
Stream API trong Java
Stream API là một trong những tính năng đáng chú ý trong Java 8 và các phiên bản sau đó, ngoài việc sử dụng biểu thức lambda. Stream API mới cho phép xử lý song song trong Java. Nó hỗ trợ nhiều thao tác tuần tự và song song để xử lý dữ liệu, đồng thời hoàn toàn trừu tượng hóa các quá trình đa luồng cấp thấp.
Các Stream có thể giúp biểu thị các truy vấn và biến đổi dữ liệu hiệu quả giống như SQL và có thể sử dụng biểu thức lambda, do đó tạo ra mã nguồn gọn gàng hơn.
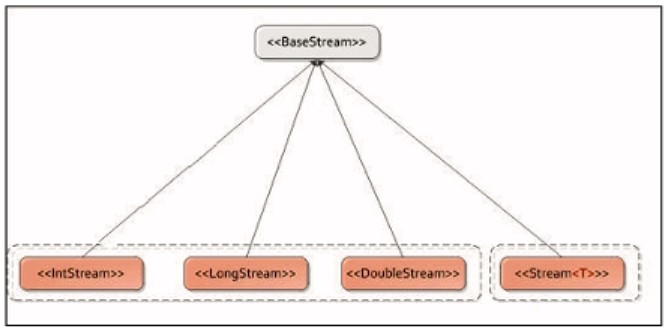
Gói java.util.stream chứa tất cả các giao diện và lớp API Stream. Giao diện Stream và lớp Collectors tạo nền tảng của Stream API. Các thao tác với kiểu dữ liệu nguyên thủy trong các bộ sưu tập là tốn thời gian. Để tránh độ trễ này, có các lớp mới trong API. Một số giao diện trong API bao gồm intStream, LongStream và DoubleStream.
Mục lục
Collections và streams
Một cách đơn giản, Stream là một chuỗi hoặc tập hợp các phần tử hỗ trợ các thao tác tổng hợp tuần tự và song song như lọc, sắp xếp, và nhiều thao tác khác.
Collection là một tập hợp dữ liệu, ở dạng các đối tượng hoặc phần tử. Các phần tử dữ liệu này cũng có thể được lọc, sắp xếp và thực hiện các thao tác tương tự như các phần tử Stream. Tuy nhiên chúng có sự khác biệt, bảng dưới mô tả sự khác biệt giữa chúng:
| Streams (luồng) | Collections (bộ sưu tập) |
| Streams là cấu trúc dữ liệu cố định và được tính toán khi cần thiết | Bộ sưu tập là một cấu trúc dữ liệu trong bộ nhớ để lưu trữ giá trị và điều này là bắt buộc phải có tất cả các giá trị được tạo ra trước khi người dùng truy cập. |
| Streams là cấu trúc dữ liệu được triển khai một cách lười biếng (lazyly); một stream hoạt động dựa trên yêu cầu của người dùng | Tính chất của các bộ sưu tập là hoàn toàn trái ngược với các luồng và chúng là một tập hợp các giá trị được tính toán một cách hoạt động (bất kể yêu cầu của người dùng). |
| Streams tập trung vào các tác vụ tổng hợp và tính toán. | Các bộ sưu tập chỉ tập trung vào việc lưu trữ dữ liệu. |
Stream không có lưu trữ dữ liệu; nó hoạt động trên cấu trúc dữ liệu nguồn (tập hợp và mảng) và trả về dữ liệu tuần tự hoặc các phần tử dữ liệu theo chuỗi mà bạn có thể thực hiện các hoạt động tiếp theo. Ví dụ, bạn có thể tạo một Stream từ một danh sách và thực hiện việc lọc dựa trên điều kiện. | Ngược lại, các bộ sưu tập là cấu trúc dữ liệu thực sự chứa hoặc giữ dữ liệu trong bộ nhớ. |
| Stream được dựa trên việc sắp xếp theo cấp dẫn (pipelining), hình thành thông qua nguồn dữ liệu và các phép toán trung gian và kết thúc thực hiện trên dữ liệu. | Các bộ sưu tập có thể không hỗ trợ việc sắp xếp theo cấp dẫn (pipelining). |
| Các hoạt động của Stream không lặp qua một cách tường tận, quá trình lặp diễn ra bên trong. | Các bộ sưu tập được lặp qua một cách rõ ràng. |
| Các hoạt động của Stream thân thiện với các giao diện hàm; điều này cho phép lập trình hàm bằng cách sử dụng biểu thức lambda. Tuy nhiên, điều này cũng có thể làm cho quá trình xử lý chậm hơn. | Xử lý dữ liệu trong bộ sưu tập nhanh hơn trong hầu hết các trường hợp so với Stream. |
Tạo luồng (Generate Stream)
Có nhiều tùy chọn có sẵn để tạo ra một Stream trong Java. Một trong những cách này là tạo một Stream từ một nguồn dữ liệu như một lớp hoặc giao diện kế thừa từ java.util.Collection. Giao diện Collection cung cấp các phương thức stream() và parallelStream(), được kế thừa bởi tất cả các lớp thực hiện và các lớp con giao diện.
