
Làm Việc Với Dữ Liệu Trong Ứng Dụng AZURE
Mục lục
Nhập Dữ liệu vào Azure
Việc nhập dữ liệu vào Azure bao gồm việc chuyển và tải dữ liệu từ các nguồn đa dạng vào lưu trữ hoặc các dịch vụ dữ liệu Azure. Quá trình này rất quan trọng để tổ chức có thể tận dụng các khả năng của Azure cho phân tích, lưu trữ và xử lý.
Quy trình Nhập Dữ liệu vào Azure
Quy trình hoàn chỉnh quản lý dữ liệu và nhập dữ liệu vào Azure như sau:
a. Xác định Nguồn Dữ liệu: Nhận diện các nguồn khác nhau như cơ sở dữ liệu, tệp tin, thiết bị IoT, nền tảng phát trực tuyến và những nơi khác chứa dữ liệu cần nhập vào Azure.
b. Chuẩn bị Dữ liệu và Biến đổi:
- Làm sạch, định dạng và biến đổi dữ liệu để đảm bảo khả năng tương thích với các dịch vụ Azure và mô hình dữ liệu đích.
- Giải quyết bất kỳ sự khác biệt cấu trúc hoặc không thống nhất nào giữa nguồn và đích.
c. Lựa chọn Phương pháp Nhập dữ liệu:
- Chọn phương pháp nhập dữ liệu phù hợp dựa trên các yếu tố như khối lượng dữ liệu, tốc độ, đa dạng và yêu cầu độ trễ.
- Lựa chọn các công cụ hoặc dịch vụ hỗ trợ các phương pháp nhập dữ liệu mong muốn một cách hiệu quả.
d. Phương pháp và Công cụ Nhập dữ liệu:
- Azure Data Factory: Cung cấp dịch vụ điều phối di chuyển dữ liệu và luồng công việc biến đổi trên nhiều nguồn và dịch vụ Azure.
- Azure Blob Storage và Azure Data Lake Storage: Hỗ trợ tải lên trực tiếp tệp hoặc dữ liệu từ nguồn trên nơi hoặc từ điện toán đám mây.
- Azure Event Hubs và Azure IoT Hub: Cho phép Nhập dữ liệu luồng thời gian thực cho các thiết bị IoT và các ứng dụng dựa trên sự kiện.
- Azure SQL Database Migration Service: Hỗ trợ di chuyển cơ sở dữ liệu sang Azure SQL Database với thời gian chết tối thiểu.
- Azure Data Box: Thiết bị vật lý được sử dụng để chuyển dữ liệu lớn một cách an toàn vào Azure.
e. Tương thích và Biến đổi Dữ liệu:
- Đảm bảo tính tương thích của dữ liệu bằng cách biến đổi định dạng, cấu trúc và schema khi cần thiết.
- Sử dụng các công cụ như Azure Data Factory hoặc Azure Databricks cho các nhiệm vụ biến đổi dữ liệu.
f. Xác thực và Giám sát Dữ liệu:
- Xác thực dữ liệu đã nhập để đảm bảo tính chính xác, đầy đủ và nhất quán.
- Triển khai cơ chế giám sát và nhật ký để theo dõi quá trình nhập dữ liệu và phát hiện các vấn đề hoặc lỗi.
g. Lưu trữ và Truy cập Dữ liệu:
- Lưu trữ dữ liệu đã nhập vào các dịch vụ Azure như Azure SQL Database, Azure Blob Storage, Azure Data Lake Storage, hoặc Azure Cosmos DB dựa trên yêu cầu cụ thể và các trường hợp sử dụng.
- Cấu hình quyền truy cập và các biện pháp bảo mật dữ liệu theo chính sách của tổ chức.
Nhập Dữ liệu vào Azure Data Explorer
Các yêu cầu tiên quyết để nhập hoặc tiêu thụ dữ liệu trong Azure Data Explorer như sau:
- Mở Azure Data Explorer, chọn My cluster, và điền các trường cần thiết để tạo một cluster. Tham khảo Hình bên dưới.
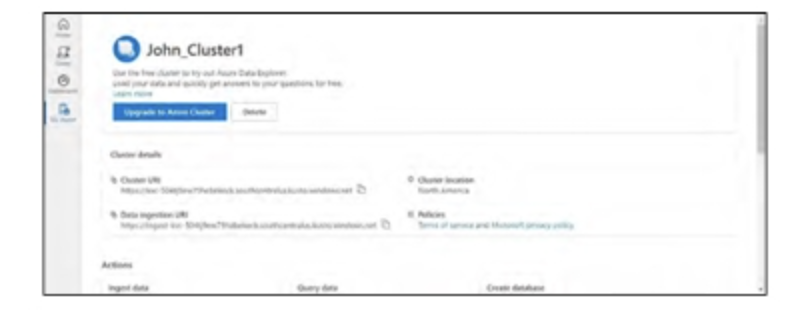
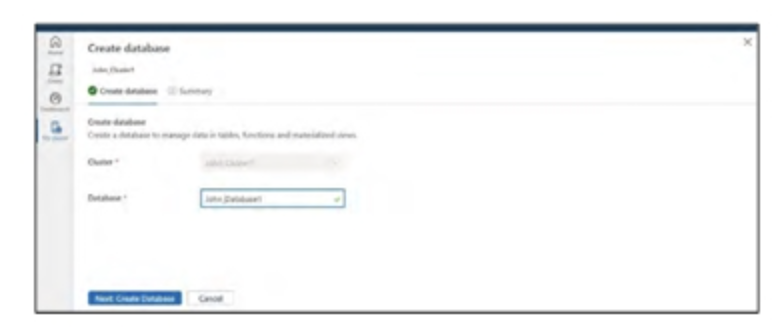
- Điều hướng đến ‘My cluster‘ và thiết lập một cluster đã tạo. Tham khảo Hình tiếp theo.
- Mở Azure Portal và tạo tài khoản lưu trữ. Tham khảo 2 hình ảnh bên dưới.
