
Tìm hiểu thêm Package, regular expression trong Java
Khi viết chương trình bằng Java, thường cần thực hiện một số nhiệm vụ trên dữ liệu được người dùng chỉ định, dữ liệu này có thể có định dạng khác nhau như chuỗi, số, ký tự và nhiều định dạng khác. Để thao tác trên dữ liệu này, Java cung cấp các lớp và phương thức đặc biệt trong một gói riêng biệt gọi là gói Java.lang. Gói này đã được giới thiệu cơ bản ở bài viết trước, có thể xem thêm tại link:
Mục lục
Tổng quan về Gói java.lang
Gói java.lang cung cấp các lớp quan trọng cho việc tạo chương trình Java, bao gồm các lớp cơ sở cấu thành hệ thống lớp, xử lý ngoại lệ cơ bản, kiểu dữ liệu liên quan đến định nghĩa ngôn ngữ, hỗ trợ luồng, các hàm toán học, chức năng bảo mật và thông tin về hệ thống nguyên bản. Một số lớp quan trọng nhất là:
- Object: Đây là gốc của hệ thống lớp.
- Class: Các thể hiện của lớp này đại diện cho các lớp tại thời gian chạy.
Các lớp trong gói java.lang được tự động nhập vào mọi tệp mã nguồn, loại bỏ nhu cầu sử dụng câu lệnh import tường minh.
Các lớp và giao diện quan trọng khác trong gói java.lang bao gồm:
- Enum: Đây là lớp cơ sở cho tất cả các lớp liệt kê.
- Throwable: Đây là lớp cơ sở của hệ thống lớp xử lý ngoại lệ.
- Error, Exception và RuntimeException: Đây là lớp cơ sở cho các loại ngoại lệ khác nhau, đại diện cho các ngoại lệ cấp ngôn ngữ và ngoại lệ phổ biến.
- Thread: Lớp này cho phép thao tác trên các luồng.
- String: Được sử dụng để tạo và thao tác trên chuỗi và chuỗi chữ cái.
- StringBuffer và StringBuilder: Các lớp này hỗ trợ thao tác trên chuỗi.
- Comparable: Một giao diện hỗ trợ so sánh và sắp xếp chung cho các đối tượng.
- Iterable: Một giao diện cho phép lặp chung bằng cách sử dụng vòng lặp for nâng cao.
- Các lớp khác như Process, ClassLoader, Runtime, System và SecurityManager cung cấp các hoạt động hệ thống để quản lý các tiến trình bên ngoài, tải động động của lớp, truy vấn môi trường (ví dụ: thời gian trong ngày) và thi hành các chính sách bảo mật.
- Math: Lớp này cung cấp các hàm toán học cơ bản như căn bậc hai, sin, cosin và nhiều hàm khác.
- Các lớp bọc (Wrapper Class): Các lớp này bao gói các kiểu nguyên thủy dưới dạng đối tượng.
Quản lý bộ nhớ tự động (Garbage Collection)
Quản lý bộ nhớ là quá trình xác định các đối tượng trong bộ nhớ không còn cần và giải phóng bộ nhớ được sử dụng bởi các đối tượng đó để có thể sử dụng cho các phân bổ sau này. Trong một số ngôn ngữ lập trình, quản lý bộ nhớ là trách nhiệm của người lập trình. Tuy nhiên, sự phức tạp của quản lý bộ nhớ dẫn đến nhiều lỗi phổ biến có thể gây ra hành vi chương trình không mong muốn hoặc gây sự cố. Điều này dẫn đến nhiều thời gian dành cho việc gỡ lỗi và cố gắng sửa lỗi này.
(Problema lớn khác có thể xảy ra trong một chương trình với quản lý bộ nhớ tường minh là các tham chiếu treo. Có thể xảy ra trường hợp không gian được cấp phát cho một đối tượng được giải phóng, nhưng một đối tượng khác vẫn có tham chiếu đến nó. Nếu đối tượng (bây giờ là treo) có tham chiếu đó cố gắng truy cập đối tượng gốc, kết quả sẽ là không thể đoán được nếu không gian đã được cấp phát lại cho một đối tượng mới.
Một vấn đề phổ biến khác với quản lý bộ nhớ tường minh là rò rỉ bộ nhớ. Rò rỉ bộ nhớ xảy ra khi bộ nhớ được cấp phát cho một đối tượng không còn được tham chiếu nhưng không được giải phóng. Ví dụ, khi ý định giải phóng không gian được dùng bởi một danh sách liên kết, người lập trình chỉ giải phóng phần tử đầu tiên của danh sách. Trong trường hợp này, các phần tử còn lại của danh sách không còn được tham chiếu. Họ ra khỏi tầm với của chương trình và không thể sử dụng hoặc phục hồi được. Nếu rò rỉ như vậy tiếp tục xảy ra, chúng có thể tiếp tục tiêu thụ bộ nhớ cho đến khi hết bộ nhớ có sẵn.
Một cách tiếp cận khác với quản lý bộ nhớ tường minh được áp dụng bởi nhiều ngôn ngữ hướng đối tượng là quản lý bộ nhớ tự động thông qua một chương trình gọi là bộ thu gom rác. Thu gom rác giúp tránh vấn đề về tham chiếu treo vì một đối tượng vẫn được tham chiếu ở đâu đó sẽ không bao giờ bị thu gom rác và do đó sẽ không được coi là rác. Thu gom rác cũng giải quyết vấn đề rò rỉ bộ nhớ vì nó tự động giải phóng tất cả bộ nhớ không còn được tham chiếu.
Vì vậy, một bộ thu gom rác chịu trách nhiệm cho việc:
- phân bổ bộ nhớ
- đảm bảo rằng bất kỳ đối tượng nào có tham chiếu nên vẫn nằm trong bộ nhớ
- giải phóng bộ nhớ mà đối tượng không còn tham chiếu
Các đối tượng có tham chiếu được coi là sống còn trong khi các đối tượng không còn được tham chiếu được coi là đã chết. Những đối tượng như vậy được gọi là rác. Quá trình xác định và thu hồi không gian bị chiếm bởi các đối tượng này được gọi là thu gom rác.
Thu gom rác có thể giải quyết nhiều vấn đề phân bổ bộ nhớ, nhưng không phải tất cả. Nó cũng là một quy trình phức tạp và mất thời gian và tài nguyên riêng của nó. Thuật toán cụ thể được sử dụng để tổ chức bộ nhớ và phân bổ / giải phóng bộ nhớ được xử lý bởi bộ thu gom rác và được ẩn khỏi người lập trình. Không gian chủ yếu được cấp phát từ một bể lớn của bộ nhớ gọi là heap.
Một đối tượng trở nên đủ điều kiện để bị thu gom rác nếu nó không thể được truy cập từ bất kỳ luồng sống nào hoặc bất kỳ tham chiếu tĩnh nào. Nó trở nên đủ điều kiện để bị thu gom rác nếu tất cả các tham chiếu của nó đều là null. Lưu ý rằng, các phụ thuộc vòng không được coi là tham chiếu. Vì vậy, nếu Đối tượng A tham chiếu đến đối tượng B và đối tượng B tham chiếu đến Đối tượng A, nhưng họ không có bất kỳ tham chiếu sống nào khác. Trong trường hợp này, cả Đối tượng A và B đều đủ điều kiện để bị thu gom rác.
Do đó, một đối tượng trở nên đủ điều kiện để bị thu gom rác trong các trường hợp sau:
- Tất cả các tham chiếu của đối tượng đó được đặt rõ ràng thành null, ví dụ: object = null
- Đối tượng được tạo bên trong một khối và tham chiếu ra khỏi phạm vi khi kiểm soát thoát khỏi khối đó
- Đối tượng cha được đặt thành null. Nếu một đối tượng có tham chiếu đến một đối tượng khác và tham chiếu của đối tượng chứa được đặt thành null, đối tượng con tự động trở nên đủ điều kiện để bị thu gom rác.
Thời gian thu gom rác được quyết định bởi bộ thu gom rác. Thông thường, toàn bộ heap hoặc một phần của nó được thu thập khi nó đã đầy hoặc khi nó đạt một ngưỡng phần trăm sử dụng.
Một số đặc điểm của một Bộ thu gom rác bao gồm:
- Phải đảm bảo an toàn và toàn diện.
- Phải đảm bảo rằng dữ liệu sống không bị giải phóng một cách lỗi và rác không còn được thả cho quá nhiều chu kỳ thu gom.
- Phải hoạt động hiệu quả, mà không mất nhiều thời gian dài trong đó ứng dụng không chạy. Tuy nhiên, thường có sự cân nhắc giữa thời gian, không gian và tần suất. Ví dụ, đối với kích thước heap nhỏ, việc thu gom sẽ nhanh nhưng heap sẽ đầy nhanh hơn, do đó cần nhiều lần thu gom hơn. Ngược lại, heap lớn sẽ mất nhiều thời gian để đầy và do đó việc thu gom sẽ ít thường xuyên hơn, nhưng nó có thể mất nhiều thời gian hơn.
- Phải giới hạn sự chia rẽ của bộ nhớ khi bộ nhớ của các đối tượng rác được giải phóng. Điều này bởi vì nếu bộ nhớ được giải phóng được chia thành các phần nhỏ, có thể không đủ để sử dụng cho việc phân bổ một đối tượng lớn.
- Phải xử lý vấn đề khả năng mở rộng trong các ứng dụng đa luồng trên hệ thống đa bộ xử lý.
Cần phải nghiên cứu nhiều tham số khi thiết kế hoặc lựa chọn thuật toán thu gom rác:
Thu thập theo chuỗi so với thu thập song song
Với thu thập chuỗi, chỉ có một thứ xảy ra vào một thời điểm. Ví dụ, ngay cả khi có nhiều CPU có sẵn, chỉ có một CPU được sử dụng để thực hiện thu thập. Trong khi đó, với thu thập song song, nhiệm vụ thu gom rác được chia thành các phần con được thực hiện đồng thời trên các CPU khác nhau. Thu thập đồng thời nhanh chóng nhưng dẫn đến sự phức tạp bổ sung và nguy cơ chia rẽ
Thu thập đồng thời so với dừng chương trình (stop-the-world)
Trong phương pháp thu thập stop-the-world, trong quá trình thu gom rác, việc thực hiện ứng dụng được tạm dừng hoàn toàn. Trong khi đó, trong phương pháp đồng thời, một hoặc nhiều nhiệm vụ thu gom rác có thể được thực hiện đồng thời, tức là đồng thời với việc thực hiện ứng dụng. Tuy nhiên, điều này đánh một số chi phí thêm cho các công cụ thu gom đồng thời và ảnh hưởng đến hiệu suất do yêu cầu kích thước heap lớn hơn.
Thu thập nén so với không nén và Sao chép
Trong phương pháp nén, sau khi bộ thu gom rác đã xác định rằng các đối tượng trong bộ nhớ là rác, nó có thể nén bộ nhớ bằng cách di chuyển tất cả các đối tượng đang hoạt động lại cùng nhau và hoàn toàn, giành lại bộ nhớ của các đối tượng không được tham chiếu. Sau khi nén, việc phân bổ một đối tượng mới tại vị trí trống đầu tiên trở nên dễ dàng và nhanh hơn. Điều này có thể được thực hiện bằng cách sử dụng một con trỏ đơn giản để theo dõi vị trí tiếp theo có sẵn cho việc phân bổ đối tượng mới.
Ngược lại, một thu thập không nén giải phóng không gian được sử dụng bởi các đối tượng rác tại chỗ. Điều này có nghĩa là nó không di chuyển tất cả các đối tượng đang hoạt động lại cùng nhau để tạo ra một khu vực vùng nhớ lớn như một bộ thu gom nén làm. Lợi ích là việc hoàn thành thu gom rác nhanh hơn, nhưng nhược điểm là sự chia rẽ tiềm năng.
Nói chung, việc phân bổ từ một heap có thể bị tốn kém hơn so với từ một heap được nén tại chỗ. Điều này bởi vì có thể cần tìm kiếm toàn bộ heap để tìm một khu vực liền kề đủ lớn để chứa đối tượng mới.
Trong phương pháp sao chép, bộ thu gom sao chép hoặc di chuyển đối tượng đang hoạt động đến một vùng bộ nhớ khác. Lợi thế là khu vực nguồn trống và có thể được sử dụng cho việc phân bổ tiếp theo nhanh chóng và dễ dàng. Tuy nhiên, điểm yếu là việc sao chép cần thời gian thêm và cũng có thể cần thêm không gian để di chuyển các đối tượng.
Các chỉ số sau đây có thể được sử dụng để đánh giá hiệu suất của một bộ thu gom rác:
- Hiệu năng: Đó là phần trăm thời gian tổng không được dành cho thu gom rác, xem xét một khoảng thời gian dài.
- Chi phí thu gom rác: Đây là nghịch đảo của hiệu năng. Đó là phần trăm thời gian tổng được dành cho thu gom rác.
- Thời gian tạm ngừng: Đó là khoảng thời gian mà trong đó việc thực hiện ứng dụng bị tạm ngừng trong khi thu gom rác đang diễn ra.
- Tần suất thu thập: Đó là một đo lường về tần suất thu thập so với việc thực hiện ứng dụng.
- Dấu vết: Đó là một đo lường về kích thước, chẳng hạn như kích thước heap
- Thời gian: Đó là khoảng thời gian từ lúc một đối tượng trở thành rác đến lúc bộ nhớ của nó trở nên có sẵn.