Các phương thức này được mô tả ngắn gọn như sau:
- stream(): Được sử dụng để có một Stream tuần tự với bộ sưu tập làm nguồn dữ liệu của nó.
Đoạn code dưới mô tả cách sử dụng stream():
import java.util.List;
import java.util.stream.Stream;
import java.util.Arrays;
import java.util.List;
public class StreamCreationExample {
public static void main(String[] args) {
// Create a List of Strings
List<String> stringList = Arrays.asList("Apple", "Banana", "Cherry", "Date", "Fig");
// Convert the List to a Stream
Stream<String> stream = stringList.stream();
// Perform operations on the Stream
stream
.filter(s -> s.startsWith("B")) // Filter strings that start with 'B'
.map(String::toUpperCase) // Convert to uppercase
.forEach(System.out::println); // Print each element
// You can only consume a Stream once, so if you need to use it again, recreate it.
Stream<String> anotherStream = stringList.stream();
}
}
- parallelStream(): Được sử dụng để có một Stream có thể là tuần tự hoặc song song dọc theo bộ sưu tập làm nguồn dữ liệu của nó.
Đoạn code dưới mô tả cách sử dụng parallelStream():
import java.util.Arrays;
import java.util.List;
public class ParallelStreamExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// Create a parallel stream
long sum = numbers.parallelStream()
.mapToInt(Integer::intValue)
.sum();
System.out.println("Sum of numbers using parallelStream: " + sum);
}
}
Một số cách khác để tạo ra một Stream bao gồm việc sử dụng các phương thức tạo Stream tĩnh trên các lớp và giao diện Stream, chẳng hạn như Stream.of(), IntStream.range(), BufferedReader.lines() và Random.ints().
Xét ví dụ phía dưới:
Lớp BufferedReader của gói java.io bao gồm phương thức lines() trả về một Stream, như được thể hiện trong Đoạn mã:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class BufferedReaderDemo {
public static void main(String[] args) throws FileNotFoundException, IOException {
FileReader sampleFR = new FileReader("D://files/file.txt");
BufferedReader sampleBR = new BufferedReader(sampleFR);
String line;
while ((line = sampleBR.readLine()) != null) {
System.out.println(line);
}
sampleBR.close(); // Close the BufferedReader when you're done
}
}
Ở đây, SampleBR được tạo dưới dạng một thể hiện của lớp BufferedReader sử dụng phương thức lines() cho một hoạt động luồng đơn giản – đọc và hiển thị dữ liệu từ một tệp văn bản.
Để đọc một tệp dưới dạng một đối tượng java.util.stream.Stream bằng cách sử dụng Files.lines(Path filePath), mã sẽ như được thể hiện trong Đoạn mã dưới. Lớp Files thuộc gói java.nio.file.Files.
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.stream.Stream;
public class BufferedReaderDemo2 {
public static void main(String[] args) throws IOException {
try (Stream<String> sampleST = Files.lines(Paths.get("D:/files/file.txt"))) {
sampleST.forEach(System.out::println);
}
}
}
Ở đây, sampleST là một thể hiện của Stream. Phương thức lines() được áp dụng để lấy dữ liệu từ một đường dẫn tệp đã cho. Như bạn có thể thấy, đây là một triển khai lười biếng (lazy implementation). Do đó, nó có thể không đọc toàn bộ tệp khi được gọi.