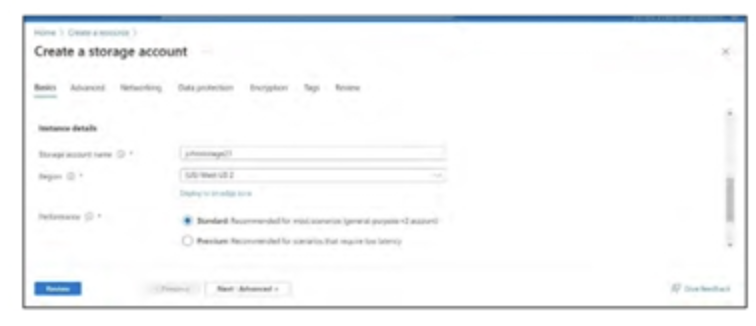
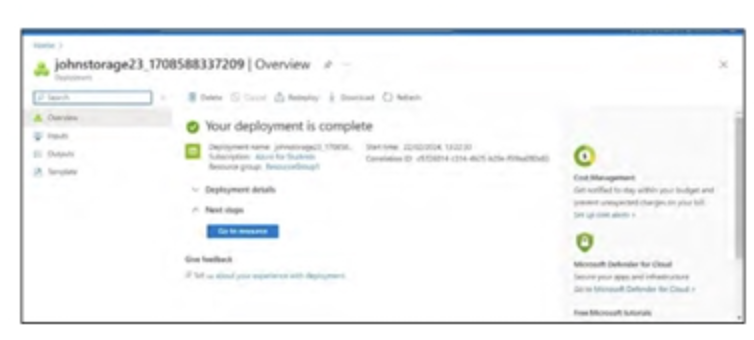
Bây giờ, quá trình nhập dữ liệu vào Azure Data Explorer có thể được bắt đầu.
Bước 1: Khởi động Azure Data Explorer và điều hướng đến phần Query ở phía trái. Nhấp chuột phải vào cơ sở dữ liệu đã được tạo trước đó. Giao diện người dùng tương tự như Hình bên dưới sẽ xuất hiện. Chọn “Lấy dữ liệu”.
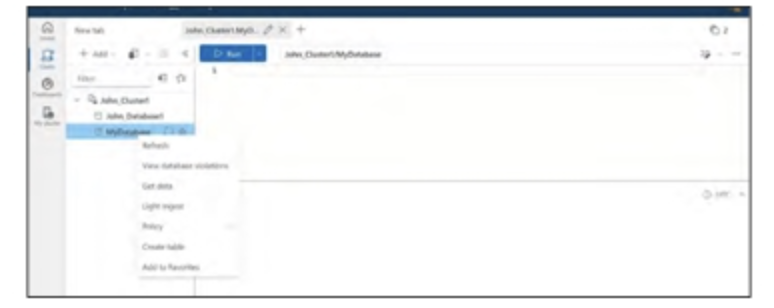
Bước 2: Chọn nguồn dữ liệu cho quá trình nhập dữ liệu. Trong trường hợp này, chọn “Tệp địa phương”. Tham khảo Hình tiếp theo.
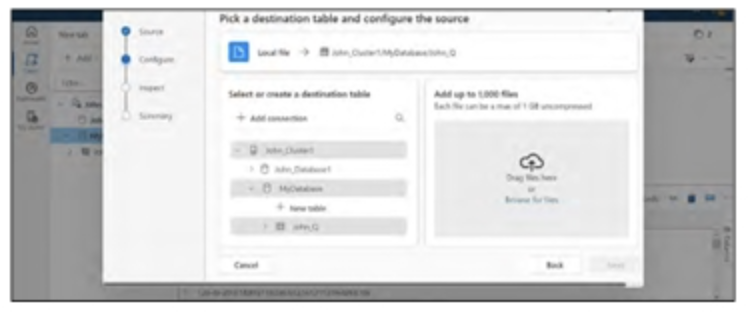
Bước 3: Nhấp vào “Bảng mới” và gán một tên phù hợp cho bảng của bạn. Kéo hoặc tải lên dữ liệu bên phải và tiếp tục bằng cách nhấp chuột. Tham khảo Hình tiếp theo để có hướng dẫn hình ảnh.
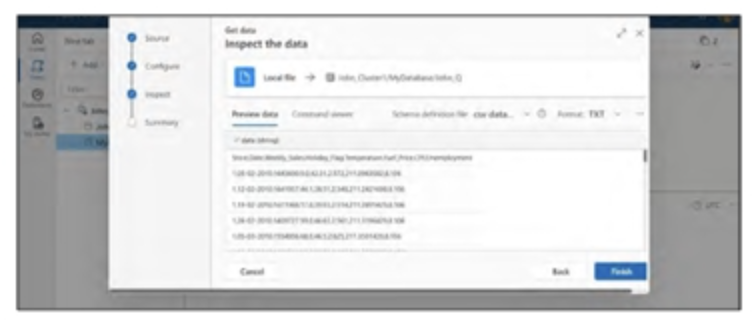
Bước 4: Xác nhận xem trước dữ liệu để đảm bảo rằng dữ liệu chính xác đã được tải lên. Nếu đúng, nhấp vào “Hoàn thành”. Nếu không, nhấp vào “Back” và lặp lại bước trước đó. Tham khảo Hình bên dưới.
Sau khi nhập dữ liệu thành công, một giao diện giống như Hình tiếp theo
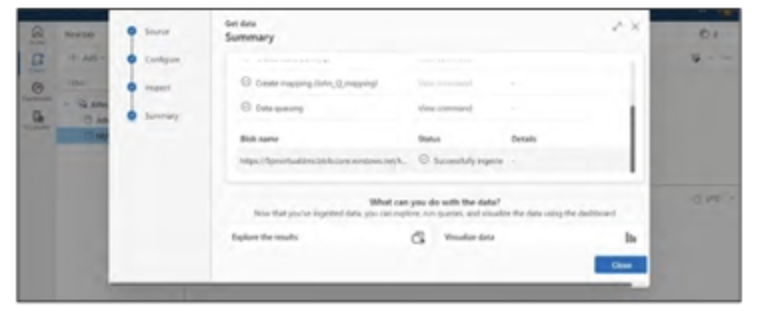
Bước 5: Để kiểm tra dữ liệu đã nhập, hãy nhấp vào tên bảng (trong trường hợp này là John_Q’) và chọn Chạy, như minh họa trong Hình bên dưới.