Phương thức finalize()
finalize() là một phương thức được gọi bởi bộ thu gom rác trên một đối tượng khi nó được xác định không còn tham chiếu nào trỏ đến nó nữa. Một lớp con có thể ghi đè phương thức finalize() để giải phóng tài nguyên hệ thống hoặc thực hiện các công việc dọn dẹp khác. Cú pháp của phương thức finalize() như sau:
Cú pháp:
protected void finalize() throws ThrowablePhương thức finalize() thường được sử dụng để thực hiện các hành động dọn dẹp trước khi đối tượng bị loại bỏ một cách không thể hoàn tác. Tuy nhiên, phương thức finalize() có thể thực hiện bất kỳ hành động nào, bao gồm việc làm cho đối tượng này có thể sẵn sàng lại cho các luồng khác. Ví dụ, phương thức finalize() cho một đối tượng đại diện cho một kết nối nhập/ xuất có thể thực hiện các giao dịch I/O tường minh để ngắt kết nối trước khi đối tượng bị loại bỏ vĩnh viễn. Phương thức finalize() của lớp Object không thực hiện bất kỳ hành động đặc biệt nào; nó chỉ đơn giản trả về một cách bình thường. Tuy nhiên, các lớp con của Object có thể ghi đè định nghĩa này theo yêu cầu.
Sau khi phương thức finalize() được gọi cho một đối tượng, không có hành động nào khác được thực hiện cho đến khi JVM xác định rằng không có luồng hoạt động nào còn cố gắng truy cập cùng một đối tượng. Sau đó, đối tượng có thể bị loại bỏ. Phương thức finalize() không bao giờ được gọi nhiều hơn một lần bởi JVM đối với bất kỳ đối tượng cụ thể nào. Bất kỳ ngoại lệ nào được ném bởi phương thức finalize() đều dẫn đến tạm ngưng việc hoàn thiện cho đối tượng này. Phương thức finalize() ném ngoại lệ Throwable.
Đôi khi, một đối tượng có thể phải thực hiện một số công việc khi nó bị hủy bỏ. Ví dụ, nếu một đối tượng đang giữ một tài nguyên không phải là Java như một con trỏ tệp hoặc phông ký tự cửa sổ. Trong trường hợp này, người ta có thể muốn đảm bảo rằng những tài nguyên này được giải phóng trước khi đối tượng bị hủy bỏ. Để xử lý điều này, bạn có thể định nghĩa các hành động cụ thể trong phương thức finalize(). Khi JVM gọi phương thức này trong quá trình tái sử dụng một đối tượng của lớp đó, các hành động được chỉ định trong phương thức finalize() sẽ được thực hiện trước khi đối tượng bị hủy bỏ.
Tuy nhiên, quan trọng phải lưu ý rằng phương thức finalize() chỉ được gọi ngay trước khi quá trình thu gom rác diễn ra, nhưng không được gọi khi đối tượng ra khỏi phạm vi. Điều này có nghĩa rằng không ai biết chính xác khi phương thức finalize() sẽ được thực hiện. Do đó, nên cung cấp các cách khác để giải phóng tài nguyên hệ thống được sử dụng bởi đối tượng thay vì phụ thuộc vào phương thức finalize().
Xét ví dụ sau:
public class TestGc {
int num;
public void setNum(int num1, int num2) {
this.num = num1;
System.out.println("Setting num1 to " + num1);
System.out.println("Setting num2 to " + num2);
}
public void showNum() {
System.out.println("Value of num is " + num);
}
public static void main(String[] args) {
TestGc obj1 = new TestGc();
TestGc obj2 = new TestGc();
obj1.setNum(2, 3);
obj2.setNum(4, 5);
obj1.showNum();
obj2.showNum();
TestGc obj3; //line 1
obj3 = obj2; // line 2
obj3.showNum(); // line 3
obj2 = null; // line 4
obj3.showNum(); // line 5 obj3 will still refer to the object, so it will work
obj3 = null; // line 6
// obj3.showNum(); // line 7 obj3 is now null, this will cause a NullPointerException if uncommented
}
}
Việc mã nguồn cung cấp mô tả một lớp tên là TestGC với hai biến được khởi tạo trong phương thức setNum() và hiển thị bằng cách sử dụng phương thức showNum(). Sau đó, hai đối tượng, obj1 và obj2, của lớp TestGC được tạo ra. Để hiểu về thu gom rác, thực hiện mã nguồn. Hình dưới minh họa sự biểu diễn trong bộ nhớ của các đối tượng được tạo ra trong quá trình thực hiện.
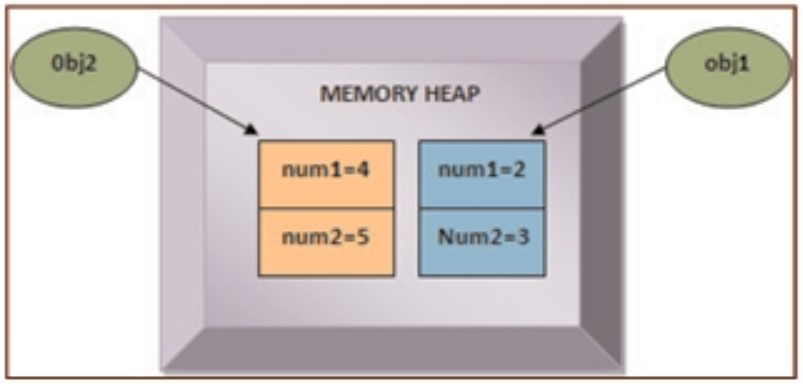
Hình dưới biểu diễn dòng code comment line 2 và line 3, 2 biến obj2 và obj3 cùng tham chiếu tới một đối tượng:
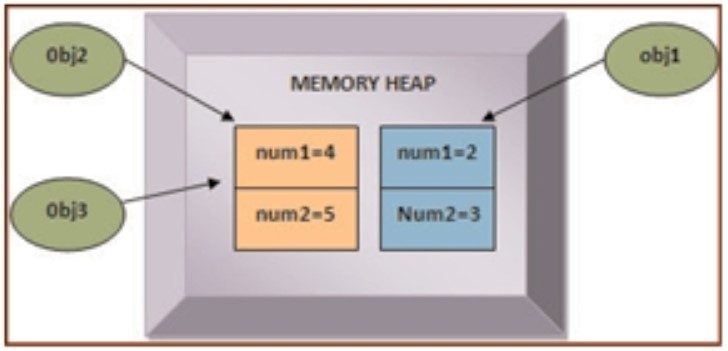
Hình dưới mô tả dòng code comment line 4, biến obj2 được gán giá trị null, nhưng biến obj3 vẫn trỏ tới đối tượng:
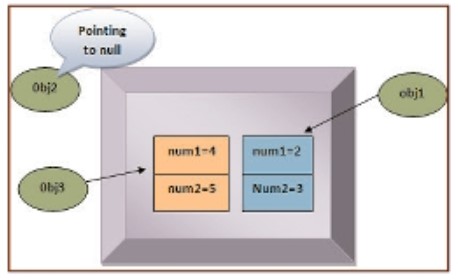
Xét dòng comment line 6 và 7 biến obj3 cũng được gán bằng null. Lúc này, không còn tham chiếu nào trỏ đến đối tượng và do đó, nó trở nên thích hợp cho việc thu gom rác. Nó sẽ bị loại bỏ khỏi bộ nhớ bởi bộ thu gom rác và không thể khôi phục lại. Hình dưới mô tả tình huống này:
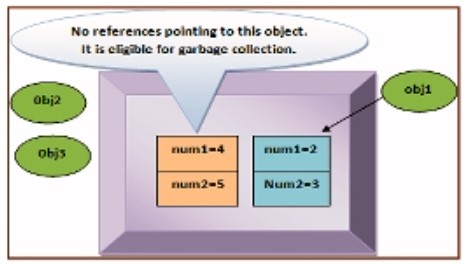
Do đó, một số lưu ý quan trọng về thu gom rác là như sau:
- Để làm cho một đối tượng thích hợp cho việc thu gom rác, biến tham chiếu của nó nên được thiết lập thành null.
- Cần lưu ý rằng các kiểu nguyên thủy không phải là đối tượng. Do đó, chúng không thể được gán giá trị null. Nghĩa là int x = null là sai.
Các lớp của gói Java.lang
Các lớp được cung cấp trong gói java.lang giúp các nhà phát triển thực hiện các nhiệm vụ phổ biến một cách nhanh chóng và hiệu quả mà không cần viết logic không cần thiết.
Lớp bọc (Wrapper Classes)
Đôi khi, cần phải biểu diễn một kiểu nguyên thủy như là một đối tượng. Các lớp bọc như Boolean, Character, Integer, Float, Long và Double phục vụ mục đích này. Mỗi kiểu bọc cho từng kiểu nguyên thủy có sẵn. Ví dụ, một đối tượng kiểu Integer chứa một trường có kiểu int.
Các lớp bọc biểu diễn một giá trị sao cho một tham chiếu đến nó có thể được lưu trữ trong một biến có kiểu tham chiếu.
Các lớp bọc cũng cung cấp một số phương thức để xử lý biến của kiểu dữ liệu đã chỉ định sang kiểu khác. Ví dụ, để chuyển đổi một chuỗi thành một số nguyên, bạn có thể viết như sau:
Integer x = Integer.parseInt("1234");Ở đây, phương thức parseInt() được sử dụng để chuyển chuỗi ‘1234’ thành một biến số nguyên. Ngoài ra, việc gán trực tiếp từ kiểu Integer sang kiểu int nguyên thủy được cho phép và việc chuyển đổi xảy ra một cách ngầm định. Các lớp này cũng hỗ trợ các phương thức tiêu chuẩn như equals() và hashCode(). Lớp Void không thể được khởi tạo và giữ một tham chiếu đến một đối tượng Class đại diện cho kiểu nguyên thủy void.
Lớp Math
Lớp Math chứa các phương thức để thực hiện các phép toán toán học/số học cơ bản như tính căn bậc hai, hàm lượng giác, số mũ cơ bản, logarithm, và nhiều phép toán khác.
Mặc định, nhiều trong số các phương thức này đơn giản là gọi phương thức tương đương của lớp StrictMath cho việc thực thi của chúng. Bảng dưới liệt kê một số phương thức thông dụng trong lớp Math.
- static double abs(double a) : Trả về giá trị tuyệt đối của một giá trị double.
- static float abs(float a) : Trả về giá trị tuyệt đối của một giá trị float.
- static int abs(int a) : Trả về giá trị tuyệt đối của một giá trị int.
- static long abs(long a) : Trả về giá trị tuyệt đối của một giá trị long.
- static double ceil(double a) : Trả về giá trị double nhỏ nhất mà lớn hơn hoặc bằng tham số đầu vào.
- static double cos(double a) : Trả về giá trị của hàm số lượng giác cosine của một góc.
- static double exp(double a) : Trả về giá trị của số Euler e mũ bậc double.
- static double floor(double a) : Trả về giá trị double lớn nhất mà nhỏ hơn hoặc bằng tham số đầu vào.
- static double log(double a) : Trả về giá trị logarithm tự nhiên (cơ số e) của một giá trị double.
- static double max(double a, double b) : Trả về giá trị lớn hơn trong hai giá trị double.
- static float max(float a, float b) : Trả về giá trị lớn hơn trong hai giá trị float.
- static int max(int a, int b) : Trả về giá trị lớn hơn trong hai giá trị int.
- static long max(long a, long b) : Trả về giá trị lớn hơn trong hai giá trị long.
- static double min(double a, double b) : Trả về giá trị nhỏ hơn trong hai giá trị double.
- static float min(float a, float b) : Trả về giá trị nhỏ hơn trong hai giá trị float.
- static int min(int a, int b) : Trả về giá trị nhỏ hơn trong hai giá trị int.
- static long min(long a, long b) : Trả về giá trị nhỏ hơn trong hai giá trị long.
- static double pow(double a, double b) : Trả về giá trị của đối số đầu tiên mũ bằng đối số thứ hai.
- static double random() : Trả về một giá trị double dương, lớn hơn hoặc bằng 0.0 và nhỏ hơn 1.0.
- static long round(double a) : Trả về số Long gần nhất với đối số.
- static int round(float a) : Trả về số int gần nhất với đối số.
- static double sin(double a) : Trả về giá trị của hàm số lượng giác sine của một góc.
- static double sqrt(double a) : Trả về căn bậc hai dương với độ làm tròn chính xác của một giá trị double.
- static double tan(double a) : Trả về giá trị của hàm số lượng giác tangent của một góc.
Ví dụ:
class MathClass {
int num1, num2;
public MathClass() {}
public MathClass(int num1, int num2) {
this.num1 = num1;
this.num2 = num2;
}
public void doMax() {
System.out.println("Maximum is: " + Math.max(num1, num2));
}
public void doMin() {
System.out.println("Minimum is: " + Math.min(num1, num2));
}
public void doPow() {
System.out.println("Result of power is: " + Math.pow(num1, num2));
}
public void getRandom() {
System.out.println("Random generated is: " + Math.random());
}
public void doSquareRoot() {
System.out.println("Square Root of " + num1 + " is: " + Math.sqrt(num1));
}
}
public class TestMath {
public static void main(String[] args) {
MathClass objMath = new MathClass(4, 5);
objMath.doMax();
objMath.doMin();
objMath.doPow();
objMath.getRandom();
objMath.doSquareRoot();
}
}
Output:
Maximum is: 5
Minimum is: 4
Result of power is: 1024.0
Random generated is: [a random decimal number]
Square Root of 4 is: 2.0
Lớp System
Lớp System cung cấp một số trường và phương thức lớp hữu ích. Tuy nhiên, nó không thể được khởi tạo. Nó cung cấp một số tiện ích như đầu vào tiêu chuẩn, đầu ra tiêu chuẩn và luồng đầu ra lỗi; một cách để xử lý tệp và thư viện; truy cập đến các thuộc tính được xác định từ bên ngoài và biến môi trường; cũng như một phương thức tiện ích để sao chép một phần của mảng nhanh chóng.
