Mô hình quan hệ thực thể (mô hình E-R) và chuẩn hóa dữ liệu (normalization)
Mô hình dữ liệu là một nhóm các công cụ khái niệm sử dụng để mô tả dữ liệu, mối quan hệ, nghĩa nghĩa của chúng. Chúng cũng bao gồm những ràng buộc về tính nhất quán mà dữ liệu cần tuân theo. Trong mô hình mối quan hệ thực thể (Entity – Relationship), quan hệ mạng lưới hay mô hình phân tầng đều là ví dụ về những mô hình dữ liệu, có thể xem lại bài viết Giới thiệu về các mô hình cơ sở dữ liệu, giới thiệu về RDBMS Concept (Related database management system) để hiểu hơn. Sự phát triển của mỗi CSDL bắt đầu từ các bước cơ bản của phân thích dữ liệu để tìm ra mô hình dữ liệu phù hợp nhất để biểu diễn dữ liệu.
Mục lục
Mô hình dữ liệu (Data Modeling)
Quá trình áp dụng một mô hình dữ liệu thích hợp cho dữ liệu, để tổ chức và cấu trúc nó, được gọi là mô hình hóa dữ liệu (data modeling).
Mô hình hóa dữ liệu cũng cần thiết cho việc phát triển cơ sở dữ liệu cũng như lập kế hoạch và thiết kế cho bất kỳ dự án nào. Xây dựng database mà không cần mô hình dữ liệu cũng giống việc phát triển dự án mà không có kế hoạch hoặc thiết kế. Mô hình dữ liệu giúp nhà phát triển CSDL định nghĩa ra đợc các mối quan hệ của bảng, khóa chính (primary key), khóa ngoại (foreign key), thủ tục lưu trữ (store procedure), triggers (có thể hiểu nôm na là kích hoạt sự kiện) … trong CSDL.
Các bước mô hình hóa dữ liệu như sau:
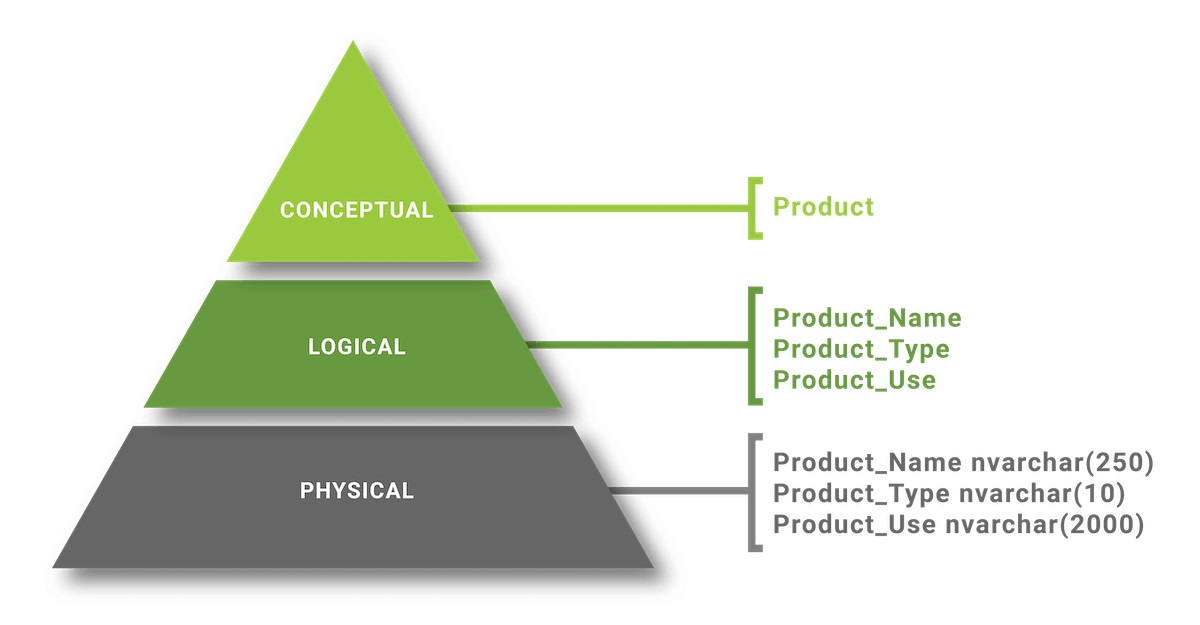
- Mô hình hóa dữ liệu ý niệm (Conceptual Data Modeling): Dữ liệu được mô hình hóa của mối quan hệ trong dữ liệu ở tầng cao nhất. Mục đích của mô hình này là để tổ chức, phạm vi và xác định các khái niệm và quy tắc, quy trình kinh doanh. Khi mô hình dữ liệu khái niệm được tạo ra, nó có thể được điều chỉnh và chuyển thành mô hình dữ liệu logic.