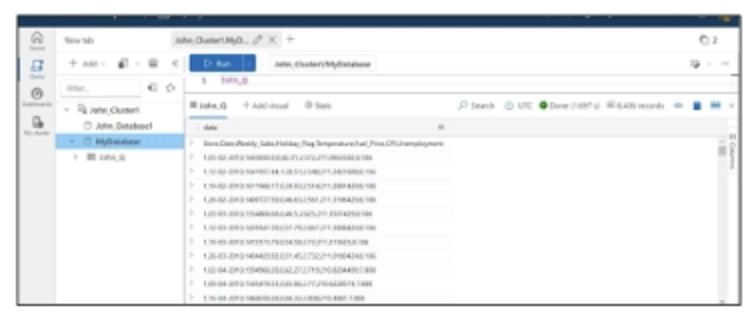
Tương tự, các nhà phát triển có thể xem xét việc nhập dữ liệu từ các nguồn dữ liệu khác vào Azure Data Explorer ngoài các tệp cục bộ, như đã được trình bày trong ví dụ trước.
Dịch vụ dữ liệu Azure
Azure Data Service là một dịch vụ được quản lý mở rộng nền tảng với các khả năng chung (chức năng chia sẻ). Do tầm quan trọng của dữ liệu trong thế giới kỹ thuật số ngày nay, nó là một dịch vụ riêng biệt và tách biệt với việc xây dựng các khối 4 GB của các ứng dụng Azure.
- Lưu trữ: Danh mục này chứa tổng cộng năm dịch vụ khác nhau. Lưu trữ Blob (lưu trữ dữ liệu không cấu trúc), lưu trữ bảng (lưu trữ NoSQL dựa trên cặp khóa-giá trị), lưu trữ hàng đợi (cho xử lý tin nhắn), lưu trữ tệp và lưu trữ đĩa (lưu trữ cao cấp).
- Cơ sở dữ liệu SQL dưới dạng dịch vụ: Danh mục này bao gồm ba cơ sở dữ liệu được quản lý hoàn toàn dưới dạng dịch vụ: SQL Server, MySQL và PostgreSQL. Danh mục này cũng bao gồm các đề xuất đặc biệt như SQL Server DWH, SQL Server Stretch DB và SQL Server Elastic DB. Tất cả các đề xuất đặc biệt là sự phát triển thêm của SQL Server dưới dạng dịch vụ và giải quyết các khối lượng công việc cụ thể trên đám mây.
- Cơ sở dữ liệu NoSQL dưới dạng dịch vụ: Danh mục này bao gồm các cơ sở dữ liệu NoSQL được quản lý hoàn toàn bởi các dịch vụ như Azure CosmosDB. Các cơ sở dữ liệu NoSQL được sử dụng để lưu trữ dữ liệu bán cấu trúc. Các cơ sở dữ liệu NoSQL tách biệt việc lưu trữ cặp khóa-giá trị, lô và dữ liệu tài liệu. Các nhà phát triển có thể chỉ định loại lưu trữ để sử dụng khi tạo cơ sở dữ liệu.
- Dữ liệu lớn: Danh mục này bao gồm việc triển khai Apache Hadoop được quản lý hoàn toàn với Azure HDInsight. Ngoài ra, các triển khai cho Apache Storm, Apache Spark, Apache Kafka và Microsoft R Server (với các mức độ phát triển khác nhau) cũng có sẵn.
- Phân tích: Danh mục này bao gồm các công cụ phân tích dữ liệu như Azure Stream Analytics, Azure Data Lake Analytics và Azure Data Factory.
- AI: Danh mục này bao gồm các dịch vụ Azure Machine Learning (Azure ML) được quản lý hoàn toàn, giúp dễ dàng xây dựng, triển khai và chia sẻ các giải pháp phân tích dự đoán, và một số giải pháp có sẵn ngay lập tức (Microsoft Cognitive Services).
- Trực quan hóa: Danh mục này là một trường hợp đặc biệt vì dịch vụ được cung cấp (Microsoft Power BI) chỉ là một dịch vụ Azure dưới dạng SaaS.
Azure SQL Database
Azure SQL Database là một dịch vụ cơ sở dữ liệu đám mây được quản lý bởi Microsoft như một phần của các dịch vụ Azure. Nó hoạt động như một nền tảng dưới dạng dịch vụ (PaaS), đảm nhiệm các công việc quản lý cơ sở dữ liệu như nâng cấp, vá lỗi, sao lưu và giám sát mà không cần sự can thiệp của người dùng. Nó hỗ trợ lưu trữ đa dạng cho dữ liệu có cấu trúc, bán cấu trúc và phi quan hệ. Nó tích hợp trí tuệ nhân tạo để học các mẫu ứng dụng, tối ưu hóa hiệu suất, độ tin cậy và bảo vệ dữ liệu.
Các khả năng chính của nó bao gồm:
- Học và thích ứng với các mẫu truy cập dữ liệu của ứng dụng chủ để cải thiện hiệu suất và độ tin cậy.
- Cho phép mở rộng theo yêu cầu.
- Quản lý và giám sát các ứng dụng đa khách hàng, cung cấp lợi ích cô lập với một khách hàng mỗi cơ sở dữ liệu.
- Tích hợp với các công cụ mã nguồn mở như cheetah, SQL-CLI, Visual Studio Code, cũng như các công cụ của Microsoft như Visual Studio, SQL Server Management Studio, Azure Management Portal, PowerShell và REST APIs.