Bảng dưới liệt kê một số phương thức thường được sử dụng của lớp System:
static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
Phương thức sao chép một mảng từ mảng nguồn đã được chỉ định, bắt đầu từ vị trí đã được chỉ định, đến vị trí đã được chỉ định của mảng đích.
- long currentTimeMillis() : Phương thức trả về thời gian hiện tại trong mili giây.
- static void exit(int status) : Phương thức kết thúc JVM hiện đang chạy.
- static void gc() : Phương thức chạy bộ thu gom rác.
- String getenv(String name) : Phương thức lấy giá trị của biến môi trường đã được chỉ định.
- Properties getProperties() : Phương thức xác định các thuộc tính hệ thống hiện tại.
- static void loadLibrary(String Libname) : Phương thức tải thư viện hệ thống được chỉ định bởi đối số Libname.
- static void setSecurityManager(SecurityManager s) : Phương thức thiết lập Bảo mật Hệ thống.
Ví dụ:
public class SystemClass {
int[] arr1 = {1, 3, 2, 4};
int[] arr2 = {6, 7, 8, 0};
public void getTime() {
System.out.println("Current time in milliseconds is: " + System.currentTimeMillis());
}
public void copyArray() {
System.arraycopy(arr1, 0, arr2, 0, 4);
System.out.print("Copied array is: ");
for (int i = 0; i < arr2.length; i++) {
System.out.println(arr2[i]);
}
}
public void getPath(String variable) {
System.out.println("Value of Path variable is: " + System.getenv(variable));
}
public static void main(String[] args) {
SystemClass objSys = new SystemClass();
objSys.getTime();
objSys.copyArray();
objSys.getPath("Path");
}
}
Lớp Object
Lớp Object là gốc của thứ bậc lớp. Mọi lớp đều có Object là lớp cha của nó. Tất cả các đối tượng, bao gồm mảng, thực hiện các phương thức của lớp Object.
Bảng dưới liệt kê một số phương thức thường được sử dụng của lớp Object:
- protected Object clone() Phương thức tạo ra và trả về một bản sao của đối tượng này.
- boolean equals(Object obj) Phương thức xác định xem đối tượng khác có bằng với đối tượng này hay không.
- protected void finalize() Phương thức được gọi bởi bộ thu gom rác trên một đối tượng khi bộ thu gom rác xác định rằng không còn tham chiếu nào đến đối tượng nữa.
- Class getClass() Phương thức trả về lớp runtime của một đối tượng.
- int hashCode() Phương thức trả về giá trị mã băm (hash code) cho đối tượng.
- void notify() Phương thức đánh thức một luồng đang chờ trên khóa (monitor) của đối tượng này.
- void notifyAll() Phương thức đánh thức tất cả các luồng đang chờ trên khóa (monitor) của đối tượng này.
- String toString() Phương thức trả về biểu diễn dạng chuỗi của đối tượng.
- void wait() Phương thức làm cho luồng hiện tại chờ đợi cho đến khi một luồng khác gọi phương thức notify() hoặc notifyAll() cho đối tượng này.
- void wait(long timeout) Phương thức làm cho luồng hiện tại chờ đợi cho đến khi một luồng khác gọi phương thức notify() hoặc notifyAll() cho đối tượng này hoặc đã qua một khoảng thời gian cụ thể.
- void wait(long timeout, int nanos) Phương thức làm cho luồng hiện tại chờ đợi cho đến khi một luồng khác gọi phương thức notify() hoặc notifyAll() cho đối tượng này, hoặc một luồng khác ngắt luồng hiện tại, hoặc đã qua một khoảng thời gian thực tế cụ thể.
Ví dụ:
public class ObjectClass {
Integer num;
public ObjectClass() {
}
public ObjectClass(Integer num) {
this.num = num;
}
// Method to use the toString() method
public void getStringForm() {
System.out.println("String form of num is: " + num.toString());
}
}
public class TestObject {
public static void main(String[] args) {
// Creating objects of ObjectClass
ObjectClass obj1 = new ObjectClass(1234);
ObjectClass obj2 = new ObjectClass(1234);
obj1.getStringForm();
// Checking for equality of objects
if (obj1.equals(obj2))
System.out.println("Objects are equal");
else
System.out.println("Objects are not equal");
obj2 = obj1; // Assigning reference of obj1 to obj2
// Checking the equality of objects again
if (obj1.equals(obj2))
System.out.println("Objects are equal");
else
System.out.println("Objects are not equal");
}
}
Lớp Class
Trong chương trình Java đang thực thi, các thể hiện của lớp Class đại diện cho các lớp và giao diện. Một enum là một loại lớp, và một chú thích (annotation) là một loại giao diện. Ngay cả mảng cũng thuộc về một lớp và được thể hiện dưới dạng một đối tượng Class được chia sẻ bởi tất cả các mảng có cùng kiểu phần tử và số chiều. Các kiểu dữ liệu nguyên thủy trong Java như boolean, byte, char, short, int, long, float và double, cũng như từ khóa void, cũng được đại diện dưới dạng các đối tượng Class. Lớp Class không có hàm tạo công cộng. Thay vào đó, các đối tượng Class được xây dựng tự động bởi JVM khi các lớp được tải và thông qua cuộc gọi đến phương thức defineClass() trong trình tải lớp.
Bảng dưới liệt kê một số phương thức thường được sử dụng của lớp Class.
- static Class forName(String className) Phương thức trả về đối tượng Class liên kết với lớp hoặc giao diện có tên chuỗi đã cho.
- static Class forName(String name, boolean initialize, ClassLoader loader) Phương thức trả về đối tượng Class liên kết với lớp hoặc giao diện có tên chuỗi đã cho, sử dụng trình tải (ClassLoader) đã cho.
- Class[] getClasses() Phương thức trả về một mảng chứa các đối tượng Class đại diện cho tất cả các lớp và giao diện công khai là thành viên của lớp được đại diện bởi đối tượng Class này.
- Field getField(String name) Phương thức trả về một đối tượng Field thể hiện trường công khai đã cho của lớp hoặc giao diện được đại diện bởi đối tượng Class này.
- Class[] getInterfaces() Phương thức xác định các giao diện được triển khai bởi lớp hoặc giao diện được đại diện bởi đối tượng này.
- Method getMethod(String name, Class[] parameterTypes) Phương thức trả về một đối tượng Method thể hiện phương thức công khai đã cho của lớp hoặc giao diện được đại diện bởi đối tượng Class này.
- int getModifiers() Phương thức trả về các bộ điều khiển ngôn ngữ Java cho lớp hoặc giao diện này, được mã hóa trong một số nguyên.
- String getName() Phương thức trả về tên của đối tượng (lớp, giao diện, lớp mảng, kiểu nguyên thủy hoặc void) được đại diện bởi đối tượng Class này. Tên sẽ được trả về dưới dạng chuỗi.
- URL getResource(String name) Phương thức tìm một tài nguyên với tên đã cho.
- Class getSuperclass() Phương thức trả về đối tượng Class đại diện cho lớp cha của đối tượng (lớp, giao diện, kiểu nguyên thủy hoặc void) được đại diện bởi đối tượng Class này.
- boolean isArray() Phương thức xác định xem đối tượng Class này có đại diện cho một lớp mảng hay không.
- boolean isInstance(Object obj) Phương thức xác định xem đối tượng đã cho có thể gán tương thích với đối tượng Class này hay không.
- boolean isInterface() Phương thức xác định xem đối tượng Class đã cho có đại diện cho một kiểu giao diện hay không.
- String toString() Phương thức chuyển đổi đối tượng thành chuỗi.
Ví dụ:
public class ClassDemo { // Added a missing class declaration.
public ClassDemo() {
// Constructor code here
}
}
public class TestClass {
public static void main(String[] args) {
ClassDemo obj = new ClassDemo(); // Creating an instance of ClassDemo
System.out.println("Class is: " + obj.getClass()); // Using getClass() to get the class of obj
}
}
Lớp ThreadGroup
Một nhóm luồng đại diện cho một tập hợp các luồng. Ngoài ra, một nhóm luồng cũng có thể bao gồm các nhóm luồng khác. Các nhóm luồng tạo thành một cây trong đó tất cả các nhóm luồng, trừ nhóm luồng ban đầu, đều có một phần tử cha.
Một luồng có thể truy cập thông tin về nhóm luồng của nó, nhưng không có quyền truy cập thông tin về nhóm luồng cha của nhóm luồng của nó hoặc bất kỳ nhóm luồng nào khác.
Bảng dưới liệt kê một số phương thức thường được sử dụng của lớp ThreadGroup:
- int activeCount() Phương thức trả về một ước tính về số lượng luồng hoạt động trong nhóm luồng này và các nhóm con của nó.
- int activeGroupCount() Phương thức trả về một ước tính về số lượng nhóm hoạt động trong nhóm luồng này và các nhóm con của nó.
- void checkAccess() Phương thức xác định xem luồng hiện đang chạy có quyền thay đổi nhóm luồng này hay không.
- void destroy() Phương thức hủy bỏ nhóm luồng này và tất cả các nhóm con của nó.
- int enumerate(Thread[] list) Phương thức sao chép vào mảng được chỉ định mọi luồng hoạt động trong nhóm luồng này và các nhóm con của nó.
- int enumerate(ThreadGroup[] list) Phương thức sao chép vào mảng được chỉ định tham chiếu đến mọi nhóm con hoạt động trong nhóm luồng này và các nhóm con của nó.
- int getMaxPriority() Phương thức trả về độ ưu tiên tối đa của nhóm luồng này.
- String getName() Phương thức trả về tên của nhóm luồng này.
- ThreadGroup getParent() Phương thức trả về phần tử cha của nhóm luồng này.
- void interrupt() Phương thức ngắt tất cả các luồng trong nhóm luồng này.
- boolean isDaemon() Phương thức kiểm tra xem nhóm luồng này có phải là một nhóm luồng hệ thống không.
- boolean isDestroyed() Phương thức kiểm tra xem nhóm luồng này đã bị hủy không.
- void list() Phương thức in thông tin về nhóm luồng này ra đầu ra tiêu chuẩn.
- boolean parentOf(ThreadGroup g) Phương thức kiểm tra xem nhóm luồng này là nhóm luồng đối số hoặc là một trong các nhóm luồng tổ tiên của nó.
- void setDaemon(boolean daemon) Phương thức thay đổi trạng thái hệ thống của nhóm luồng này.
- void setMaxPriority(int pri) Phương thức thiết lập độ ưu tiên tối đa của nhóm.
- String toString() Phương thức trả về biểu diễn dạng chuỗi của nhóm luồng này.
Lớp Runtime
Mỗi ứng dụng Java có một phiên bản duy nhất của lớp Runtime, cho phép ứng dụng tương tác với môi trường trong đó nó đang chạy. Runtime hiện tại được lấy thông qua việc gọi phương thức getRuntime(). Một ứng dụng không thể tạo ra một phiên bản riêng của lớp này.
Bảng dưới liệt kê một số phương thức của lớp Runtime:
- int availableProcessors() Phương thức trả về số lượng bộ xử lý có sẵn cho máy ảo Java.
- Process exec(String command) Phương thức thực thi lệnh chuỗi đã chỉ định trong một tiến trình riêng biệt.
- void exit(int status) Phương thức kết thúc JVM đang chạy hiện tại thông qua chuỗi tắt của nó.
- long freeMemory() Phương thức trả về lượng bộ nhớ trống trong JVM.
- void gc() Phương thức thực hiện bộ thu gom rác.
- static Runtime getRuntime() Phương thức trả về đối tượng runtime liên kết với ứng dụng Java hiện tại.
- void halt(int status) Phương thức chấm dứt bắt buộc JVM đang chạy hiện tại.
- void load(String filename) Phương thức tải tệp có tên đã chỉ định như một thư viện động.
- void loadLibrary(String libname) Phương thức tải thư viện động có tên đã chỉ định.
- long maxMemory() Phương thức trả về lượng bộ nhớ tối đa mà JVM sẽ cố gắng sử dụng.
- void runFinalization() Phương thức thực hiện các phương thức hoàn tất của các đối tượng đang chờ hoàn tất.
- long totalMemory() Phương thức trả về tổng lượng bộ nhớ trong JVM.
Chuỗi (String)
Các chuỗi (Strings) được sử dụng rộng rãi trong lập trình Java. Chuỗi là không gì khác ngoài một chuỗi ký tự. Trong ngôn ngữ lập trình Java, chuỗi được biểu diễn dưới dạng đối tượng. Nền tảng Java cung cấp lớp String để tạo và thao tác chuỗi. Ví dụ, cách trực tiếp nhất để tạo một chuỗi là cú pháp:
String str = "abc";Lớp String
Lớp String đại diện cho chuỗi ký tự. Tất cả chuỗi mẫu trong các chương trình Java, như “xyz,” được triển khai dưới dạng các thể hiện của lớp String.
Cú pháp của lớp String:
public final class String extends Object implements Serializable, Comparable<String>, CharSequence
Chuỗi là bất biến, có nghĩa là giá trị của chúng không thể thay đổi sau khi khởi tạo. Tuy nhiên, chuỗi đệm (string buffers) hỗ trợ chuỗi có thể thay đổi (mutable). Vì đối tượng String là bất biến, chúng có thể được chia sẻ.
