
Sử dụng K-fold validation đánh giá model hiệu quả hơn.
Việc training model không chỉ phụ thuộc vào mô hình bạn sử dụng, nó còn liên quan tới rất nhiều những thứ khác trong đó có số lượng của dữ liệu. Một dữ liệu khiêm tốn chắc chắn sẽ kiến cho việc đánh giá model thiếu hiệu quả. Như vậy K-fold cross validation là một tuyệt chiêu khá hay giúp chúng ta xử lý việc đó.
Mục lục
Sẽ như thế nào nếu đánh giá model với dữ liệu ít?
Chắc hẳn mọi người đã quen thuộc với cách chia dữ liệu train, valdiation và test đúng không?
Tạm thời bây giờ các bạn chỉ cần quan tâm tới Training set và val set thôi, còn test set chúng ta sẽ để đánh giá model sau kho train xong để xem model sẽ handle dữ liệu trong thực tế như thế nào.
Thông thường các bạn sẽ thấy chúng ta hay chia train/val theo tỉ lệ 80/20(80% dữ liệu train, 20% dữ liệu test). Việc chia như vậy khá tốt khi mà dữ liệu của chúng ta lớn. Còn đối với dữ liệu nhỏ chắc chắn sẽ khiến model của bạn hoạt động kém hiệu quả. Vì một số dữ liệu có ích cho quá trình train đã bị chúng ta ném vào làm validation, test do vậy model không học được từ những dữ liệu đó. Chưa tính đến nếu dữ liệu của chúng ta không đảm bảo tính random thì một số labels có trong validation và test nhưng không có trong training set. Và đương nhiên nếu đánh giá model dựa trên kết quả đó thì không tốt. Giống như ông không học toán mà bắt ông học machine learing.
Khi đó chúng ta cần tới K-Fold Cross Validation.
K Cross Validation là gì?
K-Flod CV sẽ giúp chúng ta đánh giá một model đầy đủ và chính xác hơn khi training set của chúng ta không lớn.
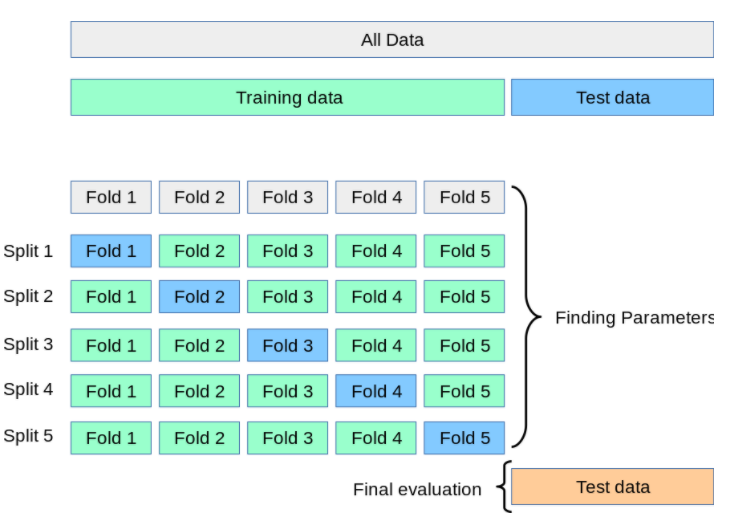
Phần dữ liệu training thì sẽ được chia thành K phần (K là một số nguyên thường khó quá thì chọn 10). Sau đó train model K lần, mỗi lần train sẽ chọn 1 phần làm dữ liệu validation và K-1 phần con lại làm training set. Kết quả cuối cùng sẽ là trung bình cộng kết quả đánh giá của K lần train. Đó cũng là lý do tại sao việc đánh giá này lại khách quan hơn.
Sau khi đánh giá xong mà thấy Accuracy ở mức “bạn chấp nhận” được thì bạn tiến hành predict với tập test data thôi.
Thực hành với Keras
Ok lý thuyết cơ bản đã xong. Giờ vào thực hành nào! Chúng ta sử dụng luôn bộ dữ liệu CIFAR10 trong keras để thực hành nha.
Import các thư viện.
from tensorflow.keras.datasets
import cifar10
from tensorflow.keras.models
import Sequential from tensorflow.keras.layers
import Dense, Flatten, Conv2D, MaxPooling2D from sklearn.model_selection
import KFold import numpy as np
Viết một hàm để load dữ liệu:
def load_data():
# Load dữ liệu CIFAR đã được tích hợp sẵn trong Keras
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# Chuẩn hoá dữ liệu
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_test = X_test / 255
X_train = X_train / 255 # Do CIFAR đã chia sẵn train và test nên ta nối lại để chia K-Fold
X = np.concatenate((X_train, X_test), axis=0)
y = np.concatenate((y_train, y_test), axis=0)
return X, y
Xây dựng model trong Keras nha
def get_model():
model = Sequential()
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(no_classes, activation='softmax')) # Compile model
model.compile(loss="sparse_categorical_crossentropy", optimizer="Adam", metrics=['accuracy'])
return model
Ta sử dụng luôn thư viện KFold của Sklearn để chia nha
kfold = KFold(n_splits=num_folds, shuffle=True)
# K-fold Cross Validation model evaluation
fold_idx = 1
for train_ids, val_ids in kfold.split(X, y):
model = get_model()
print("Bắt đầu train Fold ", fold_idx)
# Train model
model.fit(X[train_ids], y[train_ids], batch_size=batch_size, epochs=no_epochs, verbose=1) # Test và in kết quả
scores = model.evaluate(X[val_ids], y[val_ids], verbose=0) print("Đã train xong Fold ", fold_idx) # Thêm thông tin
accuracy và loss vào list accuracy_list.append(scores[1] * 100) loss_list.append(scores[0]) # Sang Fold tiếp theo
fold_idx = fold_idx + 1
Ý tưởng là chúng ta sẽ dùng KFold để lấy ra train index set và val index set tại mỗi fold, sau đó trích các phần tử theo index set đó đưa vào train, val cho phù hơn. Kết quả accuracy và loss sẽ được lưu lại vào list để hiển thị ttínhtrung bình cộng.
Tổng kết
Thay vì đánh giá model một cách phiên diện với train set và val set, chúng ta đã có thể đánh giá model hiệu quả hơn với K-Fold CV. Bên cạnh K-Fold CV các bạn có thể thử Stratified K-Fold, ông này ngon hơn do nó là mở rộng của K-Fold CV.
Bài viết liên quan:






Dịch vụ thiết kế Wesbite