Các phương thức tĩnh trên lớp Files giúp duyệt cây tệp bằng cách sử dụng một Stream. Một số trong số chúng được liệt kê trong bảng dưới:
| Phương thức | Giải thích |
| static Stream<Path> list(Path dir) | Phương thức này thu thập một Stream chứa các đối tượng Path, biểu thị tất cả các tệp và thư mục trong thư mục cụ thể. |
| Stream<Path> walk(Path dir, FileVisitOption.., options) | Phương thức này thu thập một Stream được tạo bằng cách duyệt cây tệp bắt đầu từ một tệp cụ thể. FileVisitOption là một enumeration định nghĩa các tùy chọn duyệt cây tệp. |
| static Stream<Path> walk(Path dir, int maxDepth, FileVisitOption… options) | Phương thức này thu thập một Stream được tạo bằng cách duyệt cây tệp theo chiều sâu bắt đầu từ một tệp cụ thể. |
Bạn có thể sử dụng lớp Pattern để tạo một Stream từ các mẫu văn bản bằng cách sử dụng phương thức splitAsStream(CharSequence). Phương thức này tạo ra một Stream từ các mẫu tách (pattern). Ví dụ dưới đây mô tả cách sử dụng phương thức splitAsStream() để tạo ra một Stream:
import java.util.regex.Pattern;
import java.util.stream.Stream;
public class SplitAsStreamExample {
public static void main(String[] args) {
String text = "This is a sample text for splitAsStream example";
// Split the CharSequence into words and create a stream of words
Stream<String> wordStream = Pattern.compile("\\s+")
.splitAsStream(text);
wordStream.forEach(System.out::println);
}
}
Luồng vô hạn (Infinitive Stream)
Luồng vô hạn là một chuỗi hoặc bộ sưu tập các phần tử không giới hạn.
Luồng vô hạn có thể được tạo bằng cách sử dụng các phương thức tĩnh generate() hoặc iterate() trên lớp Stream. Ví dụ, bạn có thể tạo một lượng vô hạn đối tượng với phương thức generate(). Ví dụ:
import java.util.stream.Stream;
/**
*
* @author toan1
*/
public class ExampleInfinitiveStream {
public static void main(String[] args) {
Stream.generate(() -> "*").forEach(System.out::println);
}
}
Phương thức iterate() tương tự như generate() với sự khác biệt là nó nhận giá trị ban đầu và một hàm sẽ thay đổi giá trị đó. Ví dụ, một dãy số nguyên có thể được duyệt qua như ví dụ:
import java.util.stream.Stream;
/**
*
* @author toan1
*/
public class ExampleInfinitiveStream {
public static void main(String[] args) {
Stream.iterate(2, m -> m + 2) // iterating stream
.forEach(System.out::println); // result
}
}
Ở đây, phương thức iterate() được áp dụng và giá trị ban đầu là 2 được lặp lại bằng hàm cộng thêm cho đến khi chương trình dừng lại. Mã này tạo ra đầu ra ‘2468 10 12 14 …’ vô tận (cho đến khi chương trình bị dừng đột ngột).
Dãy luồng (Stream Range)
Phương pháp này cho phép tạo ra các khoảng số như là các luồng.
Luồng cơ bản mới được gọi là IntStream có thể được sử dụng để tính toán dãy luồng. Code mẫu dưới mô tả cách sử dụng phương thức tĩnh range() trên giao diện IntStream.
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
import java.util.stream.IntStream;
/**
*
* @author toan1
*/
public class StreamRangeExamle {
public static void main(String[] args) {
IntStream.range(2, 18).forEach(System.out::println);
}
}
Ở đây, phương thức tĩnh range() tạo ra các số nằm giữa các giá trị đã cho trong thao tác luồng. Đoạn mã này tạo ra các số từ 2 đến 18.
Tất cả các giao diện Stream cơ bản như IntStream, DoubleStream và LongStream đều chứa các phương thức tương ứng để tạo các dãy số.
Hoạt động trên luồng
Trên luồng dữ liệu, các hoạt động được phân chia thành hai loại chính: hoạt động trung gian và hoạt động cuối cùng.