- Đảm bảo bảo vệ dữ liệu thông qua mã hóa, xác thực, kiểm soát truy cập, giám sát liên tục và kiểm tra.
Microsoft Azure Cosmos DB
Microsoft Azure Cosmos DB cung cấp dịch vụ cơ sở dữ liệu trên toàn thế giới. Nó cho phép quản lý dữ liệu, được lưu trữ trong các trung tâm dữ liệu trên khắp toàn cầu. Nó cũng cung cấp các công cụ cần thiết để mở rộng cả tài nguyên tính toán cũng như các mô hình phân phối toàn cầu.
Dưới đây là một số tính năng:
- Hỗ trợ các mô hình tài liệu, cặp khóa-giá trị, quan hệ và đồ thị sử dụng một backend
- Không dựa vào bất kỳ sơ đồ nào
- Sử dụng ngôn ngữ truy vấn tương tự SQL
- Hỗ trợ giao dịch ACID Cosmos được phân loại là một loại cơ sở dữ liệu NewSQL vì nó sử dụng ngôn ngữ truy vấn và cũng hỗ trợ giao dịch ACID. Tuy nhiên, nó không bao gồm một mô hình dữ liệu quan hệ. Dưới đây là một số lợi ích của nó:
- Dịch vụ hoàn chỉnh và sẵn sàng sử dụng
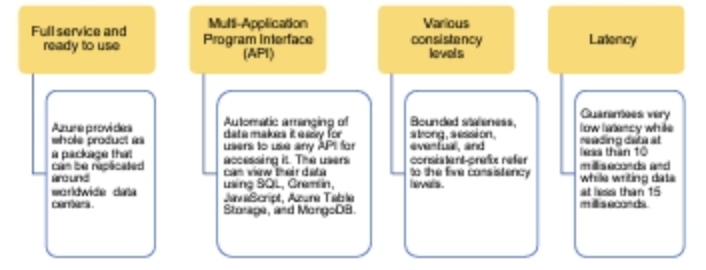
- Hỗ trợ nhiều Giao diện Lập trình Ứng dụng (API)
- Các mức độ nhất quán khác nhau
- Độ trễ thấp Azure cung cấp toàn bộ sản phẩm dưới dạng một gói có thể được nhân bản trên toàn cầu. Việc sắp xếp dữ liệu tự động giúp người dùng dễ dàng sử dụng bất kỳ phương thức truy cập nào. Người dùng có thể xem dữ liệu của mình sử dụng SQL, Gremlin, JavaScript, Azure Table Storage và MongoDB. Có năm mức độ nhất quán bao gồm: mạnh, bị ràng buộc, tiền tố nhất quán, cuối cùng và Đảm bảo độ trễ rất thấp khi đọc dữ liệu dưới 10 mili giây và khi ghi dữ liệu dưới 15 mili giây.
Azure Data Lake Storage
Azure Data Lake Storage (ADLS), hay Azure Data Lake Store, là một nền tảng an toàn và có khả năng mở rộng cho các khối lượng công việc phân tích hiệu suất cao. Nó cung cấp lưu trữ phân cấp tiết kiệm chi phí, quản lý chính sách và tương thích với các công cụ Hệ thống Tệp Phân tán Hadoop (HDFS). ADLS đảm bảo an ninh với đăng nhập một lần và kiểm soát truy cập. Điều này làm cho nó trở thành một giải pháp đáng tin cậy để tích hợp và quản lý khối lượng lớn dữ liệu của tổ chức một cách liền mạch.
Sau đây là một số tính năng:

Azure Synapse Analytics
Azure Synapse là một công cụ giúp các công ty hiểu dữ liệu của họ nhanh chóng. Nó kết hợp các công nghệ mạnh mẽ để tổ chức dữ liệu lớn và cơ sở dữ liệu truyền thống. Nó bao gồm các tính năng như Data Explorer để phân tích nhật ký và dữ liệu theo thời gian, các pipeline để di chuyển và chuyển đổi dữ liệu mượt mà. Nó dễ dàng kết nối với các dịch vụ khác của Microsoft như Power BI, Cosmos DB và Azure ML. Đây là một giải pháp tổng hợp cho doanh nghiệp để có được những hiểu biết sâu sắc từ dữ liệu của họ mà không gặp rắc rối.
Một số tính năng của nó bao gồm:
- Khả năng mở rộng không giới hạn cho thông tin nhanh chóng: Đạt được thông tin nhanh chóng từ các nguồn dữ liệu đa dạng bao gồm kho dữ liệu và các hệ thống phân tích dữ liệu lớn.
- Nâng cao ứng dụng thông minh với AI: Chuyển đổi dữ liệu thành những hiểu biết mạnh mẽ sử dụng các mô hình học máy để nâng cao các ứng dụng thông minh.
- Phát triển phân tích thống nhất: Đơn giản hóa việc phát triển với trải nghiệm thống nhất, giảm đáng kể thời gian dự án cho các giải pháp phân tích từ đầu đến cuối.
- An ninh và quyền riêng tư tiên tiến: Hưởng các tính năng an ninh tiên tiến, bao gồm bảo mật mức cột và mức hàng, và che giấu dữ liệu động.

Azure Databricks
Azure Databricks là một nền tảng phân tích thống nhất được thiết kế để phát triển, triển khai và quản lý các giải pháp dữ liệu, phân tích và AI cấp doanh nghiệp ở quy mô lớn. Nó quản lý triển khai cơ sở hạ tầng trên tài khoản đám mây của bạn một cách hiệu quả, khi được tích hợp với lưu trữ và bảo mật đám mây. Nền tảng cung cấp các công cụ để kết nối liền mạch các nguồn dữ liệu, cho phép xử lý, lưu trữ, phân tích và kiếm tiền từ các tập dữ liệu, hỗ trợ các giải pháp từ BI đến AI sinh tạo.