Ví dụ:
String name = "Kate";
Tương đương với cú pháp:
char[] name = {'K', 'a', 't', 'e'};
String strName = new String(name);
Tương tự như các đối tượng khác, một đối tượng String có thể được tạo bằng cách sử dụng từ khóa new và một hàm tạo (constructor). Lớp String có 13 hàm khởi tạo nạp chồng (overloaded constructors) cho phép xác định giá trị ban đầu của chuỗi bằng cách sử dụng các nguồn khác nhau, chẳng hạn như một mảng ký tự như được thể hiện trong đoạn mã dưới:
public class TestStrings {
public static void main(String[] args) {
char[] name = {'G', 'e', 't', ' ', 't', 'h', 'e', ' ', 's', 't', 'r', 'i', 'n', 'g'};
String nameStr = new String(name);
System.out.println(nameStr);
}
}
Lớp String cung cấp các phương thức để thao tác với từng ký tự trong chuỗi, trích xuất các phụ chuỗi, so sánh chuỗi, tìm kiếm chuỗi và tạo một bản sao của chuỗi với tất cả các ký tự được chuyển đổi thành chữ hoa hoặc chữ thường. Chuyển đổi kiểu chữ hoa hoặc chữ thường dựa trên phiên bản Tiêu chuẩn Unicode được chỉ định bởi lớp ký tự (character class).
Ngôn ngữ Java hỗ trợ toán tử nối chuỗi (+) và chuyển đổi các đối tượng khác thành chuỗi. Nối chuỗi cũng có thể được thực hiện thông qua lớp StringBuilder hoặc StringBuffer và phương thức append của nó.
Chuyển đổi thành chuỗi có thể được thực hiện thông qua phương thức toString() được kế thừa từ lớp Object. Lớp Object là lớp gốc và được kế thừa bởi tất cả các lớp trong Java. Nói chung, việc truyền đối số null cho một hàm tạo hoặc phương thức của lớp này sẽ gây ra một ngoại lệ NullPointerException. Lớp String cung cấp các phương thức để làm việc với mã Unicode, tức là các ký tự, cũng như để làm việc với các đơn vị Unicode, tức là giá trị char.
Phương thức lớp String
Một số phương thức lớp String được mô tả ở bảng dưới:
- char charAt(int index) Phương thức trả về giá trị ký tự tại chỉ mục được chỉ định.
- int compareTo(String anotherString) Phương thức so sánh hai chuỗi theo thứ tự từ điển.
- String concat(String str) Phương thức nối chuỗi đã chỉ định vào cuối chuỗi hiện tại.
- boolean contains(CharSequence s) Phương thức trả về true nếu và chỉ nếu chuỗi này chứa chuỗi con được chỉ định.
- boolean endsWith(String suffix) Phương thức kiểm tra xem chuỗi này có kết thúc bằng hậu tố được chỉ định hay không.
- boolean equals(Object anObject) Phương thức so sánh chuỗi này với đối tượng được chỉ định.
- boolean equalsIgnoreCase(String anotherString) Phương thức so sánh chuỗi này với chuỗi khác, bỏ qua việc phân biệt chữ hoa và chữ thường.
- void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) Phương thức sao chép các ký tự từ chuỗi này vào mảng ký tự đích.
- int indexOf(int ch) Phương thức trả về chỉ mục đầu tiên của ký tự được chỉ định trong chuỗi này.
- boolean isEmpty() Phương thức trả về true nếu và chỉ nếu độ dài chuỗi là 0.
- int lastIndexOf(int ch) Phương thức trả về chỉ mục cuối cùng của ký tự được chỉ định trong chuỗi này.
- int length() Phương thức trả về độ dài của chuỗi này.
- boolean matches(String regex) Phương thức cho biết xem chuỗi này có khớp với biểu thức chính quy được chỉ định hay không.
- String replace(char oldChar, char newChar) Phương thức trả về một chuỗi mới sau khi thay thế tất cả các lần xuất hiện của oldChar trong chuỗi này bằng newChar.
- String[] split(String regex) Phương thức chia chuỗi này thành các phần dựa trên sự khớp với biểu thức chính quy được chỉ định.
- String substring(int beginIndex, int endIndex) Phương thức trả về một chuỗi con mới của chuỗi này.
- char[] toCharArray() Phương thức chuyển đổi chuỗi này thành một mảng ký tự mới.
- String toLowerCase() Phương thức chuyển đổi tất cả các ký tự trong chuỗi thành chữ thường sử dụng quy tắc của ngôn ngữ mặc định.
- String toString() Phương thức trả về đối tượng, mà chính nó đã là một chuỗi.
- String toUpperCase() Phương thức chuyển đổi tất cả các ký tự trong chuỗi thành chữ hoa sử dụng quy tắc của ngôn ngữ mặc định.
- String trim() Phương thức trả về một bản sao của chuỗi sau khi loại bỏ khoảng trắng ở đầu và cuối.
Ví dụ:
public class StringClass {
public void manipulateStrings(String str1, String str2) {
// Concatenate strings
System.out.println("Concatenated string is: " + str1.concat(str2));
// Get a substring
System.out.println("Substring is: " + str1.substring(0, 5));
// Get a character at an index
System.out.println("Character at index 5 is: " + str1.charAt(5));
// Convert string to uppercase
System.out.println("UPPERCASE string form is: " + str1.toUpperCase());
// Get the length of the string
System.out.println("Length of the string is: " + str1.length());
// Split the string
String[] splitted = str1.split("");
for (int i = 0; i < splitted.length; i++) {
System.out.println("Split string is: " + splitted[i]);
}
}
}
public class TestStringDemo {
public static void main(String[] args) {
StringClass objStr = new StringClass();
objStr.manipulateStrings("HelloWorld!", "GoodMorning");
}
}
Lớp StringBuilder và StringBuffer
Các đối tượng StringBuilder tương tự như đối tượng String, ngoại trừ rằng chúng có tính biến đổi (mutable). Bên trong, chương trình chạy xử lý những đối tượng này như các mảng có độ dài biến đổi chứa một chuỗi ký tự. Độ dài và nội dung của chuỗi có thể được thay đổi bất kỳ lúc nào thông qua các cuộc gọi phương thức cụ thể.
Nên sử dụng đối tượng String trừ khi đối tượng StringBuilder mang lại lợi ích về mã nguồn đơn giản hoặc hiệu suất tốt hơn. Ví dụ, khi cần nối nhiều chuỗi lại với nhau, việc thêm chúng vào một đối tượng StringBuilder hiệu quả hơn so với sử dụng toán tử nối chuỗi.
Lớp StringBuilder cũng có một phương thức length() trả về độ dài của chuỗi trong đối tượng StringBuilder. Khác với chuỗi, đối tượng StringBuilder còn có một dung lượng (capacity) chỉ ra số không gian ký tự đã được cấp phát. Dung lượng được trả về bởi phương thức capacity(). Dung lượng luôn lớn hơn hoặc bằng độ dài. Dung lượng tự động mở rộng khi cần để chứa các thêm vào đối tượng StringBuilder.
Bảng dưới liệt kê các hàm khởi tạo (constructors) của lớp StringBuilder:
- StringBuilder(): Phương thức tạo một đối tượng StringBuilder trống với dung lượng ban đầu là 16 phần tử.
- StringBuilder(CharSequence cs): Phương thức xây dựng một đối tượng StringBuilder chứa cùng các ký tự như chuỗi CharSequence được chỉ định, cộng thêm 16 phần tử trống ở sau chuỗi này.
- StringBuilder(int initCapacity): Phương thức tạo một đối tượng StringBuilder trống với dung lượng ban đầu được chỉ định.
- StringBuilder(String str): Phương thức tạo một đối tượng StringBuilder với giá trị ban đầu được khởi tạo bằng chuỗi đã chỉ định, cộng thêm 16 phần tử trống ở sau chuỗi.
Ví dụ:
Tạo lớp StringBuilderDemo :
public class StringBuilderDemo {
StringBuilder sb; // Declare a StringBuilder object
public StringBuilderDemo() {
sb = new StringBuilder(); // Initialize the StringBuilder in the constructor
}
public void addString(String str) {
// Append the string to the StringBuilder
sb.append(str);
System.out.println("Final string: " + sb.toString());
}
}Tạo lớp TestStringBuilder :
public class TestStringBuilder {
public static void main(String[] args) {
StringBuilderDemo sb = new StringBuilderDemo(); // Create an instance of StringBuilderDemo
sb.addString("Java is an ");
sb.addString("object-oriented ");
sb.addString("programming ");
sb.addString("language.");
}
}- void setLength(int newLength): Phương thức này thiết lập độ dài của chuỗi ký tự. Nếu newLength nhỏ hơn length, các ký tự cuối cùng trong chuỗi ký tự bị cắt bỏ. Nếu newLength lớn hơn length, các ký tự null được thêm vào cuối chuỗi ký tự.
- void ensureCapacity(int minCapacity): Phương thức này đảm bảo rằng dung lượng của chuỗi ít nhất bằng với giá trị tối thiểu đã chỉ định.
Here’s the corrected and translated text in Vietnamese:
“Có một số phép toán như append(), insert(), hoặc setLength() có thể được sử dụng để tăng độ dài của chuỗi ký tự trong lớp StringBuilder. Điều này có thể dẫn đến độ dài cuối cùng lớn hơn dung lượng hiện tại. Trong trường hợp đó, dung lượng sẽ tự động được mở rộng.
Các phép toán chính trên lớp StringBuilder mà lớp String không có là các phương thức append() và insert(). Những phương thức này có các phiên bản nạp chồng để chấp nhận dữ liệu của bất kỳ kiểu nào. Tuy nhiên, mỗi phương thức chuyển đổi đối số của nó thành một chuỗi và sau đó, nối hoặc chèn các ký tự của chuỗi mới vào chuỗi ký tự hiện có trong đối tượng StringBuilder. Phương thức append() luôn thêm các ký tự này vào cuối chuỗi ký tự hiện có, trong khi phương thức insert() thêm các ký tự tại chỉ mục cụ thể.
StringBuffer
Lớp StringBuffer tạo ra một chuỗi ký tự có tính bảo đảm đồng bộ, có thể biến đổi. Từ JDK 5, lớp này đã được bổ sung thêm với một lớp tương đương được thiết kế cho việc sử dụng bởi một luồng duy nhất, StringBuilder.
Lớp StringBuilder nên được ưu tiên hơn StringBuffer, vì nó hỗ trợ tất cả các phép toán giống nhưng nhanh hơn do không thực hiện đồng bộ.
Phần khai báo lớp StringBuffer như sau:
public final class StringBuffer
extends Object
implements Serializable, CharSequenceMột bộ đệm chuỗi (string buffer) tương tự như lớp String, ngoại trừ rằng nó có tính biến đổi, giống như StringBuilder.
Tại bất kỳ thời điểm nào, một đối tượng chuỗi ký tự cụ thể có thể chứa một chuỗi cụ thể nào đó. Tuy nhiên, độ dài và nội dung của chuỗi có thể được thay đổi bằng cách gọi các phương thức cụ thể.
Bộ đệm chuỗi (string buffer) an toàn để sử dụng bởi nhiều luồng. Các phương thức được đồng bộ hóa khi cần thiết. Điều này làm cho tất cả các hoạt động trên một trường hợp cụ thể có hành vi như chúng xảy ra theo một thứ tự tuần tự nào đó. Điều đó có nghĩa là chúng tuân thủ với thứ tự của các cuộc gọi phương thức được thực hiện bởi từng luồng riêng lẻ mà tham gia vào.
Tất cả các hoạt động có thể được thực hiện trên lớp StringBuilder cũng áp dụng cho lớp StringBuffer. Nói cách khác, các phương thức append() và insert() được sử dụng với lớp StringBuffer sẽ tạo ra cùng kết quả khi được sử dụng với lớp StringBuilder. Tuy nhiên, mỗi khi có một hoạt động như append hoặc insert liên quan đến một chuỗi nguồn, lớp này đồng bộ hóa chỉ trên bộ đệm chuỗi (string buffer) thực hiện hoạt động và không đồng bộ trên nguồn dữ liệu. Tương tự, giống với StringBuilder, mỗi đối tượng chuỗi ký tự cũng có một dung lượng. Ngoài ra, nếu bộ đệm nội bộ tràn, nó sẽ tự động mở rộng.
Phương thức String resolveConstantDesc (MethodHandles.Lookup lookup)
Phương thức resolveConstantDesc(MethodHandles.Lookup) là một phương thức phân tích bytecode công khai được giới thiệu trong Java 12 như một phần của Constants API.
Nó được khai báo trong giao diện ConstantDesc, được thực hiện trong lớp String. Một kiểu ‘constable’ là một chuỗi có giá trị là các hằng số có thể được biểu diễn trong bể hằng số của một tệp lớp Java và các thể hiện của nó có thể mô tả chính họ một cách danh định như một ConstantDesc.
Ví dụ:
public class StringResolveConstantDemo {
public static void main(String[] args) {
String strA = "Don't just learn the tricks of the trade, learn the trade.";
String strB = strA.resolveConstantDesc(null);
System.out.println("Outcome of the code: Comparing the objects");
System.out.println(strB.equals(strA));
System.out.println(strA);
}
}
Trong Đoạn mã trên, biến strA được điền bằng một chuỗi, và resolveConstantDesc() được gọi. Phương thức này giải quyết thể hiện String mà nó được gọi như một ConstantDesc. Trong trường hợp này, thể hiện đó là strA. Kết quả của phương thức là thể hiện String chính nó. Do đó, thể hiện được trả về của strA được gán cho strB. Khi so sánh hai đối tượng chuỗi bằng cách sử dụng phương thức equals() cũng như toán tử ==, kết quả là true. Điều này là do cả hai chuỗi bây giờ đều tham chiếu đến cùng một đối tượng.
Lưu ý: Các phương thức Constants API ít khi được các nhà phát triển sử dụng cho các nhiệm vụ phát triển bình thường. Chúng là các API cấp thấp và được sử dụng trong các thư viện và công cụ cung cấp phân tích và tạo bytecode.
indent (int n)
Phương thức indent() trong lớp java.lang.String đã được giới thiệu trong Java SE 12. Phương thức này được sử dụng để thêm hoặc loại bỏ dấu cách từ đầu dòng để điều chỉnh việc lùi vào cho từng dòng chuỗi.