- Mô hình hóa dữ liệu logic (Logical Data Modeling): Dữ liệu được mô hình hóa mô tả dữ liệu và mối quan hệ của chúng một cách chi tiết. Dữ liệu được mô hình hóa tạo ra các mô hình logic của cơ sở dữ liệu. Mục đích chính của mô hình là phát triển bản đồ kỹ thuật của các quy tắc và cấu trúc dữ liệu. Mô hình dữ liệu logic sẽ làm cơ sở cho việc tạo ra một mô hình dữ liệu vật lý.
- Mô hình hóa dữ liệu vật lý (Physcical Data Modeling): Mô hình này mô tả cách hệ thống sẽ được triển khai bằng cách sử dụng một hệ thống quản lý cơ sở dữ liệu cụ thể. Mô hình này thường được tạo ra bởi chuyên viên quản trị dữ liệu và các nhà phát triển với mục đích chính là triển khai thực tế cơ sở dữ liệu.
Mô hình quan hệ thực thể (Entity-Relationship) – E-R Model
Mô hình dữ liệu có thể được phân loại thành 3 nhóm khác nhau:
- Mô hình logic dựa trên đối tượng
- Mô hình logic dựa trên bản ghi
- Mô hình vật lý
Mô hình Entity-Relationship (E-R) thuộc về phân loại đầu tiên – mô hình logic dựa trên đối tượng.
Mô hình dựa trên ý tưởng đơn giản liên hệ với thực tế. Dữ liệu có thể được coi là các đối tượng trong thế giới thực được gọi là các vật thể và các mối quan hệ tồn tại giữa chúng. Ví dụ, dữ liệu về các nhân viên làm việc cho một tổ chức có thể được coi là một tập hợp các nhân viên và một tập hợp các bộ phận (phòng ban) khác nhau tạo thành tổ chức. Cả nhân viên và bộ phận đều là các đối tượng trong thế giới thực. Một nhân viên thuộc một bộ phận. Do đó, mối quan hệ ‘thuộc về’ liên kết một nhân viên với một bộ phận cụ thể.

Một mô hình E-R chứa 5 thành phần cơ bản như sau:
| Entity (thực thể) | Một entity (thực thể) là một đối tượng trong thế giới thực, tồn tại vật lý và có thể phân biệt được với các đối tượng khác. Ví dụ: nhân sự, phòng ban, sinh viên, khách hàng, tài khoản ….. có thể gọi là entity |
| Relationship (mối quan hệ) | Một relationship (mối quan hệ) là một sự kết hợp hoặc liên kết, tồn tại giữa một hoặc nhiều thực thể với nhau. Ví dụ: thuộc về, sở hữu, làm việc cho, lưu trong, đã mua …. |
| Attributes (thuộc tính) | Một attributes (thuộc tính) là một tính năng mà thực thể có.. Thuộc tính giúp phân biệt mỗi thực thể với thực thể khác. Ví dụ cho 2 thuộc tính sinh viên và customer, cùng là người nhưng có các thuộc tính khác nhau khi biểu diễn trên CSDL: – Entity student có các thuộc tính student_id, name,age, mark. – Entity customer có các thuộc tính customer_id,name,age,phone,address |
| Entity set (tập thực thể) | Một tập thực thể (entity set) là một danh sách(tập hợp) các đối tượng tương đồng nhau. Ví dụ danh sách sinh viên của một trường học (theo một quy chuẩn chung với các thuộc tính giống nhau) đợc gọi là tập thực thể sinh viên (student entity set) |
| Relationship set (tập mối quan hệ) | Một danh sách (tập hợp) các mối quan hệ giữa 2 hoặc nhiều các tập thực thể được gọi là relationship set. Ví dụ: sinh viên học tập nhiều môn học khác nhau, tập hợp của tất cả các mối quan hệ “học tập môn học” tồn tại giữ 2 thực thể sinh viên và môn học có thể gọi là tập mối quan hệ “học tập môn học” |
Mối quan hệ liên kết giữa một hoặc nhiều thực thể và có thể có 3 kiểu quan hệ như sau:
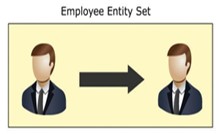
Self-relationships (quan hệ với chính bản thân)
Mối quan hệ giữa thực thể với các đối tượng giống nó được gọi là self relationship. Ví dụ, một quản lý và thành viên của của nhóm, cả 2 đều là nhân sự và đều thuộc về một tập thực thể. Các thành viên trong nhóm làm việc cho quản lý, vì vậy, mối quan hệ “làm việc cho” tồn tại giữa 2 thực thể nhân sự khác nhau nhưng các nhân sự này cùng nằm trong một tập thực thể.