Một số tính năng của nó bao gồm:
Ứng dụng của các cơ sở dữ liệu Azure khác nhau
Các ứng dụng của các cơ sở dữ liệu Azure khác nhau đã được nêu trong bảng bên dưới cùng với các điểm mạnh cụ thể và các kịch bản mà chúng nổi trội.
| Dịch vụ cơ sở dữ liệu | Ứng dụng | Điểm mạnh | Kịch bản |
| Azure SQL Database | Ứng dụng web, ứng dụng SaaS, ứng dụng giao dịch | Dịch vụ quản lý, khả năng mở rộng, tính sẵn sàng cao, trí tuệ tích hợp, bảo mật | Ứng dụng OLTP (Xử lý giao dịch trực tuyến), ứng dụng kinh doanh cần sự nhất quán trong giao dịch |
| Azure Cosmos DB | Ứng dụng IoT, ứng dụng game, ứng dụng web và di động | Phân phối toàn cầu, hỗ trợ đa mô hình, độ trễ thấp, khả năng mở rộng đàn hồi | Ứng dụng cần độ sẵn sàng cao và độ trễ thấp, đọc và ghi đa vùng |
| Azure Blob Storage | Sao lưu và khôi phục, khắc phục thảm họa, phân tích dữ liệu lớn, lưu trữ và phân phối nội dung | Quy mô lớn, chi phí thấp, các cấp truy cập linh hoạt, tích hợp với các công cụ phân tích dữ liệu lớn | Lưu trữ dữ liệu không có cấu trúc, tệp phương tiện, và các tập dữ liệu lớn |
| Azure Data Lake Storage | Phân tích dữ liệu lớn, học máy, quản lý dữ liệu IoT | Tương thích HDFS, thông lượng cao, tích hợp với các công cụ phân tích dữ liệu lớn | Các dự án phân tích nâng cao và học máy, xử lý dữ liệu quy mô lớn |
| Azure Synapse Analytics | Kho dữ liệu, phân tích dữ liệu lớn, phân tích nâng cao | Trải nghiệm hợp nhất, khả năng mở rộng vô hạn, tích hợp với các dịch vụ Azure khác | Các khối lượng công việc kho dữ liệu và phân tích phức tạp, tích hợp dữ liệu có cấu trúc và không có cấu trúc |
| Azure Databricks | Kỹ thuật dữ liệu, khoa học dữ liệu, học máy, phân tích dữ liệu | Nền tảng phân tích hợp nhất, khả năng mở rộng, tối ưu hóa cho Azure | Phát triển và triển khai các giải pháp phân tích dữ liệu và AI quy mô lớn |
| Azure Table Storage | Lưu trữ dữ liệu có cấu trúc, phi quan hệ, như hồ sơ người dùng, sổ địa chỉ, thông tin thiết bị | Đơn giản và tiết kiệm chi phí, có khả năng mở rộng, không có cấu trúc | Ứng dụng cần kho NoSQL để lưu trữ dữ liệu bán cấu trúc |
| Azure Queue Storage | Hàng đợi tin nhắn để xử lý luồng công việc, tin nhắn không đồng bộ giữa các thành phần ứng dụng | Đơn giản, đáng tin cậy, có khả năng mở rộng | Tách biệt các thành phần ứng dụng để cải thiện khả năng mở rộng và độ tin cậy |
| Azure SQL Database Hyperscale | Ứng dụng hiệu suất cao cần mở rộng nhanh chóng, tập dữ liệu lớn | Khả năng mở rộng cao, sao lưu và khôi phục nhanh, hiệu suất đọc và ghi nhanh | Ứng dụng có yêu cầu mở rộng động và cơ sở dữ liệu lớn |
| Azure Cache for Redis | Bộ nhớ đệm dữ liệu truy cập thường xuyên, lưu trữ phiên, tin nhắn pub/sub | Độ trễ thấp, thông lượng cao, được quản lý toàn diện | Cải thiện hiệu suất ứng dụng, giảm tải cơ sở dữ liệu, xử lý dữ liệu theo thời gian thực |
Dịch Vụ Lưu Trữ Tạm Thời Dữ Liệu Trong Azure
Dữ liệu được lưu trữ ở đâu đó từ xa được lưu trữ cục bộ để sử dụng thường xuyên thông qua một kỹ thuật gọi là caching (lưu trữ tạm thời). Dữ liệu này có thể được tái sử dụng nhanh chóng khi cần thiết. Lưu trữ tạm thời tránh việc lặp đi lặp lại quá trình lấy cùng một dữ liệu từ máy chủ và thực hiện cùng một logic nhiều lần trong trường hợp có yêu cầu từ người dùng.
Caching giúp cải thiện hiệu suất thông qua các cách sau:
- Giảm lưu lượng mạng [gọi HTTP đến máy chủ]
- Giảm số lần vòng quay đến máy chủ [máy chủ lưu trữ hoặc máy chủ cơ sở dữ liệu hoặc bất kỳ máy chủ nào khác]
- Đảm bảo không sử dụng lại logic ràng buộc dữ liệu
Lưu Trữ Tạm Thời Nội Dung Tĩnh
Nội dung tĩnh thường được sử dụng để thiết kế bất kỳ trang web nào. Nội dung tĩnh là những nội dung không thay đổi động như hình ảnh, tệp CSS và JavaScript. Nếu các tệp này lớn, chúng có thể tiêu tốn khoảng 60% tổng thời gian tải từ máy chủ. Việc tải mất nhiều thời gian hơn khi nội dung tĩnh nhiều.
Để chia sẻ dữ liệu chung với nhiều phương thức hành động và thêm loại dữ liệu này vào cache, các nhà phát triển nên sử dụng HttpContext.Cache để thiết lập hoặc lấy dữ liệu. Quá trình tải xuống chỉ xảy ra lần đầu tiên. Trong ASP.NET MVC, có thể bộ nhớ đệm các nội dung tĩnh đã tải xuống. Nội dung này được lưu trữ trong bộ nhớ và khi người dùng truy cập lại cùng trang đó, bộ nhớ đệm sẽ cung cấp nội dung.