- Hoạt động trung gian (Intermediate Operations): Đây là các hoạt động được thực hiện trên luồng và trả về một luồng mới. Các hoạt động trung gian thường làm việc với dữ liệu trong luồng, ví dụ như lọc (filter), ánh xạ (map), sắp xếp (sort), v.v. Các hoạt động này thực hiện trừu tượng và lười biếng, tức là chúng không thực sự thực hiện diện cho đến khi có một hoạt động cuối cùng kích hoạt.
- Hoạt động cuối cùng (Terminal Operations): Đây là các hoạt động cuối cùng trong luồng, và chúng kích hoạt toàn bộ luồng để thực hiện các tính toán. Các hoạt động cuối cùng thường tạo kết quả hoặc thực hiện một hành động cuối cùng trên dữ liệu trong luồng. Các hoạt động cuối cùng bao gồm hành động như
forEach,collect,reduce,toArray, v.v.
Việc phân chia hoạt động trung gian và hoạt động cuối cùng là một phần quan trọng của việc làm việc với luồng dữ liệu trong Java, và nó giúp tối ưu hóa xử lý dữ liệu theo cách hiệu quả.
Hoạt động trung gian (Intermediate Operations)
Trong các hoạt động trung gian, các toán tử (hoạt động trung gian) áp dụng logic, do đó, Luồng đầu vào tạo ra một Luồng khác. Một Luồng có thể chứa ‘n’ số hoạt động trung gian, không giới hạn cố định.
Những toán tử này có thể thực hiện nhiều hoạt động như lọc, ánh xạ và nhiều hoạt động khác. Các hoạt động trung gian có tính chất “lười biếng”, điều này có nghĩa là chúng không thực hiện ngay lập tức; thay vào đó, chúng tạo ra các phần tử Luồng mới và gửi chúng đến hoạt động tiếp theo. Các phần tử Luồng mới này chỉ được xử lý khi một hoạt động cuối cùng được gặp phải.
Cách tiếp cận đánh giá lười biếng này cho phép thực hiện hiệu quả hơn và linh hoạt hơn trong việc xử lý dữ liệu, vì nó tránh các tính toán không cần thiết cho đến khi kết quả cuối cùng thực sự cần thiết. Đây là một khái niệm cơ bản trong việc làm việc với Luồng trong Java.
Hoạt động cuối cùng (Terminal Operations)
Các toán tử trung gian có thể khởi đầu một dãy luồng các phần tử, tuy nhiên, để thực thi quá trình tiếp theo, cần phải có các toán tử cuối cùng trong luồng. Một toán tử cuối cùng có thể được tìm thấy ở cuối ngăn xếp cuộc gọi và thực hiện thao tác cuối cùng để tiêu thụ Luồng, đó chính là hoạt động cuối cùng. Những hoạt động này trả về một kết quả hoặc tạo ra một hiệu ứng phụ.
Dưới đây là một số phương thức cuối cùng (final method) phổ biến:
- forEach: Lặp qua từng phần tử trong Luồng và thực hiện một thao tác cụ thể.
- toArray: Chuyển đổi Luồng thành một mảng.
- min: Tìm giá trị nhỏ nhất trong Luồng.
- max: Tìm giá trị lớn nhất trong Luồng.
- findFirst: Tìm phần tử đầu tiên trong Luồng.
- findAny: Tìm bất kỳ phần tử nào trong Luồng.
- anyMatch: Kiểm tra xem có ít nhất một phần tử thỏa mãn một điều kiện cho trước hay không.
- allMatch: Kiểm tra xem tất cả các phần tử có thỏa mãn một điều kiện cho trước hay không.
- noneMatch: Kiểm tra xem không có phần tử nào thỏa mãn một điều kiện cho trước hay không.
Ví dụ, distinct() là một hoạt động trung gian. Nó trả về một luồng chứa các phần tử duy nhất từ luồng đã được chỉ định. Tuy nhiên, việc duyệt bắt đầu chỉ khi thực hiện một vòng lặp forEach() hoặc một hoạt động cuối cùng tương tự.