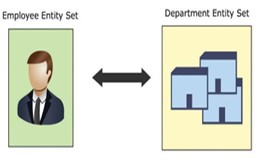
Binary relationships (quan hệ hai ngôi)
Mối quan hệ tồn tại giữa các thực thể nằm trong 2 tập thực thể khác nhau được gọi là binary relationship. Ví dụ, một một nhân sự thuộc về một phòng ban. Mối quan hệ tồn tại giữa 2 thực thể nằm trong 2 tập thực thể khác nhau. Thực thể nhân sự nằm trong tập thực thể (employee), thực thể phòng ban nằm trong tập thực thể (department)
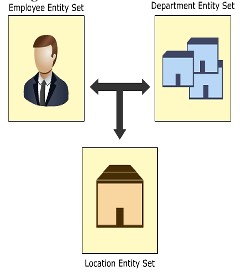
Ternary relationship (quan hệ 3 ngôi)
Hiểu đơn giản, mối quan hệ này là mối quan hệ 3 thực thể cùng tham gia, người ta gọi là ternary relationship. Ví dụ: một nhân sự làm việc cho phòng ban tài chính trong một chi nhánh nào đó của tổ chức. Trong đây có 3 thực thể khác nhau là nhân sự, phòng ban, chi nhánh, nhân sự sẽ liên kết với phòng ban thông qua tập thực thể biểu diễn chi nhánh.
Mối quan hệ cũng có thể được phân loại theo các bản đồ ánh xạ (mapping cardinalities). Các loại ánh xạ khác nhau được phân biệt như sau:
One-to-one ( ánh xạ một một)
Ánh xạ này tồn tại khi đối tượng của một tập thực thể có thể được liên kết với chỉ một thực thể của tập thực thể khác. Ví dụ: mã căn cước công dân của một công dân, sẽ liên kết trực tiếp và duy nhất với mã bằng lái xe máy của một công dân. Không thể nào một công dân với một mã căn cước có thể có nhiều mã bằng lái xe máy. Người ta gọi là ánh xa hay quan hệ 1-1.

One-to-many (ánh xạ một nhiều)
Kiểu ánh xạ này sử dụng khi một thực thể trong tập thực thể có liên kết với nhiều hơn một thực thể ở tập thực thể khác. Ví dụ: có nhiều sinh viên trong một lớp học, ánh xạ một nhiều thường sử dụng để biểu diễn ánh xạ này. Người ta thường gọi là quan hệ 1 – nhiều hoặc ánh xạ 1 – nhiều.
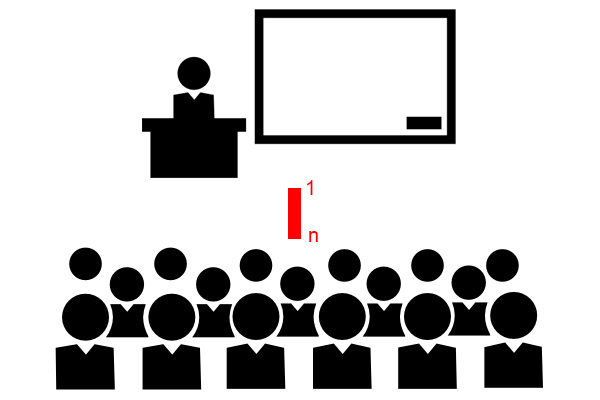
Many-to-one (ánh xạ nhiều một)
Kiểu ánh xạ này sử dụng khi có nhiều thực thể trong một tập thực thể được liên kết với một thực thể của một tập thực thể khác. Chúng ta hiểu nôm na ánh xạ này ngược lại với ánh xạ một nhiều. Ví dụ: một lớp học có nhiều học sinh.
Many-to-many (ánh xạ nhiều nhiều)
Kiểu ánh xạ này sử dụng khi nhiều thực thể của một tập thực thể liên kết với nhiều thực thể của tập thực thể khác.
