, Uo, Uc) và bias (bf, bi, bo, bc) thì không thay đổi.
Ví dụ để triển khai LSTM trên 10 timesteps thì có thể thực thi như sau:
sequence_len = 10
for i in range (0,sequence_len):
# if we are on the initial step
# initialize h(t-1) and c(t-1)
# randomly
if i==0:
ht_1 = random ()
ct_1 = random ()
else:
ht_1 = h_t
ct_1 = c_t
f_t = sigmoid (
matrix_mul(Wf, xt) +
matrix_mul(Uf, ht_1) +
bf
)
i_t = sigmoid (
matrix_mul(Wi, xt) +
matrix_mul(Ui, ht_1) +
bi
)
o_t = sigmoid (
matrix_mul(Wo, xt) +
matrix_mul(Uo, ht_1) +
bo
)
cp_t = tanh (
matrix_mul(Wc, xt) +
matrix_mul(Uc, ht_1) +
bc
)
c_t = element_wise_mul(f_t, ct_1) +
element_wise_mul(i_t, cp_t)
h_t = element_wise_mul(o_t, tanh(c_t))
Vấn đề không thể thiếu trong toán tuyến tính là số chiều của dữ liệu ( đây có thể là phần mà sau này tôi của tương lại cũng phải đọc lại vì nó thường trong list câu hỏi phỏng vấn ).
Với các công thức của LSTM tại một timestep như sau:
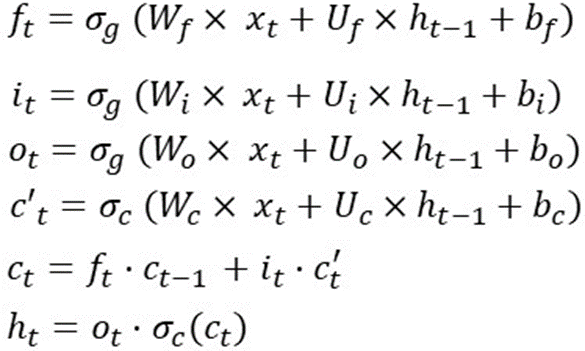
Giả sử dim(o(t)) là [12×1] => dim(h(t)) và dim(c(t)) là [12×1] vì h(t) là phép nhân từng phần tử giữa o(t) và tanh(c(t)).
Và x(t) có số chiều là [80×1] => W(f) là [12×80] vì f(t) = [12×1] và x(t)=[80×1]
Bf, bi, bc, bo có số chiều là [12×1]
Và Uf, Ui, Uc, Uo có số chiều là [12×12]
Như vậy tổng số weight của LSTM là: 4*[12×80] + 4*[12×12] + 4*[12×1] = 4464.
Nhìn vào cách tính bên trên có thể thấy LSTMs quan tâm tới 2 thứ: Input dimension và Output dimensionality ( một vài blog có thể gọi là number of LSTM units hay hidden dimention,…).
Tổng kết lại weight matrix size của LSTM là 4*Output_Dim*(Output_Dim + Input_Dim + 1)
Có một lưu ý về tham số mà nhiều người nhầm lẫn:

Trong Keras có cho ta một tham số là return_sequence (trả về true, false) khi return_squence=False (mặc định) thì nó là nhiều thành một và ngược lại True thì sẽ là từ nhiều trả ra nhiều.
Ví dụ với dữ liệu đầu vào X có kích thước [5×126]
Model như sau:
model = Sequential()
model.add(LSTM(64, return_sequences=True, activation=’relu’, input_shape=(5,126)))
model.add(LSTM(128, return_sequences=True, activation=’relu’))
model.add(LSTM(64, return_sequences=False, activation=’relu’))
model.add(Dense(64, activation=’relu’))
model.add(Dense(32, activation=’relu’))
model.add(Dense(actions.shape[0], activation=’softmax’))
Có thể thấy qua lớp LSTM đầu với số hidden là 64 => Số param sau khi qua lớp này là:
4*((126+64)*64+64) = 48896 ( tương tự như vậy với 2 lớp LSTM sau và đầu ra của nó sẽ là đầu vào của lớp tiếp theo).
Đối với các lớp Dense ( là 1 layer trong keras với output_dim là số chiều đầu ra của layer đó) do vậy số lượng tham số mới nó bằng output_dim * output_dim (của lơp trước nói)+1
Ví dụ với lớp dense đầu tiên: số tham số là: 64*(64+1)=4160

Tóm lại trong bài viết này mình đã cố gắng giải thích các hoạt động của LSTM từ góc độ tính toán các tham số đây là một bước khá quan trọng giúp bạn thiết kế và tăng tốc mô hình học máy.
hocvietcode.com là website chia sẻ và cập nhật tin tức công nghệ, chia sẻ kiến thức, kỹ năng. Chúng tôi rất cảm ơn và mong muốn nhận được nhiều phản hồi để có thể phục vụ quý bạn đọc tốt hơn !
Liên hệ quảng cáo: [email protected]