Ví dụ:
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
Stream.of("the", "cat", "sat", "on", "the", "mat", "on", "the", "floor")
.distinct()
.forEach(w -> System.out.println("Printing: " + w));
}
}
Hoạt động cắt ngắn (Short-circuiting Operations)
Các hoạt động cắt ngắn không phải là các hoạt động độc lập như các hoạt động trung gian hoặc hoạt động kết thúc. Nếu một hoạt động (trung gian hoặc kết thúc) tạo ra một Stream hữu hạn trong một Stream vô hạn, thì nó được gọi là hoạt động cắt ngắn. limit() và skip() là các hoạt động trung gian cắt ngắn.
Nếu hoạt động kết thúc kết thúc trong thời gian giới hạn trong một Stream vô hạn, thì nó được gọi là hoạt động kết thúc ngắn. Ví dụ, anyMatch, noneMatch, allMatch, findFirst và findAny là các hoạt động kết thúc cắt ngắn.
Map/Filter/Reduce với Streams
Các phương thức Map/Filter/Reduce có thể được thực hiện trong biểu thức lambda và các phương thức mặc định. Tuy nhiên, thư viện chuẩn Java đã triển khai sẵn các phương thức này. Bây giờ bạn sẽ thấy từng phương thức này một.
Map:
Phương thức này được áp dụng để ánh xạ tất cả các phần tử thành phần tử đầu ra của chúng.
Filter:
Như tên gọi, phương thức này được áp dụng để chọn một tập hợp các phần tử và loại bỏ các phần tử khác dựa trên các hướng dẫn cụ thể.
Reduce:
Phương thức này được áp dụng để giảm các phần tử dựa trên các hướng dẫn cụ thể.
Java hỗ trợ nhiều phương thức kết thúc bao gồm trung bình, max, sum, và như vậy, trả về một giá trị bằng cách kết hợp nội dung của một luồng. Các hoạt động như vậy được gọi là hoạt động thu gọn.
Ví dụ:
String output = scores.stream().reduce((acc,score) -> acc + " " + score)Ở đây, một tập hợp các điểm số được thu gọn thành một giá trị duy nhất.
Xét một ví dụ phức tạp hơn, trong đó bạn cần tìm một thành viên có điểm số dẫn đầu cao nhất trong một đội thể thao:
Tạo class MemberPoints:
package streamAPI;
class MemberPoints {
private String memberName;
private double points;
public MemberPoints(String memberName, double points) {
this.memberName = memberName;
this.points = points;
}
public double getPoints() {
return points;
}
@Override
public String toString() {
return "MemberPoints{" +
"memberName='" + memberName + '\'' +
", points=" + points +
'}';
}
}Tạo class ExampleMapReduce:
package streamAPI;
import java.util.List;
public class ExampleMapReduce {
public static void main(String[] args) {
List<String> names = List.of("Alice", "Bob", "Charlie", "David"); // Replace with your list of member names
MemberPoints highestMemberPoints = names.stream()
.map(memberName -> new MemberPoints(memberName, getPoints(memberName)))
.reduce(new MemberPoints("", 0.0), (mp1, mp2) -> mp1.getPoints() > mp2.getPoints() ? mp1 : mp2);
System.out.println("Member with the highest points: " + highestMemberPoints);
}
// Replace this method with your logic to get points for a member
public static double getPoints(String memberName) {
// You should implement the logic to retrieve points for a member here
// For the example, I'm returning a random value
return Math.random() * 100;
}
}
Streams và ParallelArray
Lớp Array trong Java chứa nhiều chức năng cho các hoạt động mảng khác nhau như sắp xếp. Stream API mới được giới thiệu (và thư viện Java được cập nhật) cho phép tất cả các hoạt động mảng thông qua các mảng song song. Ví dụ, parallelSort(). Đoạn code dưới cho thấy cách sử dụng một cách đơn giản của phương pháp song song.
import java.util.Arrays;
public class ParallelSortExample {
public static void main(String[] args) {
int[] sampleArray = {8, 3, 1, 7, 4, 5, 9, 2, 6};
// Sort the array in parallel
Arrays.parallelSort(sampleArray);
// Print the sorted array
System.out.println("Sorted array:");
for (int num : sampleArray) {
System.out.print(num + " ");
}
}
}
Phương thức limit
Phương thức limit() có thể được áp dụng để giới hạn một Stream cho một số lượng phần tử cụ thể. Phương pháp này được khuyến nghị tốt nhất cho các stream pipeline tuần tự.