Ví dụ: một cửa hàng có nhiều sản phẩm bán ra, mỗi đơn hàng của khách hàng khi mua sẽ bao gồm nhiều sản phẩm khác nhau, chúng ta có thể thấy 1 đơn hàng có thể có nhiều sản phẩm, nhưng một sản phẩm cũng được xuất hiện trên nhiều đơn hàng, đây là ví dụ điển hình nhất của ánh xạ nhiều nhiều.
Ngoài ra, mô hình E-R còn tuân thủ một số khái niệm như sau:
Primary key (khóa chính)
Primary key là thuộc tính sử dụng để xác định tính duy nhất của một thực thể cho một tập thực thể. Trong cấu trúc CSDL, thông thường luôn nên có một cột sử dụng làm khóa chính trong bảng (tập thực thể).
Weak entity sets ( tập thực thể yếu)
Tập thực thể không có thuộc tính để xác định khóa chính được gọi là weak entity sets.
Strong entity sets (tập thực thể mạnh)
Tập thực thể có thuộc tính để xác định khóa chính được gọi là strong entity sets.
Entity relationship Diagram (Sơ đồ E-R)
Lược đồ E-R là một biểu diễn đồ họa của mô hình E-R. Trong lược đồ E-R, sử dụng các ký hiệu để thể hiện hiệu quả các thành phần khác nhau của mô hình E-R
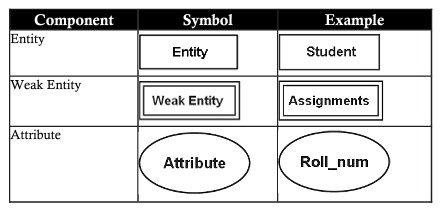
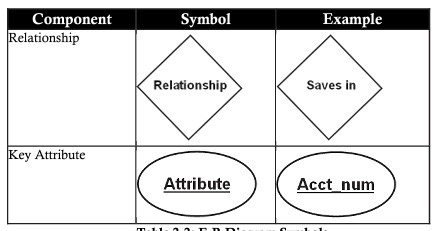
Thuộc tính trong mô hình E-R có thể được phân loại như sau:
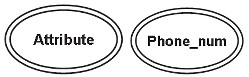
Multi-valued (đa trị)
Thuộc tính đa giá trị được minh họa bằng hình elip hai đường thẳng, có nhiều hơn một giá trị cho ít nhất một phiên bản của thực thể của nó. Thuộc tính này có thể có giới hạn trên và giới hạn dưới được chỉ định cho bất kỳ giá trị thực thể riêng lẻ nào.
Ví dụ, với thuộc tính phone_number có thể lưu trữ nhiều giá trị cho một thực thể. (Một người có thể có nhiều số điện thoại)
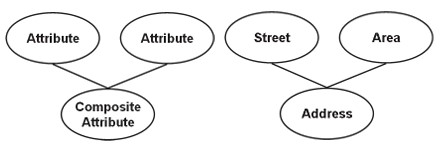
Composite (tổng hợp)
Bản thân một thuộc tính tổng hợp có thể chứa hai hoặc nhiều thuộc tính, các thuộc tính con là các thuộc tính cơ bản và có các ý nghĩa độc lập của riêng chúng.
Ví dụ: thuộc tính địa chỉ thường là thuộc tính tổng hợp, ví dụ khi biểu diễn một địa chỉ công ty mình 6/203 Trường Chinh – Thanh Xuân – HN thì 6/203 Trường Chinh sẽ là address, Thanh Xuân sẽ lưu tại District, HN là City
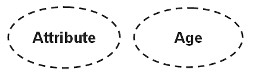
Derived ( thuộc tính dẫn xuất)
Thuộc tính dẫn xuất là các thuộc tính có giá trị hoàn toàn phụ thuộc vào một thuộc tính khác và được biểu thị bằng hình ellipse cấu tạo bởi các nét chấm lửng.
Thuộc tính tuổi của một người là ví dụ tốt nhất cho các thuộc tính có nguồn gốc. Đối với một thực thể người cụ thể, tuổi của một người có thể được xác định từ ngày hiện tại và ngày sinh của người đó.
Các bước để cấu trúc sơ đồ E-R như sau:
- Thu thập tất cả dữ liệu đã phải được mô hình hóa.
- Xác định dữ liệu có thể được mô hình hóa như các thực thể trong thế giới thực.
- Nhận dạng các thuộc tính cho mỗi thực thể.