Cú pháp:
public String indent(int n)Tham số n sử dụng số nguyên n làm đầu vào và thực hiện lùi vào tương ứng. Giá trị n biểu thị số khoảng trắng cần thêm hoặc loại bỏ.
- Thông thường, chuỗi được chia thành từng dòng sử dụng phương thức lines().
- Sau đó, mỗi dòng được lùi vào dựa trên giá trị lùi vào được chỉ định như tham số.
- Nếu n > 0, thì n khoảng trắng (U+0020) được thêm vào đầu mỗi dòng.
- Nếu n < 0, thì tối đa ‘n’ ký tự trắng được xóa từ đầu dòng. Lưu ý rằng ký tự tab (\t) được xem xét là một ký tự riêng lẻ. Nếu dòng không chứa đủ khoảng trắng đầu, thì tất cả khoảng trắng đầu sẽ bị xóa.
- Nếu n = 0, thì các dòng tiếp tục không bị ảnh hưởng.
- Cuối cùng, tất cả các dòng được thêm vào “\n”, ghép lại và trả về.
- Nếu chuỗi trống, thì chuỗi trống được trả về.
Phương thức transform(Function f)
Phương thức transform() được sử dụng để áp dụng một hàm cho một chuỗi đầu vào. Hàm này nên chấp nhận một chuỗi là đối số và trả về một đối tượng. Nói một cách đơn giản, phương thức này chấp nhận một chuỗi làm đầu vào và biến đổi nó thành một chuỗi mới bằng cách sử dụng một Function. Việc thêm phương thức tiện ích này đã được thực hiện trong phiên bản Java 12 của lớp String.
Trong các hàm biến đổi String, cần có một đối tượng String làm dữ liệu đầu vào. “Pill” là tên được đặt để đặt một số dữ liệu được định trước lên hàng đợi và phải là mục cuối cùng trên hàng đợi. Khi trình tiêu thụ dữ liệu (consumer) đọc “Pill”, mục này sẽ tắt cho một quá trình tiêu thụ phân phối riêng biệt.
Nếu pill không phải phần tử cuối cùng trong hàng đợi, thì có thể xảy ra một sự tắt mạch duy nhất của consumer.
Cú pháp:
public <R> R transform(Function<? super String, ? extends R> f) {
return f.apply(this);
}Ví dụ:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package com.mycompany.testassertion;
/**
*
* @author toan1
*/
public class StringTransform {
public static void main(String[] args) {
String str = "Life's too short";
var result = str.transform(input -> input.concat("to eat bad food")).transform(String::toUpperCase);
System.out.println(result.toString());
}
}Phương thức Optional describeConstable()
describeConstable() là một phương thức của lớp String. Không cần thiết cho một Constable phải giải thích tất cả các trường hợp của nó dưới dạng một ConstantDesc (mô tả hằng số) hoặc có thể chọn không làm điều đó. Phương thức này trả về một Optional trống để cho thấy rằng không thể tạo ra một mô tả danh nghĩa cho một trường hợp cụ thể.
describeConstable() cũng là một phương thức cấp byte được lấy từ giao diện Constable. Nó trả về một phiên bản tùy chọn của đối tượng chứa mô tả danh nghĩa cho trường hợp này.
Ví dụ:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package com.mycompany.testassertion;
import java.util.Optional;
/**
*
* @author toan1
*/
public class DescribeConstableExam {
public static void main(String[] args) {
Integer x = 25;
Optional<Integer> opt = x.describeConstable();
System.out.println(opt);
}
}Output:
Optional[25]Ví dụ 2:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package com.mycompany.testassertion;
import java.util.Optional;
/**
*
* @author toan1
*/
public class DescribeConstableExam {
public static void main(String[] args) {
String str = "Hello there";
Optional<String> optStr = str.describeConstable();
optStr.ifPresent(value -> {
System.out.println("Value: "+optStr.get());
});
}
}Trong ví dụ trên một chuỗi đầu vào được lưu trữ trong biến str. Bằng cách truyền biến này vào đối tượng Optional thông qua phương thức describeConstable(), giá trị của biến str trở thành hằng số. Tuy nhiên, ở đây điều này không có ích lắm. Trong các ứng dụng thực tế phức tạp, phương thức này có thể được sử dụng như một phương thức API cấp thấp để thực hiện chức năng phân tích và tạo mã bytecode.
Phân tích Văn bản bằng Lớp StringTokenizer
Phân tích Văn bản bằng Lớp StringTokenizer
Có nhiều kỹ thuật để phân tích văn bản. Các công cụ phổ biến nhất bao gồm:
- Phương thức string.split()
- Các lớp stringTokenizer và streamTokenizer
- Lớp Scanner
- Các lớp Pattern và Matcher, thực hiện biểu thức chính quy
- Đối với các nhiệm vụ phân tích phức tạp nhất, có thể sử dụng các công cụ như JavaCC.
Lớp StringTokenizer thuộc gói java.util và được sử dụng để chia một chuỗi thành các “token” (đoạn văn bản nhỏ). Lớp này được khai báo như sau:
public class StringTokenizer extends Object implements EnumerationPhương pháp phân mảnh của lớp StringTokenizer đơn giản hơn so với lớp StreamTokenizer. Các phương thức của lớp StringTokenizer không phân biệt giữa số, tên và chuỗi được đặt trong dấu ngoặc kép. Họ cũng không nhận biết và bỏ qua các phần comment.
Bộ các ký tự ngăn cách các “token” (đoạn văn bản nhỏ), có thể được chỉ định hoặc tại thời điểm tạo đối tượng StringTokenizer hoặc cho từng “token” riêng lẻ.
Bảng dưới liệt kê các hàm khởi tạo của lớp StringTokenizer.
- StringTokenizer (String str) Tạo một đối tượng StringTokenizer cho chuỗi cụ thể.
- StringTokenizer (String str, String delim) Tạo một đối tượng StringTokenizer trống cho chuỗi cụ thể. Tham số delim chỉ định ký tự phân tách được sử dụng cho việc tạo token.
- StringTokenizer (String str, String delim, boolean returnDelims) Tạo một đối tượng StringTokenizer trống cho chuỗi cụ thể. Tham số delim chỉ định ký tự phân tách được sử dụng cho việc tạo token. Nếu returnDelims được đặt thành true, các ký tự phân tách cũng được trả về dưới dạng token.
Một đối tượng StringTokenizer hoạt động theo một trong những cách sau, tùy thuộc vào giá trị của cờ returnDelims khi nó được tạo:
- Nếu cờ là false, các ký tự ngăn cách được sử dụng để tách các “token”. Một “token” là một chuỗi tối đa gồm các ký tự liên tiếp không phải là ký tự ngăn cách.
- Nếu cờ là true, các ký tự ngăn cách được xem xét là các “token” riêng lẻ. Một “token” có thể là một ký tự ngăn cách hoặc một chuỗi tối đa gồm các ký tự liên tiếp không phải là ký tự ngăn cách.
Một đối tượng StringTokenizer bên trong duy trì một vị trí hiện tại trong chuỗi cần tách thành “token”. Một số thao tác làm tiến xa vị trí hiện tại này qua các ký tự đã được xử lý. Một “token” được trả về bằng cách lấy một phần chuỗi của chuỗi đã được sử dụng để tạo đối tượng StringTokenizer.
Có một số phương thức quan trọng của lớp StringTokenizer:
- countTokens(): Phương thức này tính toán số lần mà phương thức nextToken của đối tượng StringTokenizer có thể được gọi trước khi nó sinh ra một ngoại lệ. Phương thức này trả về cùng một giá trị như phương thức hasMoreTokens.
- hasMoreTokens() : Phương thức này kiểm tra xem có thêm “token” khả dụng từ chuỗi của đối tượng StringTokenizer không. Nó trả về true nếu còn “token” và false nếu không còn.
- nextElement(): Phương thức này trả về giá trị tương tự như nextToken, ngoại trừ rằng giá trị trả về được khai báo là Object thay vì String.
- nextToken(): Phương thức này trả về “token” tiếp theo từ chuỗi của đối tượng StringTokenizer.
- nextToken(String delim): Phương thức này trả về “token” tiếp theo trong chuỗi của đối tượng StringTokenizer. Ký tự delim được sử dụng để xác định ký tự ngăn cách để tách “token”.
- hasMoreElements(): Phương thức này tương tự như hasMoreTokens, nó kiểm tra xem có thêm phần tử khả dụng từ chuỗi của StringTokenizer không.
Những phương thức này cho phép bạn tách một chuỗi thành các “token” dựa trên các ký tự ngăn cách.
import java.util.StringTokenizer;
public class StringToken {
public void tokenizeString(String str, String delim) {
StringTokenizer st = new StringTokenizer(str, delim);
while (st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
}
public static void main(String[] args) {
StringToken objST = new StringToken();
objST.tokenizeString("Java,is,a,programming,language", ",");
}
}
Output:
Java
is
a
programming
language
Lớp StringTokenizer là một lớp “cổ điển” đã được giữ lại cho mục đích tương thích ngược với mã nguồn cũ. Các phương thức của nó không phân biệt giữa các từ khóa, số và chuỗi có dấu ngoặc kép, cũng như không nhận biết và bỏ qua các comment. Tuy nhiên, việc sử dụng lớp này không được khuyến nghị trong mã nguồn mới. Thay vào đó, nên sử dụng phương thức split() của lớp String hoặc gói java.util.regex để tách chuỗi thành các “token” thay vì sử dụng StringTokenizer.
Việc sử dụng split() hoặc các biểu thức chính quy (regex) cung cấp một cách linh hoạt hơn và mạnh mẽ hơn cho việc tách chuỗi thành các phần từ dựa trên quy tắc tùy chỉnh.
Biểu thức chính quy (Regular Expression)
Các biểu thức chính quy (regular expressions) được sử dụng để mô tả một tập hợp các chuỗi dựa trên các đặc điểm chung được chia sẻ bởi các chuỗi riêng lẻ trong tập hợp đó. Chúng được sử dụng để chỉnh sửa, tìm kiếm hoặc thao tác văn bản và dữ liệu. Để tạo ra các biểu thức chính quy, bạn cần học một cú pháp riêng biệt vượt ra ngoài cú pháp thông thường của Java. Biểu thức chính quy khác nhau về độ phức tạp, nhưng một khi bạn đã hiểu cách tạo ra chúng, việc hiểu hoặc tạo ra bất kỳ biểu thức chính quy nào cũng trở nên dễ dàng.
API Biểu thức chính quy
Trong Java, bạn có thể sử dụng API java.util.regex để tạo các biểu thức chính quy.
Có ba lớp chính trong gói java.util.regex cần thiết để tạo ra biểu thức chính quy. Chúng là:
- Pattern: Một đối tượng Pattern là phiên bản đã biên dịch của một biểu thức chính quy. Không có hàm tạo công cộng nào trong lớp Pattern. Để tạo ra một mẫu, bạn cần gọi một trong các phương thức tĩnh compile() của nó. Những phương thức này sẽ trả về một thể hiện của lớp Pattern. Đối số đầu tiên của những phương thức này là biểu thức chính quy.
- Matcher: Một đối tượng Matcher được sử dụng để diễn dịch mẫu và thực hiện các hoạt động so khớp với một chuỗi đầu vào. Tương tự như lớp Pattern, lớp Matcher cũng không cung cấp hàm tạo công cộng. Để có được một đối tượng Matcher, bạn cần gọi phương thức matcher() trên một đối tượng Pattern.
- PatternSyntaxException: Một đối tượng PatternSyntaxException là một ngoại lệ không kiểm tra được sử dụng để chỉ ra lỗi cú pháp trong một biểu thức chính quy.
Lớp Pattern
Mọi biểu thức chính quy được chỉ định dưới dạng chuỗi phải được biên dịch trước thành một thể hiện của lớp Pattern. Đối tượng mẫu kết quả sau đó có thể được sử dụng để tạo ra một đối tượng Matcher. Một khi bạn có đối tượng Matcher, bạn có thể so khớp chuỗi ký tự tùy ý với biểu thức chính quy. Tất cả các trạng thái khác nhau liên quan đến việc thực hiện một trận đấu nằm trong đối tượng Matcher; vì vậy, nhiều Matcher có thể chia sẻ cùng một mẫu.
Cú pháp:
public final class Pattern extends Object implements Serializable
Tuần tự thao tác:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package com.mycompany;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author toan1
*/
public class ExampleRegex {
public static void main(String[] args) {
// Tạo đối tượng Pattern với biểu thức chính quy
Pattern p = Pattern.compile("a*b");
// Tạo đối tượng Matcher bằng cách sử dụng đối tượng Pattern với chuỗi đầu vào
Matcher m = p.matcher("baaab");
// Kiểm tra sự trùng khớp
Boolean b = m.matches();
System.out.println("Chuoi "+m.toString()+ (b ? "so khop " : "khong khop ") + "voi mau" + p.toString());
}
}
Phương thức matches() của lớp Matcher được định nghĩa để sử dụng khi biểu thức chính quy được sử dụng một lần. Phương thức này sẽ biên dịch biểu thức và khớp nó với một chuỗi đầu vào trong một lần gọi duy nhất. Lệnh:
boolean b = Pattern.matches("a*b", "aaaaab");là một câu lệnh tương đương với ba câu lệnh được sử dụng trước đó. Tuy nhiên, đối với các trận đấu lặp đi lặp lại, nó không hiệu quả bằng vì nó không cho phép mẫu đã biên dịch được sử dụng lại.
Thể hiện của lớp Pattern là không thay đổi (immutable) và do đó an toàn cho việc sử dụng bởi nhiều luồng (threads) chạy đồng thời, trong khi các thể hiện của lớp Matcher thì không an toàn cho việc sử dụng đa luồng.