Chính Sách Cache
Chính sách cache là một tập hợp các quy tắc xác định liệu có thể sử dụng bản sao được lưu trong bộ nhớ đệm của tài nguyên yêu cầu cho một yêu cầu cụ thể hay không. Yêu cầu cache của khách hàng được chỉ định trong các ứng dụng, nhưng một chính sách cache hiệu quả được xác định bởi các yếu tố sau:
- Yêu cầu cache của khách hàng
- Yêu cầu hết hạn nội dung của máy chủ
- Yêu cầu tái xác thực của máy chủ
Sử dụng chính sách cache của khách hàng và yêu cầu của máy chủ, có thể đảm bảo rằng đạt được chính sách cache bảo thủ nhất. Điều này đảm bảo rằng khách hàng nhận được nội dung cập nhật nhất.
Bao Gồm Các Chính Sách Hết Hạn
Dữ liệu cache thường là tạm thời. Chính sách hết hạn cache đại diện cho một tập hợp các chi tiết về trục xuất và hết hạn cho một mục cache cụ thể. Có hai loại chính sách hết hạn dành cho cache, như sau:
- Hết Hạn Tuyệt Đối (Absolute Expiration): Xác định thời gian cố định cho hiệu lực của cache và mục sẽ hết hạn sau thời gian đó.
- Hết Hạn Trượt (Sliding Expiration): Tự động gia hạn thời gian hết hạn cho một mục cache dựa trên các mẫu truy cập.

Đoạn mã bên dưới đại diện cho việc cache danh sách sinh viên trong 23 giờ và 59 phút. Sau khi hoàn thành thời gian, cache sẽ được làm mới và sẽ được gán lại.
private const string studentKey = "studentListCacheKey";
CacheItemPolicy cachePolicy = new CacheItemPolicy();
cachePolicy.AbsoluteExpiration = DateTime.Now.AddHours(23).AddMinutes(59);
cache.Add(studentKey, studentList, cachePolicy);
Sử Dụng Phụ Thuộc Cache
Hiệu lực của một mục cache dựa trên các phụ thuộc cache. Nó dựa trên một tệp hoặc thư mục trên máy chủ web hoặc một mục cache khác. Bất kỳ thay đổi nào trong đối tượng phụ thuộc sẽ làm vô hiệu hóa và loại bỏ mục cache tự động.
Phụ thuộc được tạo ra bằng cách đầu tiên tạo một đối tượng CacheDependency. Đối tượng này đề cập đến tệp, thư mục hoặc mục cache mà phụ thuộc sẽ dựa vào. Phương thức Cache.Insert() được sử dụng để thêm mục cache phụ thuộc. Đối tượng CacheDependency được sử dụng làm tham số.
Bảng bên dưới dưới đây liệt kê ba loại phụ thuộc cache.
| Loại Phụ Thuộc Cache | Mô Tả |
| Phụ thuộc cache vào các mục cache khác | Chỉ ra sự phụ thuộc của các mục cache vào các mục cache khác. Ví dụ, loại bỏ mục X khỏi cache sẽ cho phép loại bỏ mục Y khỏi cache. |
| Phụ thuộc cache vào một tệp | Chỉ ra rằng cache phụ thuộc vào một tệp. Bất kỳ cập nhật nào trong nội dung tệp sẽ dẫn đến việc hết hạn cache và nạp lại nội dung. |
| Phụ thuộc cache vào SQL | Chỉ ra rằng cho đến khi các mục trong bảng không thay đổi, dữ liệu sẽ có trong cache. Bất kỳ thay đổi nào đối với nội dung sẽ làm hết hạn cache. Phụ thuộc cache SQL được kích hoạt bằng cách sử dụng công cụ dòng lệnh aspnet_regsql.exe. |
Thông Báo Truy Vấn Trong ADO.NET
Bất kỳ thay đổi nào trong dữ liệu sẽ thông báo cho ứng dụng. Điều này được gọi là thông báo truy vấn. Điều này thường được sử dụng khi các ứng dụng cung cấp một cache thông tin từ cơ sở dữ liệu và được thông báo khi có thay đổi trong dữ liệu nguồn. Ví dụ, một ứng dụng web.
ADO.NET giúp thực hiện thông báo truy vấn bằng cách sử dụng các lớp sau.
Sử Dụng Giao Dịch
Giao dịch là một đơn vị công việc đơn lẻ có nghĩa là tất cả hoặc không có gì được thực hiện. Nếu giao dịch chạy suôn sẻ, tất cả các thao tác dữ liệu sẽ được thực hiện và kết quả của chúng sẽ được ghi vào cơ sở dữ liệu. Nếu có lỗi hoặc ngoại lệ, giao dịch đó phải được hoàn nguyên. Nếu điều này xảy ra, tất cả các thay đổi hoặc thao tác dữ liệu sẽ được rút lại và không có thao tác nào được thực hiện.
Các Tính Chất của Giao Dịch
Một giao dịch có bốn tính chất tiêu chuẩn, thường được gọi bằng từ viết tắt ACID:
- Tính nguyên tử (Atomicity): Đảm bảo hoàn thành công việc một cách thành công và các thao tác đã thực hiện. Nếu giao dịch thất bại, các thao tác sẽ được hoàn nguyên về trạng thái trước đó.
- Tính nhất quán (Consistency): Đảm bảo rằng khi một giao dịch thành công, trạng thái của cơ sở dữ liệu thay đổi.
- Tính độc lập (Isolation): Đảm bảo các giao dịch hoạt động một cách độc lập và trong suốt.
- Tính bền vững (Durability): Đảm bảo rằng khi hệ thống gặp sự cố, giao dịch đã cam kết vẫn còn tồn tại.

Giao Dịch Cơ Sở Dữ Liệu
Bất kỳ giao dịch nào trong phát triển phần mềm đều liên quan đến giao dịch cơ sở dữ liệu. Trong loại giao dịch này, các câu lệnh thao tác dữ liệu (Insert/update/delete) được thực hiện cùng nhau. Mỗi câu lệnh hoặc thực hiện thành công hoặc thất bại. Điều này đảm bảo rằng cơ sở dữ liệu ở trạng thái nhất quán. Bất kỳ thay đổi nào trong trạng thái cơ sở dữ liệu đều được biểu diễn bằng một giao dịch cơ sở dữ liệu.