- Sắp xếp các tập thực thể thành tập thực thể yếu hoặc mạnh.
- Sắp xếp các thuộc tính thực thể dưới dạng thuộc tính khóa, thuộc tính đa giá trị, thuộc tính tổng hợp, thuộc tính dẫn xuất, v.v.
- Xác định mối quan hệ giữa các yếu tố lôi kéo khác nhau.
- Sử dụng các ký hiệu khác nhau vẽ các yếu tố lôi kéo, thuộc tính của chúng và mối quan hệ của chúng. Sử dụng sysbols thích hợp trong khi vẽ các thuộc tính.
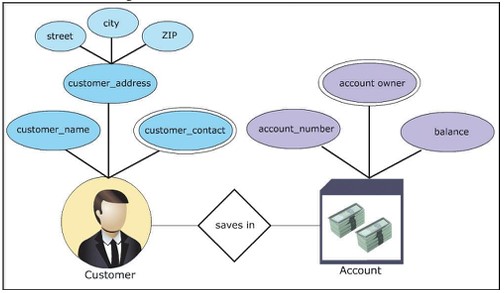
Ví dụ xây dựng CSDL mô phỏng một ngân hàng, với nghiệp vụ quản lý khách hàng và tài khoản. Biểu đồ E-R cho kịch bản có thể được xây dựng như sau:
- Thu thập dữ liệu: nghiệp vụ này cần danh sách các tài khoản và khách hàng muốn gửi tiền.
- Xác định thực thể: có 2 thực thể customer, account
- Xác định các thuộc tính:
- Customer: name,address,contact
- Account: id,owner,balance
- Sắp xếp tập thực thể
- customer: weak entity set
- account: strong entity set
- Sắp xếp thuộc tính
- customer entity set: address – compossite, contact – multi-valued
- accounet entity set: id – primary key, owner – multi-valued
- Xác định mối quan hệ: khách hàng gửi tiền trong tài khoản, mối quan hệ sẽ là “gửi tiền”
- đồ thị Vẽ mô hình E-R
Normalization ( chuẩn hóa dữ liệu )
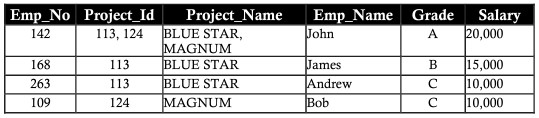
Thông thường, tất cả cơ sở dữ liệu được xác định bởi số lượng lớn các cột và bản ghi. Cách tiếp cận này có những hạn chế nhất định. Hãy xem xét ví dụ dưới đây khi lưu chữ chung 2 thực thể vào cùng một bảng sau đây của các nhân viên trong các dự án. Bao gồm các chi tiết của nhân viên cũng như các chi tiết của dự án mà họ đang làm việc:
Các khái niệm về những vấn đề gặp phải khi dữ liệu chưa chuẩn hóa như sau:
Repetition anomaly (lặp lại bất thường/dị thường)
Những cột như project_id, project_name, salary có dữ liệu ở các bản ghi lặp lại nhiều lần, sự lặp lại này cản trở cả hiệu suất trong quá trình truy xuất dữ liệu và dung lượng lưu trữ. Sự lặp lại dữ liệu này được gọi là repetition anomaly
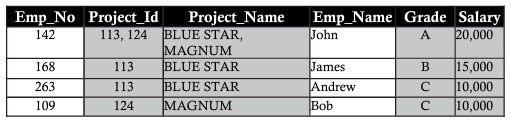
Insertion anomaly (chèn bất thường/dị thường)
Giả định thành viên mới của phòng ban là một nhân viên mới có tên Ann. Ann không được ấn định một dự án nào ngay bây giờ. Chèn chi tiết thông tin về cô ta trong bảng bị bỏ trống các ô trên cột có tên Project_id, Project_name. Việc để lại các cột trống dẫn đến một số vấn đề về sau. Sự dị thường đã tạo ra bởi thao tác chèn được gọi là insertion anomaly (chèn dị thường)
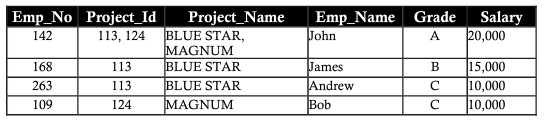
Deletion anomaly (xóa bất thường/dị thường)
Giả định Bob được lấy từ dự án MAGNUM. Xóa bản ghi dự án MAGNUM có tên nhân viên là Bob bao gồm mã số nhân viên (employee_number), cấp bậc (grade) và lương (salary). Việc mất dữ liệu gây ảnh hưởng đến chi tiết thông tin cá nhân của Bob, việc mất này có thể nhìn thấy trong bảng dưới. Dữ liệu bị mất do thao tác xóa như trên được gọi là deletion anomaly (xóa bất thường/dị thường).