Ví dụ, limit(12) có thể được áp dụng để giới hạn các số dưới 12:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.util.Random;
public class StreamLimitExample {
public static void main(String[] args) {
Random sampleRand = new Random();
sampleRand.ints().limit(12).forEach(System.out::println);
}
}
Ở đây, sampleRand() được sử dụng để trả về các giá trị số nguyên ngẫu nhiên và phương thức limit() được áp dụng để giới hạn số lượng giá trị hiển thị. Trong trường hợp này, mã giới hạn việc hiển thị chỉ 12 số ngẫu nhiên.
Phương thức sort
Ngoài việc hỗ trợ những hoạt động này, Stream API cũng chứa một phương thức khác để sắp xếp Stream, đó là phương thức sorted(). Phương thức này tương tự các phương thức trung gian khác trên Stream như map, filter, và peek.
Đặc điểm quan trọng của phương thức sorted() là việc thực hiện là “lười biếng” (lazy execution). Không có quá trình nào bắt đầu cho đến khi một phép toán kết thúc (như reduce hoặc forEach) được gọi. Một phép giới hạn phải được gọi trước phép sắp xếp trên một Stream vô hạn. Ví dụ:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.util.Random;
public class ExampleStreamSort {
public static void main(String[] args) {
Random sampleRand = new Random();
sampleRand.ints().limit(12).sorted().forEach(System.out::println);
}
}
Ở đây, giá trị trả về được sắp xếp bằng phương thức sorted() và phương thức này nên được đặt sau phép giới hạn (limit) để tạo ra kết quả.
Hơn nữa, sort() có thể được áp dụng sau một phép gọi nối tiếp, ví dụ:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.io.IOException;
import java.nio.file.FileVisitOption;
import java.nio.file.FileVisitResult;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.stream.Stream;
public class ExampleStreamSort2 {
public static void main(String[] args) throws IOException {
Files.list(Paths.get("D:/files/"))
.map(Path::getFileName) // Get file names
.map(Path::toString) // Convert to String
.filter(name -> name.endsWith("jpg"))
.sorted()
.limit(6)
.forEach(System.out::println);
}
}
Ở đây, đoạn mã thể hiện tuần tự các tác vụ sau:
- Liệt kê các tệp trong thư mục/cơ sở dữ liệu cụ thể.
- Ánh xạ các tệp thành tên tệp.
- Lọc ra các tên tệp kết thúc bằng “jpeg”.
- Chọn chỉ 6 tên đầu tiên (đã được sắp xếp theo thứ tự chữ cái).
- Hiển thị kết quả ra màn hình.
Như vậy, đoạn mã này giúp bạn tìm và hiển thị tên của 6 tệp JPEG đầu tiên trong thư mục cụ thể.
Collectors
Trong một bộ thu thập, có ba thành phần khác nhau như sau:
Đầu tiên, một nguồn cung cấp giá trị ban đầu.
Thứ hai, một bộ tích lũy thêm vào giá trị ban đầu.
Thứ ba, một bộ kết hợp kết hợp hai giá trị đầu ra thành một giá trị đầu ra duy nhất. Có hai cách để thực hiện điều này:
collect(supplier, accumulator, combiner)
collect(Collector)Có nhiều bộ thu thập mặc định sẵn có. Lệnh để nhập gói collectors được hiển thị trong Đoạn mã:
import static java.util.stream.Collectors.*;Bạn có thể sử dụng các bộ thu thập này để thực hiện các thao tác gom nhóm, sắp xếp, lọc và nhiều thao tác khác trên các phần tử của luồng.
Simple Collectors
Đoạn mã dưới hiển thị một ví dụ hoàn chỉnh sử dụng bộ thu thập đơn giản. Hãy tưởng tượng rằng bạn có một danh sách tên các bộ phim và năm phát hành của chúng và bạn muốn hiển thị chỉ tên từ danh sách này. Điều này có thể được thực hiện bằng cách sử dụng một bộ thu thập.