Giao Dịch Cục Bộ
Trên một nguồn dữ liệu/cơ sở dữ liệu duy nhất, một loạt các câu lệnh thao tác dữ liệu được thực hiện cùng nhau. Điều này được gọi là giao dịch cục bộ. Loại giao dịch này được thực hiện trực tiếp bởi cơ sở dữ liệu và là một giai đoạn duy nhất. Một Trình Quản Lý Giao Dịch Nhẹ (LTM) được cung cấp bởi System.Transactions để quản lý loại giao dịch này. Nó hoạt động như một gateway trong giao dịch. System.Transactions bắt đầu và xử lý tất cả các giao dịch. Bất kỳ thay đổi/rào cản nào trong bản chất của giao dịch do các quy tắc định trước, giao dịch phân phối sẽ nhận được một fallback từ Microsoft Distributed Transaction Coordinator (MSDTC).
Giao Dịch Phân Tán trong SQL Azure
Một số giao dịch bao gồm hơn một nguồn dữ liệu. Điều này được gọi là giao dịch phân tán hoặc giao dịch đàn hồi. Tất cả các nguồn dữ liệu bị ảnh hưởng sẽ được giảm thiểu trong trường hợp giao dịch thất bại. Microsoft Distributed Transaction Coordinator (MSDTC) sử dụng các cơ chế có sẵn trong System.Transactions để quản lý các giao dịch phân tán trên đám mây. Một quy trình cam kết hai giai đoạn được thực hiện để duy trì tính nguyên tử trên các cơ sở dữ liệu.
Giao Dịch Cơ Sở Dữ Liệu Đàn Hồi với Azure SQL Database
Một số giao dịch sử dụng nhiều cơ sở dữ liệu trong SQL DB. Trong Azure SQL DB, các giao dịch cơ sở dữ liệu đàn hồi cho phép một ứng dụng .NET sử dụng ADO.NET để sử dụng các giao dịch cơ sở dữ liệu cho SQL DB.
Sử Dụng Namespace System.Transactions
ADO.NET được liên kết với framework System.Transactions. Để thực hiện một giao dịch phân tán, không có sự thay đổi nào.
Tuy nhiên, một đối tượng TransactionScope được khởi tạo để tạo một giao dịch. Nội bộ, trong constructor của nó, một giao dịch được tạo bởi đối tượng TransactionScope và được gán cho thuộc tính System.Transactions.Transaction.Current. Loại giao dịch này được gọi là giao dịch hiện tại hoặc giao dịch môi trường. TransactionScope đại diện cho một đối tượng có thể hủy bỏ. Khi phương thức Dispose() được gọi, giao dịch này kết thúc.
Để trở thành một phần của giao dịch, các kết nối ADO.NET phải được mở sau khi đối tượng TransactionScope được khởi tạo và trước khi nó bị hủy. Điều này thường được quan sát khi mở các kết nối cơ sở dữ liệu đơn lẻ hoặc nhiều.
Giao dịch sẽ vẫn được cam kết nếu phương thức TransactionScope.Complete() được gọi trước khi phương thức Dispose(). Nếu không, giao dịch sẽ bị hủy bỏ.
Đoạn mã bên dưới hiển thị một ví dụ về việc sử dụng System.Transactions. Một giao dịch trong luồng hiện tại được gọi là giao dịch môi trường. Một giao dịch môi trường được mở bởi lớp TransactionScope. Giao dịch này liên quan đến tất cả các kết nối được mở trong phạm vi của TransactionScope. Một giao dịch phân tán xảy ra khi nhiều cơ sở dữ liệu tham gia. Phạm vi được đặt là complete để kiểm soát kết quả của giao dịch. Điều này chỉ ra một sự cam kết.
using (var scope = new TransactionScope()) {
using (var conn1 = new SqlConnection(connStrDb1)) {
conn1.Open();
SqlCommand cmd1 = conn1.CreateCommand();
cmd1.CommandText = "INSERT INTO T1 values(1)";
cmd1.ExecuteNonQuery();
}
using (var conn2 = new SqlConnection(connStrDb2)) {
conn2.Open();
var cmd2 = conn2.CreateCommand();
cmd2.CommandText = "INSERT INTO T2 values(2)";
cmd2.ExecuteNonQuery();
}
scope.Complete();
}
Mức Cô Lập Giao Dịch
Một cơ chế khóa cô lập một giao dịch khỏi giao dịch khác. Cơ chế khóa này được giới thiệu bởi Hệ Thống Quản Lý Giao Dịch. Hành vi của chính sách khóa này phụ thuộc vào mức độ cô lập được đặt cho mỗi giao dịch. Dưới đây là bốn mức độ cô lập quan trọng:
- Serializable: Đây là mức độ cô lập cao nhất. Trong quá trình đọc và ghi, dữ liệu bị khóa độc quyền. Để ngăn chặn sự tạo ra các hàng ảo, các khóa phạm vi được thực hiện.
- Repeatable Read: Đây là mức độ cô lập cao thứ hai. Điều này tương tự như serializable, chỉ khác là các khóa phạm vi không được thực hiện.
- Read Committed: Ở mức độ này, các khóa chia sẻ được cho phép và chỉ đọc dữ liệu đã cam kết. Nó không bao giờ đọc bất kỳ dữ liệu nào đang được cập nhật trong quá trình bất kỳ giao dịch nào.
- Read Uncommitted: Mức độ cô lập thấp nhất này cho phép đọc dữ liệu chưa được cam kết (dirty read).