Updating anomaly (cập nhật bất thuờng/dị thường)
Giả định John đã được tăng lương hoặc giảm lương. Việc thay đổi lương (salary) của John hoặc cấp bậc (grade) cần phải được phản ánh trong tất cả dự án mà John làm việc. này gọi là updating anomaly ( cập nhật dị thường ).
Bảng chi tiết các nhân viên trong phòng ban được gọi là bảng chưa được chuẩn hóa. Những hạn chế này cho thấy việc chuẩn hóa là cần thiết.
Nomarlization (chuẩn hóa dữ liệu) là một tiến trình bỏ đi sự dư thừa và sự phụ thuộc không mong đợi. Ban đầu, Codd (1972) đã mô tả ba dạng chuẩn hóa (1NF, 2NF và 3NF), tất cả dựa trên sự phụ thuộc giữa các thuộc tính của quan hệ. Dạng chuẩn bốn (4NF) và dạng chuẩn năm (5NF) dựa trên đa trị và kết hợp phụ thuộc và được giới thiệu sau đó.
First Normal Form (1NF)
Các bước để hoàn thành 1NF như sau:
- Tạo ra các bảng riêng biệt cho mỗi nhóm dữ liệu liên quan
- Các cột trong bảng cần lưu trữ các giá trị nguyên tố ( có thể hiểu giá trị nguyên thủy )
- Tất cả các thuộc tính primary key (khóa chính) cần được xác định
Xét ví dụ bảng phía trên, chúng ta cần chuẩn hóa lại bảng bằng cách chia rõ ra 2 thực thể project và employee
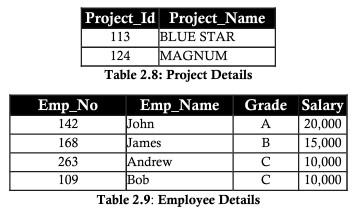
Second Normal Form (2NF)
Các bảng đợc gọi là 2NF nếu như thỏa mãn các yêu cầu:
- Đáp ứng yêu cầu của 1NF
- không có thành phần phụ thuộc nào trong các bảng
- Các bảng được liên kết với nhau thông qua khóa ngoại ( foreign keys )
Xét ví dụ phía trên, chúng ta sử dụng 2NF để liên kết giữa bảng project và bảng employee ( để biết dự án được gán cho nhân sự nào ) thông qua một bảng trung gian
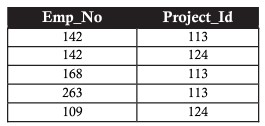
Third Normal Form (3NF)
Để hoàn thành chuẩn hóa 3NF cần thỏa mãn các yêu cầu sau:
- Bảng cần đáp ứng các yêu cầu của 2NF
- bảng không nên có các cột phụ thuộc nhau trong chúng
Tiếp tục xét ví dụ phía trên, ở bảng employee, chúng ta thấy cột Salary phụ thuộc vào cột Grade theo công thức chung: A – 20,000 | B – 15,000 | C – 10,000. Vì vậy, để chuẩn hóa dữ liệu này, chúng ta sẽ chia bảng employee ra, chỉ lưu trữ grade, và một bảng thể hiện grade và mức lương. Khi làm vậy, về sau, có thể thêm, cập nhật grade dễ dàng đáp ứng nhu cầu mà không bị ảnh hưởng tới dữ liệu chung.