Lớp Matcher
Một đối tượng Matcher được tạo ra từ một Pattern bằng cách gọi phương thức matcher() trên đối tượng Pattern. Một đối tượng Matcher chính là bộ máy thực hiện các hoạt động so khớp trên một chuỗi ký tự bằng cách diễn dịch một Pattern. Khai báo của lớp Matcher như sau:
public final class Matcher extends Object implements MatchResultSau khi tạo, một đối tượng Matcher có thể được sử dụng để thực hiện ba loại hoạt động so khớp khác nhau:
- Phương thức matches() được sử dụng để so khớp toàn bộ chuỗi đầu vào với mẫu.
- Phương thức lookingAt() được sử dụng để so khớp chuỗi đầu vào, bắt đầu từ đầu, với mẫu.
- Phương thức find() được sử dụng để quét chuỗi đầu vào để tìm chuỗi con kế tiếp khớp với mẫu.
Kiểu trả về của mỗi phương thức này là một boolean cho biết kết quả thành công hoặc thất bại. Thông tin bổ sung về kết quả thành công có thể được truy xuất bằng cách truy vấn trạng thái của bộ so khớp.
Bộ so khớp tìm kiếm kết quả trong một phần của đầu vào của nó, được gọi là “vùng”. Mặc định, vùng chứa toàn bộ đầu vào của bộ so khớp. Vùng có thể được sửa đổi bằng cách sử dụng phương thức region(). Để truy vấn vùng, bạn có thể sử dụng phương thức regionStart() và regionEnd(). Bạn cũng có thể thay đổi cách biên giới vùng tương tác với một số mẫu cấu trúc.
Lớp Matcher bao gồm các phương thức chỉ số cung cấp các giá trị chỉ mục hữu ích cho biết chính xác nơi tìm thấy kết quả trong chuỗi đầu vào. Các phương thức này bao gồm:
- public int start(): Trả về chỉ mục bắt đầu của kết quả trước đó.
- public int start(int group): Trả về chỉ mục bắt đầu của chuỗi con được chụp bởi nhóm đã cho trong hoạt động so khớp trước đó.
- public int end(): Trả về vị trí sau ký tự cuối cùng khớp.
- public int end(int group): Trả về vị trí sau ký tự cuối cùng của chuỗi con được chụp bởi nhóm đã cho trong hoạt động so khớp trước đó.
Một số phương thức lớp Matcher:
Matcher là một lớp trong Java được sử dụng để thực hiện các phép so khớp với các biểu thức chính quy. Dưới đây là một số phương thức quan trọng của lớp Matcher:
- appendReplacement(StringBuffer sb, String replacement): Phương thức thực hiện một bước thêm và thay thế không kết thúc.
- appendTail(StringBuffer sb): Phương thức thực hiện bước cuối cùng của thêm và thay thế.
- find(): Phương thức tìm kiếm chuỗi con tiếp theo của đầu vào khớp với mẫu.
- find(int start): Phương thức đặt lại bộ so khớp và sau đó, tìm chuỗi con tiếp theo của đầu vào khớp với mẫu, bắt đầu từ chỉ mục đã cho.
- group(): Phương thức trả về chuỗi con của đầu vào khớp với kết quả trước đó.
- group(int group): Phương thức trả về chuỗi con của đầu vào được chụp bởi nhóm đã cho trong kết quả trước đó.
- group(String name): Phương thức trả về chuỗi con của đầu vào được chụp bởi nhóm có tên đã cho trong kết quả trước đó.
- groupCount(): Phương thức trả về số lượng nhóm đã chụp trong mẫu của bộ so khớp.
- hitEnd(): Phương thức trả về true nếu trình tìm kiếm gặp cuối của đầu vào trong lần tìm kiếm trước đó.
- lookingAt(): Phương thức so khớp chuỗi đầu vào với mẫu, bắt đầu từ đầu của vùng.
- matches(): Phương thức so khớp toàn bộ vùng với mẫu.
- pattern(): Phương thức trả về mẫu được diễn dịch bởi bộ so khớp.
- quoteReplacement(String s): Phương thức trả về một chuỗi thay thế chính xác cho chuỗi đã cho.
- region(int start, int end): Phương thức đặt giới hạn vùng của bộ so khớp.
- regionEnd(): Phương thức báo cáo chỉ số kết thúc (không tính) của vùng bộ so khớp.
- regionStart(): Phương thức báo cáo chỉ số bắt đầu của vùng bộ so khớp.
- replaceAll(String replacement): Phương thức thay thế mọi chuỗi con của đầu vào khớp với chuỗi thay thế đã cho.
- replaceFirst(String replacement): Phương thức thay thế chuỗi con đầu tiên của đầu vào khớp với chuỗi thay thế đã cho.
- requireEnd(): Phương thức trả về true nếu có thể cần thêm đầu vào để thay đổi một kết quả tích cực thành kết quả tiêu cực.
- reset(): Phương thức đặt lại bộ so khớp.
- reset(CharSequence input): Phương thức đặt lại bộ so khớp với một đầu vào mới.
- start(): Phương thức trả về chỉ số bắt đầu của kết quả trước đó.
- start(int group): Phương thức trả về chỉ số bắt đầu của chuỗi con được chụp bởi nhóm đã cho trong kết quả trước đó.
- toMatchResult(): Phương thức trả về trạng thái khớp của bộ so khớp dưới dạng một đối tượng MatchResult.
- toString(): Phương thức trả về biểu diễn chuỗi của bộ so khớp.
- usePattern(Pattern newPattern): Phương thức thay đổi mẫu mà bộ so khớp này sử dụng để tìm kiếm khớp.
Lớp Matcher được sử dụng để tìm kiếm các chuỗi con khớp với biểu thức chính quy trong đầu vào và thực hiện các hoạt động thay thế và truy vấn liên quan đến kết quả khớp.
Bộ so khớp Matcher có trạng thái rõ ràng và trạng thái ngầm định:
Trạng thái rõ ràng bao gồm:
- Chỉ số bắt đầu và kết thúc của sự khớp thành công gần đây nhất.
- Chỉ số bắt đầu và kết thúc của chuỗi con đầu vào được chụp bởi mỗi nhóm chụp trong biểu thức chính quy.
- Tổng số lần xuất hiện của các chuỗi con như vậy.
Các phương thức cung cấp cơ hội trả về các chuỗi con đã chụp này dưới dạng chuỗi.
Trạng thái rõ ràng của một bộ so khớp ban đầu không xác định. Tại thời điểm này, bất kỳ cố gắng truy vấn bất kỳ phần nào của kết quả khớp sẽ gây ra ngoại lệ IllegalStateException. Trạng thái rõ ràng của một bộ so khớp được tính toán lại sau mỗi phép khớp.
Trạng thái ngầm định của bộ so khớp bao gồm:
- Chuỗi ký tự đầu vào.
- Vị trí nối, ban đầu là số không. Nó được cập nhật bởi phương thức appendReplacement().
Phương thức reset() giúp bộ so khớp được đặt lại một cách rõ ràng. Nếu muốn sử dụng một chuỗi đầu vào mới, phương thức reset(CharSequence) có thể được gọi. Thao tác đặt lại trên một bộ so khớp loại bỏ thông tin trạng thái rõ ràng của nó và đặt vị trí nối về số không.
Các thể hiện của lớp Matcher không an toàn để sử dụng bởi nhiều luồng song song.
Ví dụ:
package com.mycompany;
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
import java.util.regex.Pattern;
import java.util.regex.Matcher;
import java.util.Scanner;
public class ExampleMatcher {
public static void main(String[] args) {
String flag;
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.print("Enter expression: ");
Pattern pattern = Pattern.compile(scanner.next()); // khoi tao mau
scanner.nextLine(); // Consume the newline character
System.out.print("Enter string to search: ");
Matcher matcher = pattern.matcher(scanner.nextLine()); // khoi tao chuoi de tim mau trong chuoi
boolean found = false;
while (matcher.find()) {
System.out.printf("Found the text \"%s\" starting at index %d and ending at index %d.%n",
matcher.group(), matcher.start(), matcher.end());
found = true;
}
if (!found) {
System.out.println("No match found.");
}
System.out.print("Press 'x' to exit or 'y' to continue: ");
flag = scanner.next();
if (flag.equals("x")) {
System.exit(0);
} else {
scanner.nextLine(); // Consume the newline character
continue;
}
}
}
}
Output:
Enter expression: \b\w+\b
Enter string to search: This is a sample text.
Found the text "This" starting at index 0 and ending at index 4.
Found the text "is" starting at index 5 and ending at index 7.
Found the text "a" starting at index 8 and ending at index 9.
Found the text "sample" starting at index 10 and ending at index 16.
Found the text "text" starting at index 17 and ending at index 21.
Press 'x' to exit or 'y' to continue: y
Enter expression: \d{3}-\d{2}-\d{4}
Enter string to search: My social security number is 123-45-6789.
Found the text "123-45-6789" starting at index 30 and ending at index 41.
Press 'x' to exit or 'y' to continue: x
Trong đoạn mã, một vòng lặp while đã được tạo bên trong lớp RegexTest. Bên trong vòng lặp, một đối tượng Pattern được tạo và khởi tạo với biểu thức chính quy được nhận từ đầu vào. Hai dòng sau được sử dụng để thực hiện hành động này:
Scanner scanner = new Scanner(System.in);
Pattern pattern1 = Pattern.compile(scanner.next());Lớp java.util.Scanner đại diện cho một trình quét văn bản đơn giản có thể phân tích cú pháp các loại nguyên thủy và chuỗi bằng cách sử dụng biểu thức chính quy. Nó thường được sử dụng để chấp nhận đầu vào từ người dùng từ bàn phím.
Tương tự, đối tượng Matcher đã được tạo và khởi tạo với chuỗi đầu vào được chỉ định khi chạy chương trình. Tiếp theo, một vòng lặp while khác đã được tạo để lặp cho đến khi phương thức find() trả về true. Bên trong vòng lặp, các phương thức group(), start(), và end() được sử dụng để hiển thị văn bản, chỉ số bắt đầu và chỉ số kết thúc tương ứng. Đầu ra đã được định dạng bằng cách sử dụng phương thức format().
Biến found được đặt thành true khi một sự khớp được tìm thấy. Khi không tìm thấy sự khớp nào, thông báo thích hợp được hiển thị cho người dùng. Cuối cùng, người dùng được hỏi liệu họ có muốn tiếp tục hay không. Nếu người dùng cung cấp “x” làm đầu vào, ứng dụng sẽ kết thúc. Nếu không, vòng lặp while bên ngoài tiếp tục.
Chuỗi ký tự (String Literal)
Hình thức khớp mẫu cơ bản nhất được hỗ trợ bởi API java.util.regex là việc khớp một chuỗi ký tự. Ví dụ, xem xét biểu thức chính quy là “abe” và chuỗi đầu vào là “abcdefabeghi” trong Đoạn mã dưới. Tiến trình khớp sẽ thành công vì biểu thức chính quy được tìm thấy trong chuỗi. Lưu ý rằng trong tiến trình khớp, chỉ số bắt đầu được tính từ 0. Theo quy ước, các phạm vi bao gồm chỉ số bắt đầu và không bao gồm chỉ số cuối. Mỗi ký tự trong chuỗi nằm trong một ô riêng biệt, với chỉ số chỉ đến giữa mỗi ô như thể hiện trong Hình:

Chuỗi “abedefabeghi” bắt đầu tại chỉ số 0 và kết thúc tại chỉ số 12, mặc dù chính các ký tự chỉ chiếm các ô 0, 1, … và 11.
Nếu chuỗi tìm kiếm được thay đổi thành “abcabcabcabc,” với các khớp sau đó, một số sự chồng chéo được thấy. Chỉ số bắt đầu cho cuộc khớp tiếp theo là giống như chỉ số kết thúc của cuộc khớp trước đó, như thể hiện trong đoạn mã ở phần trước với input pattern là abc và chuỗi cần so khớp là abcabcabcabc
Enter expression: abc
Enter string to search: abcabcabcabc
Found the text "abc" starting at index 0 and ending at index 3.
Found the text "abc" starting at index 3 and ending at index 6.
Found the text "abc" starting at index 6 and ending at index 9.
Found the text "abc" starting at index 9 and ending at index 12.
Press 'x' to exit or 'y' to continue: x
Siêu ký tự (Metacharacters)
API này cũng hỗ trợ nhiều ký tự đặc biệt. Điều này ảnh hưởng đến cách một mẫu được khớp. Ví dụ, nếu biểu thức chính quy được thay đổi thành ‘abc.’ và chuỗi đầu vào thành ‘abcd’ cho Đoạn mã trên, đầu ra sẽ xuất hiện như được hiển thị như sau:
Enter expression: abc.
Enter string to search: abcd
Found the text "abc" starting at index 0 and ending at index 3.
Press 'x' to exit or 'y' to continue: x
Việc khớp vẫn thành công, ngay cả khi dấu chấm '.' không tồn tại trong chuỗi đầu vào. Điều này bởi vì dấu chấm là một ký tự metacharacter, tức là một ký tự có ý nghĩa đặc biệt được hiểu bởi trình khớp. Đối với trình khớp, ký tự metacharacter ‘.’ đại diện cho ‘bất kỳ ký tự’. Đây là lý do tại sao khớp thành công trong ví dụ.
Các ký tự metacharacter được hỗ trợ bởi API là:
<({\[−=$!|]})?*Người dùng có thể buộc ký tự metacharacter được xem xét như một ký tự thông thường bằng một trong những cách sau:
Bằng cách đặt trước ký tự metacharacter bằng dấu gạch chéo.
Bằng cách bao quanh nó trong \Q (bắt đầu trích dẫn) và \E (kết thúc trích dẫn). \Q và \E có thể được đặt ở bất kỳ vị trí nào trong biểu thức. Tuy nhiên, \Q phải đứng đầu.