Mạng Phân Phối Nội Dung (CDNs)
Nội dung web có thể được phân phối đến người dùng bằng cách sử dụng một mạng lưới dịch vụ phân phối, được gọi là Mạng Phân Phối Nội Dung (CDN). Nội dung được lưu trữ trong bộ nhớ đệm tại các vị trí Điểm Hiện Diện (POP) trên các máy chủ cạnh. Những máy chủ này sẽ được đặt gần người dùng cuối để giảm độ trễ.
Nội Dung Băng Thông Cao được Azure CDN Phân Phối
Nội dung băng thông cao được phân phối đến người dùng bởi Azure CDN. Nội dung được lưu trữ trong bộ nhớ đệm tại các nút vật lý được đặt chiến lược trên toàn thế giới. Nội dung động không thể lưu trữ trong bộ nhớ đệm được tăng tốc bởi Azure CDN. Các POP của CDN thực hiện điều này bằng cách tận dụng các tối ưu hóa mạng khác nhau, ví dụ như tối ưu hóa một tuyến đường để bỏ qua Giao Thức Cổng Biên (BGP).
Azure CDN giúp phân phối tài nguyên Website với các lợi ích sau:
- Hiệu suất tốt và dễ sử dụng: Rất hữu ích cho một ứng dụng khi cần nhiều vòng tròn để thêm nội dung.
- Quản lý tải cao ngay lập tức: Giúp xử lý tải cao ngay lập tức, ví dụ như khi bắt đầu một sự kiện ra mắt sản phẩm.
- Xử lý yêu cầu người dùng và nội dung: Các yêu cầu của người dùng được gán và nội dung được gửi trực tiếp từ các máy chủ cạnh. Điều này ngăn chặn việc tạo ra lưu lượng truy cập tại máy chủ gốc.

Khả Năng và Chức Năng của Các Dịch Vụ Azure cho Xử Lý Dữ Liệu Chính
Xử lý dữ liệu chính bao gồm việc xử lý và phân tích lượng dữ liệu lớn để rút ra các thông tin chi tiết, trong cả các tình huống xử lý hàng loạt và thời gian thực.
Azure HDInsight
Các chức năng của nó bao gồm:
- Phân Tích Dựa Trên Hadoop và Spark: Azure HDInsight cung cấp các cụm quản lý cho Hadoop, Spark, HBase và các khung công tác dữ liệu lớn khác.
- Xử Lý Hàng Loạt: Cho phép xử lý lượng dữ liệu lớn theo từng đợt bằng các công nghệ như MapReduce cho xử lý phân tán.
- Khả Năng Mở Rộng: Mở rộng cụm dựa trên nhu cầu, cho phép xử lý các tập dữ liệu lớn một cách hiệu quả.
- Tích Hợp Học Máy: Cho phép tích hợp với các khung học máy để phân tích dự đoán trên các tập dữ liệu lớn.
Một số trường hợp sử dụng của nó bao gồm:
- Xử Lý Hàng Loạt Dữ Liệu Lớn: Lý tưởng cho các tình huống yêu cầu xử lý hàng loạt quy mô lớn, chẳng hạn như xử lý nhật ký, các nhiệm vụ ETL (Trích xuất, Chuyển đổi, Tải), và phân tích dữ liệu lịch sử.
- Học Máy và Phân Tích Dự Đoán: Được sử dụng để đào tạo các mô hình học máy trên các tập dữ liệu lớn.
Azure Databricks
Các chức năng của nó bao gồm:
- Nền Tảng Dựa Trên Apache Spark: Cung cấp môi trường cộng tác dựa trên Apache Spark, cho phép truy vấn tương tác, trực quan hóa dữ liệu và học máy.
- Xử Lý Dữ Liệu Thống Nhất: Kết hợp kỹ thuật dữ liệu, khoa học dữ liệu và phân tích trong một nền tảng thống nhất.
- Xử Lý Thời Gian Thực và Hàng Loạt: Hỗ trợ cả xử lý thời gian thực và hàng loạt thông qua các khả năng streaming của Spark.
- Khả Năng Mở Rộng và Cộng Tác: Cho phép các nhóm cộng tác trên các nhiệm vụ kỹ thuật dữ liệu và phân tích một cách mở rộng.
Một số trường hợp sử dụng của nó bao gồm:
- Xử Lý Dữ Liệu Thời Gian Thực: Phù hợp cho các tình huống yêu cầu phân tích dữ liệu thời gian thực và lịch sử, chẳng hạn như phát hiện gian lận, xử lý dữ liệu IoT, và phân tích thời gian thực.
- Kỹ Thuật Dữ Liệu và Cộng Tác: Lý tưởng cho các nhiệm vụ kỹ thuật dữ liệu cộng tác như làm sạch dữ liệu, chuyển đổi, và tạo đặc trưng cho học máy.
Azure Stream Analytics
Các chức năng của nó bao gồm:
- Phân Tích Dòng Thời Gian Thực: Cho phép xử lý và phân tích dữ liệu dòng từ các nguồn khác nhau như thiết bị IoT, cảm biến, mạng xã hội, v.v.
- Khả Năng Mở Rộng và Độ Trễ Thấp: Mở rộng động để xử lý lượng lớn dữ liệu với độ trễ thấp, phù hợp cho việc ra quyết định thời gian thực.
- Tích Hợp với Các Dịch Vụ Azure: Dễ dàng tích hợp với các dịch vụ Azure khác để trực quan hóa dữ liệu, lưu trữ, và các hành động theo sự kiện.
Một số trường hợp sử dụng của nó bao gồm:
- Thông Tin Thời Gian Thực và Cảnh Báo: Được sử dụng cho các tình huống yêu cầu thông tin ngay lập tức từ dữ liệu dòng, chẳng hạn như hệ thống giám sát, phát hiện bất thường, và kích hoạt cảnh báo.
- Xử Lý Dữ Liệu Liên Tục: Phù hợp cho các ứng dụng đòi hỏi xử lý và phân tích dữ liệu liên tục, chẳng hạn như phân tích luồng nhấp chuột và phân tích cảm xúc trên mạng xã hội.
Bài viết liên quan:


Dịch vụ thiết kế Wesbite