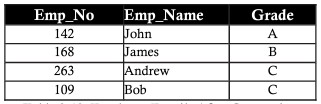
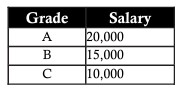

Denormalization (Phi chuẩn hóa dữ liệu)
Bằng việc chuẩn hóa dữ liệu, dữ liệu dư thừa sẽ đươc giảm thiểu. Có nghĩa là kích thước dung lượng lưu trữ CSDL cần thiết trong CSDL sẽ giảm đi. Tuy nhiên chúng cũng có một số hạn chế như sau:
- Các câu lệnh truy vấn sẽ trở nên phức tạp hơn khi kết nối dữ liệu giữa các bảng khác nhau
- Thực tế câu lệnh truy vấn có thể liên quan đến hơn 3 bảng tùy thuộc vào nhu cầu thông tin ( gia tăng độ phức tạp trong việc viết câu lệnh truy vấn, y/c lập trình viên hoặc DBA có truyên môn cao)
Nếu các câu lệnh truy vấn nối bảng sử dụng quá thuờng xuyên, hiệu năng của CSDL sẽ giảm, thời gian xử lý của CPU từ đó tăng lên khiến ảnh hưởng tới tốc độ chuonwg trình. Vì vậy, trong một số trường hợp, các dữ liệu dư thừa vẫn có thể đợc sử dụng để tăng hiệu năng cho CSDL, có nghĩa là chấp nhận việc lưu trữ dữ liệu dư thừa ( hy sinh dung lượng lưu trữ để tăng hiệu năng truy vấn), được gọi là denormalization (phi chuẩn hóa dữ liệu)
Relational Operators (Toán tử quan hệ)
mô hình quan hệ dựa trên nền tảng vững chắc của đại số quan hệ. Đại số quan hệ bao gồm một tập hợp các toán tử hoạt động trên các quan hệ. Mỗi toán tử nhận một hoặc hai quan hệ làm đầu vào của nó và tạo ra một quan hệ mới làm đầu ra. Xét bảng dữ liệu mẫu ngân hàng với các chi nhánh như sau:
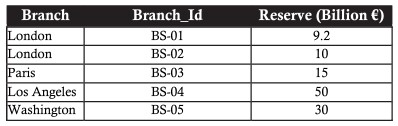
SELECT (phép chọn)
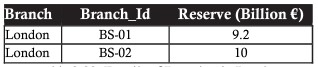
Toán tử SELECT dùng để truy xuất dữ liệu thỏa mãn các điều kiện yêu cầu. Ký tự xích ma (ð) được sử dụng để biểu diễn cho phép chọn.
Ví dụ dưới là bảng khi select ra các bản ghi có branch (chi nhánh) tại London
Hoặc một nghiệp vụ yêu cầu lấy ra những branch (chi nhánh) có reverse (dự trữ) lớn hơn 20 tỉ euro

PROJECT (phép chiếu)
Toán tử PROJECT được sử dụng để tham chiếu tới chi tiết của một bảng quan hệ. Toán tử PPROJECT chỉ hiển thị những trường yêu cầu, và bỏ các trường không yêu cầu trong cột. Toán tử PROJECT biểu diễn bằng ký tự pi “π”.
Ví dụ dưới sử dụng toán tử PROJECT để lấy ra id và reverse cho một nghiệp vụ không cần lấy branch name:
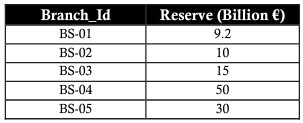
PRODUCT (phép nhân/tích)
Toán tử PRODUCT sử dụng để kết hợt thông tin từ 2 bảng liên quan với nhau, biểu diễn bằng ký tự “x”.
Ví dụ, chúng ta có bảng khoản vay như hình:

Sử dụng toán tử PRODUCT sử dụng để kết hợp giữa bảng branch và loan để biểu diễn tổng dự trữ lẫn tổng vay:
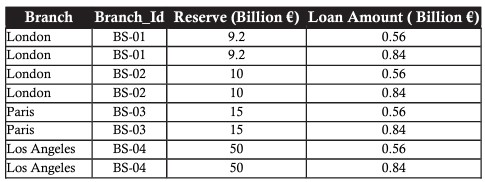
Phép nhân kết hợp mỗi bản ghi của bảng đầu tiên với tất cả các bản ghi trong bảng thứ hai, hay nói cách khác, nó tạo ra tất cả các kết hợp có thể có giữa các bản ghi của hai bảng.
UNION (phép kết hợp)
Giả định, với dữ liệu mẫu phía trên của ngân hàng, quản lý muốn muốn lấy ra những chi nhánh có dự trữ (reserve) hoặc khoản vay (loan) dưới 20 tỉ Euros. Bảng kết quả nên chứa những chi nhánh có dữ trữ hoặc khoản vay dưới 20 tỉ euro, hoặc cả 2 cột thỏa mãn điều kiện.