Ví dụ:
Enter expression: abc\.
Enter string to search: abcd
No match found
Press 'x' to exit or 'y' to continue: xLớp ký tự (Character Classes)
Từ ‘class’ trong cụm từ ‘character class’ không có nghĩa là một tệp .class. Nó liên quan đến biểu thức chính quy, một character class là một tập hợp các ký tự được bao quanh bởi dấu ngoặc vuông. Nó cho biết các ký tự mà một ký tự duy nhất từ chuỗi đầu vào sẽ khớp thành công.
Bảng dưới tổng hợp các biểu thức chính quy được hỗ trợ trong ‘Character Classes’:
- [abc] – Đây là một class đơn giản chứa các ký tự a, b hoặc c.
- [^abc] – Phủ định: Bất kỳ ký tự nào trừ a, b, hoặc c.
- [a-zA-Z] – Khoảng từ a đến z hoặc từ A đến Z (bao gồm cả hai).
- [a-d[m-p]] – Liên hợp: Từ a đến d hoặc từ m đến p: [a-dm-p]
- [a-z&&[bc]] – Giao nhau: Chỉ có b và c.
- [a-z&&[^bc]] – Phần dư: Tất cả từ a đến z trừ b và c: [ad-z]
- [a-z&&[^m-p]] – Phần dư: Từ a đến z, loại trừ từ m đến p: [a-lq-z]
Ví dụ:
Enter expression: [a-d[m-p]]
Enter string to search: o
Found the text "o" starting at index 0 and ending at index 1.
Press 'x' to exit or 'y' to continue: y
Enter expression: [a-z&&[^m-p]]
Enter string to search: p
No match found.Lớp cơ bản (Simple Classes)
Đây là dạng cơ bản nhất của một lớp ký tự. Nó được tạo bằng cách chỉ định một tập hợp các ký tự được liệt kê bên cạnh nhau trong ngoặc vuông. Ví dụ, biểu thức thông thường [gmc] sẽ khớp với các từ “gat”, “mat” hoặc “cat”. Điều này bởi vì lớp này định nghĩa một lớp ký tự chấp nhận ‘g’, ‘m’, hoặc ‘c’ làm ký tự đầu tiên. Hình dưới cho thấy kết quả khi biểu thức và chuỗi đầu vào được sửa đổi trong đoạn mã ví dụ trước:
Enter expression: [hbd]ello
Enter string to search: hello
Found the text "hello" starting at index 0 and ending at index 5.
Press 'x' to exit or 'y' to continue: y
Enter expression: [hbd]ello
Enter string to search: dello
Found the text "dello" starting at index 0 and ending at index 5.
Press 'x' to exit or 'y' to continue: y
Enter expression: [hbd]ello
Enter string to search: mello
No match found.Phủ định (Negation)
Phủ định được sử dụng để khớp tất cả các ký tự ngoại trừ những ký tự được liệt kê trong ngoặc vuông. Ký tự ‘^’ được chèn vào đầu của lớp ký tự để thực hiện phủ định.
Hình dưới mô tả việc sử dụng phủ định:
Enter expression: [^hbd]ello
Enter string to search: hello
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: [^hbd]ello
Enter string to search: cello
Found the text "cello" starting at index 0 and ending at index 5.Một vùng/dãy (Ranges)
Đôi khi, có thể cần định nghĩa một lớp ký tự bao gồm một dãy giá trị, như chữ cái ‘a tới f hoặc số từ 1 đến 5’. Một dãy có thể được chỉ định bằng cách đơn giản là chèn ký tự ‘-‘ giữa ký tự đầu tiên và ký tự cuối cùng mà bạn muốn khớp. Ví dụ, [a-h] hoặc [1-5] có thể được sử dụng cho một dãy. Bạn cũng có thể đặt các dãy khác nhau cạnh nhau trong lớp để mở rộng khả năng khớp. Ví dụ, [a-zA-Z] sẽ khớp với bất kỳ chữ cái nào trong bảng chữ cái từ a đến z (chữ thường) hoặc A đến Z (chữ in hoa).
Ví dụ:
Enter expression: [a-zA-Z]
Enter string to search: 1
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: [a-zA-Z]
Enter string to search: k
Found the text "k" starting at index 0 and ending at index 1.
Press 'x' to exit or 'y' to continue: y
Enter expression: [1-5]
Enter string to search: a
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: [a-zA-Z1-5]
Enter string to search: 5
Found the text "5" starting at index 0 and ending at index 1.Hợp nhất (Union)
Có thể sử dụng phép hợp để tạo một lớp ký tự duy nhất bao gồm hai hoặc nhiều lớp ký tự riêng biệt. Điều này có thể thực hiện bằng cách đơn giản là lồng một lớp trong lớp khác. Ví dụ, phép hợp [a-d[f-h]] tạo ra một lớp ký tự duy nhất khớp với các ký tự a, b, c, d, f, g và h.
Ví dụ:
Enter expression: [a-d[f-h]]
Enter string to search: a
Found the text "a" starting at index 0 and ending at index 1.
Press 'x' to exit or 'y' to continue: y
Enter expression: [a-d[f-h]]
Enter string to search: h
Found the text "h" starting at index 0 and ending at index 1.Giao điểm (Intersections)
iao điểm (Intersection) được sử dụng để tạo một lớp ký tự duy nhất chỉ khớp với các ký tự chung cho tất cả các lớp ký tự con của nó. Điều này được thực hiện bằng cách sử dụng &&, ví dụ như trong [0-6&&[234]]. Điều này tạo ra một lớp ký tự duy nhất chỉ khớp với các số chung cho cả hai lớp ký tự con, nghĩa là 2, 3 và 4.
Ví dụ:
Enter expression: [0-6&&[234]]
Enter string to search: 1
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: [0-6&&[234]]
Enter string to search: 3
Found the text "3" starting at index 0 and ending at index 1.
Press 'x' to exit or 'y' to continue: y
Enter expression: [a-z&&[abcde]]
Enter string to search: g
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: [a-z&&[abcde]]
Enter string to search: e
Found the text "e" starting at index 0 and ending at index 1.Phép trừ (Subtraction)
có thể được sử dụng để phủ định một hoặc nhiều lớp ký tự con lồng nhau, chẳng hạn như [0-6&&[^234)]. Trong trường hợp này, lớp ký tự sẽ khớp với tất cả từ 0 đến 6, ngoại trừ các số 2, 3 và 4. Hình dưới mô tả việc sử dụng phép trừ.
Ví dụ:
Enter expression: [0-6&&[^234]]
Enter string to search: 1
Found the text "1" starting at index 0 and ending at index 1.Lớp ký tự định nghĩa trước (Predefined Character Classes)
Có một số lớp ký tự được xác định trước trong API Pattern. Các lớp này cung cấp các phím tắt tiện lợi cho các biểu thức thông thường được sử dụng. Bảng dưới liệt kê các lớp ký tự được xác định trước:
- .: Bất kỳ ký tự nào (có thể khớp hoặc không khớp với các ký tự kết thúc dòng)
- \d: Một chữ số: [0-9]
- \D: Một ký tự không phải là chữ số: [^0-9]
- \s: Một ký tự khoảng trắng: [ \t\n\x0B\f\r]
- \S: Một ký tự không phải khoảng trắng: [^\s]
- \w: Một ký tự từ: [a-zA-Z0-9_]
- \W: Một ký tự không phải từ: [^\w]
Ở đây, \d được sử dụng để chỉ định phạm vi của các chữ số (0-9) và \w có nghĩa là một ký tự từ, tức là bất kỳ chữ cái thường nào, chữ cái hoa nào, ký tự gạch dưới hoặc bất kỳ chữ số nào. Sử dụng các lớp đã được xác định trước khi áp dụng giúp làm cho mã dễ đọc hơn và loại bỏ các lỗi được gây ra bởi các lớp ký tự bị định dạng sai.
Các ký tự được bắt đầu bằng dấu gạch chéo được gọi là các construct đã được escape. Khi các construct đã được escape được sử dụng trong một chuỗi ký tự, dấu gạch chéo phải được đặt trước bằng một dấu gạch chéo khác để chuỗi có thể biên dịch. Ví dụ:
private final String regex = "\\d";Ở đây, \d là biểu thức chính quy và dấu gạch chéo bổ sung là cần thiết để mã nguồn được biên dịch. Tuy nhiên, khi mã nguồn đọc trực tiếp từ bàn điều khiển, dấu gạch chéo bổ sung không cần thiết.
Hình dưới cho thấy việc sử dụng các lớp ký tự đã được xác định trước:
Enter expression: \d
Enter string to search: 9
Found the text "9" starting at index 0 and ending at index 1.
Press 'x' to exit or 'y' to continue: y
Enter expression: [\d][\d]
Enter string to search: 10
Found the text "10" starting at index 0 and ending at index 2.Xác định số lần (Quantifiers)
Các dấu xác định số lần (Quantifiers) được sử dụng để chỉ định số lần lặp lại để khớp với chuỗi.
Bảng dưới mô tả các dấu xác định số lần “greedy” (tham lam), “reluctant” (ngần ngại), và “possessive” (sở hữu).
- Dấu x? có ý nghĩa “một hoặc không có lần nào”.
- Dấu x* có ý nghĩa “không có lần nào hoặc nhiều lần”.
- Dấu x+ có ý nghĩa “ít nhất một lần”.
- Dấu x{n} có ý nghĩa “chính xác n lần”.
- Dấu x{n,} có ý nghĩa “ít nhất n lần”.
- Dấu x{n, m} có ý nghĩa “ít nhất n lần và không nhiều hơn m lần”.
Tuy vậy, có sự khác biệt tinh subtile về cách triển khai giữa mỗi dấu xác định số lần này. Dấu ? là quá trình “greedy” (tham lam), tức là nó sẽ cố gắng khớp càng ít lần càng tốt. Dấu * là quá trình “reluctant” (ngần ngại), tức là nó sẽ cố gắng khớp càng ít lần càng tốt, nhưng nó có thể khớp thêm nếu cần. Dấu + là quá trình “possessive” (sở hữu), tức là nó sẽ cố gắng khớp càng nhiều lần càng tốt và không cung cấp sự linh hoạt cho sự khớp.
Tùy thuộc vào yêu cầu cụ thể, bạn có thể sử dụng các dấu xác định số lần này để điều chỉnh cách khớp các chuỗi theo số lần lặp lại mong muốn.
Sử dụng các dấu xác định số lần tham lam (Greedy), ngần ngại (Reluctant), và sở hữu (Possessive) có thể được hiểu thông qua các trường hợp thử nghiệm sau:
Enter expression: b?
Enter string to search: c
Found the text "" starting at index 0 and ending at index 0.
Found the text "" starting at index 1 and ending at index 1.
Press 'x' to exit or 'y' to continue: y
Enter expression: b?
Enter string to search: ghi
Found the text "" starting at index 0 and ending at index 0.
Found the text "" starting at index 1 and ending at index 1.
Found the text "" starting at index 2 and ending at index 2.
Found the text "" starting at index 3 and ending at index 3.
Press 'x' to exit or 'y' to continue: y
Enter expression: b*
Enter string to search:
Found the text "" starting at index 0 and ending at index 0.
Press 'x' to exit or 'y' to continue: y
Enter expression: b+
Enter string to search:
No match found.Enter expression: b{3}
Enter string to search: b
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: b{3}
Enter string to search: bbb
Found the text "bbb" starting at index 0 and ending at index 3.Enter expression: a{3,}
Enter string to search: aa
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: a{3,}
Enter string to search: aaaa
Found the text "aaaa" starting at index 0 and ending at index 4.Enter expression: h{3,5}
Enter string to search: hhhh
Found the text "hhhh" starting at index 0 and ending at index 4.
Press 'x' to exit or 'y' to continue: y
Enter expression: h{3,5}
Enter string to search: hhbhh
No match found.Enter expression: (abc){3}
Enter string to search: abcabc
No match found.
Press 'x' to exit or 'y' to continue: y
Enter expression: (abc){3}
Enter string to search: abcabcabc
Found the text "abcabcabc" starting at index 0 and ending at index 9.Các nhóm ghi lại (capturing groups)
Các nhóm ghi lại (capturing groups) trong biểu thức chính quy cho phép bạn coi nhiều ký tự là một đơn vị duy nhất. Bạn có thể tạo một nhóm ghi lại bằng cách đặt các ký tự cần ghi lại trong cặp dấu ngoặc đơn.
Phương thức groupCount() có thể được sử dụng để xác định có bao nhiêu nhóm ghi lại trong biểu thức chính quy. Nó trả về một giá trị số nguyên chỉ số lượng nhóm ghi lại trong biểu mẫu của matcher. Tuy nhiên, cần lưu ý rằng còn có một nhóm đặc biệt, nhóm 0, đại diện cho toàn bộ biểu thức. Nhóm 0 không được tính trong tổng trả về bởi groupCount(). Ngoài ra, các nhóm bắt đầu bằng ký tự ‘2’ là các nhóm không ghi lại chính, vì chúng không ghi lại văn bản và không tính trong tổng số nhóm.
Hiểu cách các nhóm ghi lại được đánh số là quan trọng vì một số phương thức của Matcher chấp nhận một giá trị số nguyên để xác định một số nhóm cụ thể trong quá trình khớp. Các phương thức này bao gồm start(int group), end(int group), và group(int group), cho phép bạn làm việc với các nhóm ghi lại cụ thể trong quá trình khớp.