Phép này hình dung là việc kết hợp giữa 2 tập dữ liệu, các bước lần lượt hình dung như sau:
- Tập hợp những chi nhánh với dự dự trữ dưới 20 tỉ Euro
- Tập hợp những chi nhánh với khoản vay dưới 20 tỉ Eurro
- Gộp 2 tập hợp với nhau, đảm bảo rằng chi nhánh có dự trữ và khoản vay cùng dưới 20 tỉ Euro chỉ được xuất hiện một lần
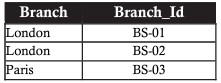
INTERSECT (Giao điểm)
Giả sử chúng ta muốn biết chi nhánh nào trong số những chi nhánh này có cả dự trữ và cho vay thấp. Giải pháp sẽ là sử dụng toán tử INTERSECT giao điểm. Toán tử INTERSECT tạo ra dữ liệu đúng trong tất cả các bảng mà nó được áp dụng. Nó dựa trên lý thuyết tập hợp giao điểm và được biểu diễn bằng ký hiệu “∩”. Kết quả sẽ là giiao điểm của 2 bảng bao gồm danh sách các chi nhánh đáp ứng cả 2 tiêu chí dự trữ và khooản vay cùng dưới 20 tỉ Euro.

DIFFERENCE (Phép hiệu)
Quay lại ví dụ trên, nếu chúng ta muốn biết chi nhánh nào có dự trữ thấp nhưng không có khooản vay, giải pháp là sử dụng phép hiệu (DIFFERENCE). Phép hiệu được ký hiệu bằng ký tự “-“, đầu ra của nó vẫn là kết hợp từ 2 bảng khác nhau, nhưng sự khác biệt là nó chỉ lấy ra giá trị đúng của một bảng, không có bảng còn lại, vì vậy những chi nhánh có dự trữ thấp nhunwg không có khoản vay sẽ không được lấy ra.

JOIN (Phép nối)
Phép nối là trường hợp mở rộng của phép nhân, nó cho phép lựa chọn kết quả của phép nhân. Ví dụ, nếu giá trị dự trữ và khoản vay của các chi nhánh nhỏ hơn với phép PRODUCT như trên, dữ liệu sẽ bị dư thừa, cần được tổng hợp và giản lược lại. Kết quả lấy ra của phép JOIN sẽ trả ra chỉ những chi nhánh mới được liệt kê có cả dự trữ dưới 20 tỷ euro và vốn vay

DIVIDE (Phép chia/thương)
Giả sử chúng ta lại muốn xem tene chi nhánh và dự trữ của tất cả các chi nhánh có khoản vay. Tình huống này cần sử dụng phép DIVIDE để xử lý. Tất cả tiến trình cần làm là chia bảng Branch Reverse Details (2.19) theo danh sách chi nhánh, và cột Branch_id của bảng BranchLoanDetails (2.23). Kết quả được như hình dưới

Lưu ý: các thuộc tính của bảng chia (divisor table) luôn luôn phải là tập hợp con của bảng bị chia (dividend table). Bảng kết quả luôn luôn bỏ trống các thuộc tính của bảng chia, và các bản ghi không khớp với các bản ghi trong bảng chia.
Bài tập
1.Cho bảng phía dưới:
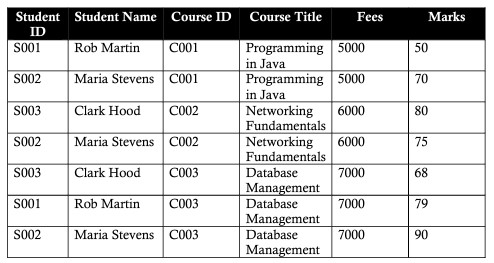
- Xác định vấn đề của bảg
- Đưa ra giải pháp cho vấn đề
2. Chuẩn hóa CSDL sau:

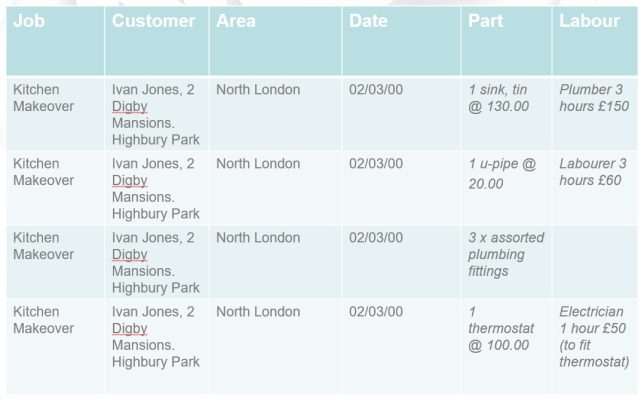
3. Thiết kế CSDL dựa vào dữ liệu thô sau

Bài viết liên quan:


Dịch vụ thiết kế Wesbite