Ví dụ:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package com.mycompany;
/**
*
* @author toan1
*/
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class ExampleCapturingGroup {
public static void main(String[] args) {
// Define the regular expression pattern
Pattern pattern = Pattern.compile("(x)(Y)(Z)");
// Input string to match against the pattern
String inputString = "xYZ";
// Create a Matcher to apply the pattern to the input string
Matcher matcher = pattern.matcher(inputString);
// Check for matches
if (matcher.find()) {
// Output the group count
int groupCount = matcher.groupCount();
System.out.println("Group count: " + groupCount);
// Output the content of each group
for (int i = 0; i <= groupCount; i++) {
String groupContent = matcher.group(i);
System.out.println("Group " + i + ": " + groupContent);
}
} else {
System.out.println("No match found.");
}
}
}
Backreferences (tham chiếu ngược)
Backreferences (tham chiếu ngược) là một khái niệm quan trọng trong xử lý biểu thức chính quy. Chúng cho phép bạn sử dụng lại một phần của chuỗi đã khớp bởi một nhóm ghi lại (capturing group) trong biểu thức chính quy.
Các phần của chuỗi đầu vào khớp với các nhóm ghi lại được lưu trong bộ nhớ để có thể gọi lại sau này bằng sự hỗ trợ của backreference (tài liệu tham khảo ngược). Một backreference được chỉ định trong biểu thức chính quy bằng cách sử dụng dấu gạch chéo () theo sau là một số chỉ số nhóm cần gọi lại. Ví dụ, biểu thức (\d\d) xác định một nhóm ghi lại khớp với hai chữ số liên tiếp, sau này có thể được gọi lại trong biểu thức bằng cách sử dụng backreference.
Ví dụ:
Enter expression: (\d\d)\1
Enter string to search: 121213
Found the text "1212" starting at index 0 and ending at index 4.So khớp ranh giới (Boundary matchers )
Boundary matchers trong Java được sử dụng để xác định vị trí xuất hiện của một biểu thức chính quy trong văn bản đầu vào. Chúng giúp định rõ vị trí mà sự khớp nên bắt đầu hoặc kết thúc, tạo điều kiện cụ thể cho sự khớp. Dưới đây là một số boundary matchers thông dụng:
- ^: Đây là boundary matcher bắt đầu dòng. Nó khớp với chuỗi chỉ khi biểu thức chính quy nằm ở đầu dòng.
- $: Boundary matcher cuối dòng. Nó khớp với chuỗi chỉ khi biểu thức chính quy nằm ở cuối dòng.
- \b: Boundary matcher từ (word boundary). Nó khớp với chuỗi chỉ khi biểu thức chính quy xuất hiện tại ranh giới từ, nghĩa là nó bắt đầu hoặc kết thúc tại một giới hạn từ.
- \B: Boundary matcher không phải từ (non-word boundary). Nó khớp với chuỗi chỉ khi biểu thức chính quy xuất hiện tại một giới hạn không phải từ, nghĩa là nó không bắt đầu hoặc kết thúc tại một giới hạn từ.
- \A: Boundary matcher đầu vào (start of input). Nó khớp với chuỗi chỉ khi biểu thức chính quy xuất hiện ở đầu của đầu vào.
- \Z: Boundary matcher cuối đầu vào (end of input excluding final terminator, if any). Nó khớp với chuỗi chỉ khi biểu thức chính quy xuất hiện ở cuối của đầu vào, ngoại trừ terminator cuối cùng nếu có.
- \z: Boundary matcher cuối đầu vào (end of input). Nó khớp với chuỗi chỉ khi biểu thức chính quy xuất hiện ở cuối của đầu vào.
Dưới đây là một số ví dụ minh họa:
import java.util.regex.*;
public class BoundaryMatchersExample {
public static void main(String[] args) {
String text = "Hello, this is a sample text.";
String regex1 = "^Hello"; // Match "Hello" at the beginning of the string
String regex2 = "text.$"; // Match "text." at the end of the string
Pattern pattern1 = Pattern.compile(regex1);
Pattern pattern2 = Pattern.compile(regex2);
Matcher matcher1 = pattern1.matcher(text);
Matcher matcher2 = pattern2.matcher(text);
if (matcher1.find()) {
System.out.println("Match found for regex1.");
}
if (matcher2.find()) {
System.out.println("Match found for regex2.");
}
}
}Kết quả:
Match found for regex1.
Match found for regex2.Trong ví dụ này, chúng ta sử dụng boundary matchers ^ và $ để xác định xem “Hello” và “text.” có xuất hiện ở đầu và cuối chuỗi hoặc không.
Các phương thức bổ sung của lớp pattern
Tạo Pattern với flags (cờ)
Lớp Pattern trong Java cung cấp các phương thức bổ sung cho nhu cầu tìm kiếm mẫu nâng cao và cụ thể hơn. Các phương thức này cho phép bạn tạo các mẫu với các tùy chọn (flags) khác nhau ảnh hưởng đến cách mẫu được tìm kiếm. Dưới đây là giải thích về một số tùy chọn và phương thức mà lớp Pattern cung cấp:
- Pattern.compile(String regex, int flags): Phương thức này được sử dụng để biên dịch một mẫu biểu thức chính quy với các tùy chọn cụ thể. Tham số flags là một bit mask có thể bao gồm một hoặc nhiều trong các hằng số tùy chọn sau:
- Pattern.CANON_EQ: Cho phép tương đương về chuẩn, khớp hai ký tự nếu và chỉ nếu dãy phân giải chuẩn đầy đủ của họ khớp.
- Pattern.CASE_INSENSITIVE: Cho phép khớp không phân biệt kiểu chữ.
- Pattern.COMMENTS: Cho phép ghi chú và khoảng trắng trong mẫu.
- Pattern.DOTALL: Kích hoạt chế độ Dotall, trong đó dấu chấm . khớp với bất kỳ ký tự nào, bao gồm ký tự kết thúc dòng.
- Pattern.LITERAL: Xem chuỗi mẫu đầu vào là một chuỗi các ký tự bình thường, bỏ qua các ký tự đặc biệt hoặc chuỗi escape.
- Pattern.MULTILINE: Kích hoạt chế độ đa dòng, trong đó ^ và $ khớp với đầu hoặc cuối của mỗi dòng.
- Pattern.UNICODE_CASE: Kích hoạt việc xử lý không phân biệt kiểu chữ theo tiêu chuẩn Unicode.
- Pattern.UNIX_LINES: Kích hoạt chế độ dòng Unix, nơi chỉ nhận diện ký tự kết thúc dòng ‘\n’.
Các tùy chọn này cung cấp sự kiểm soát chi tiết về cách các biểu thức chính quy khớp trong các tình huống khác nhau. Bạn có thể sử dụng các tùy chọn này cùng với phương thức Pattern.compile để tạo các mẫu khớp với yêu cầu cụ thể của bạn.
Dưới đây là một ví dụ về việc tạo một mẫu với các tùy chọn:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package com.mycompany;
/**
*
* @author toan1
*/
import java.util.regex.*;
public class ExampleEmbedFlag {
public static void main(String[] args) {
String text = "xin chao, day la mot vi du mau.";
String regex = "(?i)mau"; // Khớp không phân biệt kiểu chữ
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println("Tim thay so khop: " + matcher.group());
}
}
}Trong ví dụ này, (?i) được sử dụng để bật khớp không phân biệt kiểu chữ cho mẫu. Kết quả là nó khớp với “Mẫu” bất kể kiểu chữ trong văn bản đầu vào.
Ví dụ 2:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package com.mycompany;
/**
*
* @author toan1
*/
import java.util.regex.Pattern;
import java.util.regex.Matcher;
import java.util.Scanner;
public class ExampleEmbedFlag2 {
public static void main(String[] args) {
System.out.print("Enter expression: ");
Scanner scanner = new Scanner(System.in);
String expression = scanner.next();
Pattern pattern = Pattern.compile(expression, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher("xYZ");
System.out.printf("Group count is: %d\n", matcher.groupCount());
}
}
Chế độ/cờ biểu thức (Embedded Flag Expressions)
Chế độ biểu thức (Embedded Flag Expressions) cũng có thể được sử dụng để kích hoạt các chế độ khác nhau. Đây là một cách thay thế cho phiên bản hai tham số của phương thức compile(). Các biểu thức cờ này được chỉ định trực tiếp trong biểu thức chính quy.
Các biểu thức cờ nhúng được sử dụng bằng cách thêm các ký tự sau khi biểu thức chính quy. Dưới đây là một số ví dụ:
- (?i): Kích hoạt khớp không phân biệt kiểu chữ (CASE_INSENSITIVE). Ví dụ: “(?i)hello” sẽ khớp “hello”, bất kể kiểu chữ.
- (?s): Kích hoạt chế độ Dotall (DOTALL). Dấu chấm . sẽ khớp với bất kỳ ký tự nào, bao gồm cả ký tự kết thúc dòng. Ví dụ: “(?s)abc.def” sẽ khớp với “abc\ndef”.
- (?m): Kích hoạt chế độ đa dòng (MULTILINE). Khi kích hoạt, ^ và $ sẽ khớp với đầu hoặc cuối của mỗi dòng. Ví dụ: “(?m)^start” sẽ khớp “start” nếu nó xuất hiện ở đầu dòng.
- (?d): Kích hoạt chế độ dòng Unix (UNIX_LINES). Chỉ nhận dạng ký tự kết thúc dòng ‘\n’. Ví dụ: “(?d)line1\nline2” sẽ khớp “line1” và “line2” dựa trên ký tự ‘\n’.
Với việc sử dụng các biểu thức cờ nhúng, bạn có thể linh hoạt thiết lập các tùy chọn khớp trong các biểu thức chính quy mà bạn đang xử lý. Điều này giúp tăng sức mạnh và đa dạng hóa cách bạn khớp văn bản theo yêu cầu cụ thể của mình.
import java.util.regex.*;
public class EmbeddedFlagExpressionsExample {
public static void main(String[] args) {
String text = "This is a Sample Text with Case-Insensitive and Multiline Matching.\nThis is a second line.";
// Regular expression pattern with embedded flags
String regex = "(?i)(?m)sample.*second";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
System.out.println("Match found: " + matcher.group());
} else {
System.out.println("No match found.");
}
}
}
Phương thức matches(String, CharSequence)
Lớp Pattern định nghĩa phương thức matches(), cho phép người lập trình nhanh chóng kiểm tra xem một biểu thức chính quy có xuất hiện trong một chuỗi đầu vào hay không. Tương tự như tất cả các phương thức tĩnh, phương thức matches() được gọi thông qua tên lớp của nó, tức là, Pattern.matches(“\d”,”1″) . Trong trường hợp này, phương thức sẽ trả về true, vì chữ số 1 khớp với biểu thức chính quy “\d”.
public class MatchesExample {
public static void main(String[] args) {
String text = "Hello, World!";
String regex = "Hello, World!";
boolean isMatch = text.matches(regex);
if (isMatch) {
System.out.println("The text matches the regex.");
} else {
System.out.println("The text does not match the regex.");
}
}
}
Phương thức Split()
Ví dụ:
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class SplitTest {
private static final String REGEX = ":"; // Regular expression for splitting
public static void main(String[] args) {
String DAYS = "Sun:Mon:Tue:Wed:Thu:Fri:Sat";
Pattern objPattern = Pattern.compile(REGEX); // Compile the regular expression
String[] days = objPattern.split(DAYS); // Split the string
for (String s : days) {
System.out.println(s);
}
}
}
Phương thức quote()
Trong Java, lớp Pattern có phương thức quote() để tạo một biểu thức chính quy từ một chuỗi, đảm bảo rằng chuỗi đó sẽ được xem xét như một chuỗi tĩnh và không được hiểu là một biểu thức chính quy. Điều này làm cho các ký tự đặc biệt trong chuỗi đó sẽ được trích dẫn và không được hiểu theo cách của biểu thức chính quy. Dưới đây là một ví dụ về cách sử dụng phương thức quote():
import java.util.regex.*;
public class PatternQuoteExample {
public static void main(String[] args) {
String input = "The regex pattern is: [abc]+";
// Sử dụng phương thức quote() để tạo biểu thức chính quy từ chuỗi
String searchString = Pattern.quote("[abc]+");
Pattern pattern = Pattern.compile(searchString);
Matcher matcher = pattern.matcher(input);
while (matcher.find()) {
System.out.println("Match: " + matcher.group());
}
}
}Trong ví dụ này, chúng ta sử dụng phương thức quote(“[abc]+”) để tạo một biểu thức chính quy từ chuỗi “[abc]+”. Biểu thức này sau khi trích dẫn sẽ trở thành “\\[abc\\]\\+”. Sau đó, chúng ta sử dụng biểu thức chính quy này để tìm kiếm chuỗi con trong chuỗi đầu vào input mà có giá trị chính xác là “[abc]+”.
Kết quả của chương trình sẽ là:
Match: [abc]+Phương thức quote() hữu ích khi bạn muốn tìm kiếm một chuỗi cố định trong một chuỗi đầu vào và không muốn xử lý nó như một biểu thức chính quy với các ký tự đặc biệt.
Bài tập
Bài tập 1
Hãy build 1 pattern theo yêu cầu sau:
1. Bắt đầu bằng 1-3 ký tự S
2. Tiếp theo là tối thiểu 3 cụm ký tự com
3. Tiếp theo là 0 hoặc 1 ký tự %
4. Cuối cùng là 2 cụm (@#$)
Bài tập 2
Hãy build 1 pattern theo yêu cầu sau:
1. Bắt đầu là 0 hoặc +84
2. Tiếp theo là 9 ký tự số
Bài tập 3
Hãy build 1 pattern theo mẫu sau:
(local)number
Trong đó:
local có từ 2-4 số bắt đầu từ 0
number có từ 5-7 số.
Bài tập 4
Hãy build 1 pattern theo yêu cầu sau:
Mẫu phải tương ứng với một chuỗi bất kỳ chứa a hoặc b nhưng không được chứa ab.