Ví dụ:
Tạo class Movie
package streamAPI;
class Movie {
String name;
int year;
public Movie(String name, int year) {
super();
this.name = name;
this.year = year;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
}
Tạo class SimpleCollectorDemo
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
*
* @author toan1
*/
public class SimpleCollectorDemo {
public static void main(String[] args) {
// Create a list of movies
List<Movie> listOfMovies = createListOfMovies();
// Use map(), collect(), and toList() to get a list of movie names
List<String> listOfMovieNames = listOfMovies.stream()
.map(s -> s.getName())
.collect(Collectors.toList());
listOfMovieNames.forEach(System.out::println);
}
public static List<Movie> createListOfMovies() {
List<Movie> listOfMovies = new ArrayList<>();
Movie m1 = new Movie("Coma", 1996);
Movie m2 = new Movie("Peter Kong Goes to the Mall", 1975);
Movie m3 = new Movie("Martinzden", 2020);
Movie m4 = new Movie("Clouds of Sils Maria", 2018);
listOfMovies.add(m1);
listOfMovies.add(m2);
listOfMovies.add(m3);
listOfMovies.add(m4);
return listOfMovies;
}
}
Mã định nghĩa một bộ thu thập đơn giản bằng cách sử dụng toList(). Ở đây, map là một phép hoạt động trung gian và tiêu thụ một phần tử từ Luồng đầu vào và tạo ra một phần tử đầu ra trong Luồng.
Joining (Nối)
Bộ thu thập joining tương tự như StringUtil.join. Nó kết hợp các phần tử trong Luồng sử dụng một dấu phân cách được cung cấp.
Mã đoạn dưới xây dựng trên ví dụ trước đó. Ở đây, dấu chấm phẩy ngăn cách các tên được cung cấp và chúng được kết hợp thành một chuỗi duy nhất bằng bộ thu thập joining:
Tạo class Movie
package streamAPI;
class Movie {
String name;
int year;
public Movie(String name, int year) {
super();
this.name = name;
this.year = year;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
}
Tạo class SimpleCollectorDemoJoin
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
*
* @author toan1
*/
public class SimpleCollectorDemoJoin {
public static void main(String[] args) {
// Create a list of movies
List<Movie> listOfMovies = createListOfMovies();
// Use map(), collect(), and joining() to concatenate movie names
String movieNames = listOfMovies.stream()
.map(s -> s.getName())
.collect(Collectors.joining(";"));
System.out.println(movieNames);
}
public static List<Movie> createListOfMovies() {
List<Movie> listOfMovies = new ArrayList<>();
Movie m1 = new Movie("Coma", 1996);
Movie m2 = new Movie("Peter Kong Goes to the Mall", 1975);
Movie m3 = new Movie("Martinzden", 2020);
Movie m4 = new Movie("Clouds of Sils Maria", 2018);
listOfMovies.add(m1);
listOfMovies.add(m2);
listOfMovies.add(m3);
listOfMovies.add(m4);
return listOfMovies;
}
}
Statistics (thống kê)
Những loại bộ thu thập này đánh giá các giá trị được cung cấp và tạo ra một giá trị duy nhất làm đầu ra. Ví dụ, bộ thu thập trung bình tạo ra giá trị trung bình của một tập hợp các giá trị.
Mã dưới tính toán độ dài trung bình của các dòng không trống trong tệp ‘file.txt’:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.stream.Collectors;
public class StatisticsCollectors {
public static void main(String[] args) throws IOException {
System.out.println("Here's the Avg length value:"); // Display result
double averageLength = Files.lines(Paths.get("D:/files/file.txt"))
.map(String::trim)
.filter(p -> !p.isEmpty())
.collect(Collectors.averagingInt(String::length)); // Averaging the lines' length
System.out.println(averageLength);
}
}
Trong một số trường hợp, cần nhiều thống kê trong một bộ sưu tập duy nhất. Thường thì Streams được tiêu thụ khi collect được gọi, nó tính toán nhiều thống kê cùng một lúc. Trong những trường hợp như vậy, nên sử dụng IntSummaryStatistics. Lớp này có thể được nhập bằng cách sử dụng một câu lệnh import đơn giản như trong đoạn mã:
import java.util.IntSummaryStatistics;
Ví dụ:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.util.Arrays;
import java.util.IntSummaryStatistics;
import java.util.List;
public class ExamIntSummaryStatistics {
public static void main(String[] args) {
List<Integer> myInt = Arrays.asList(77, 66, 888, 22, 33, 7, 121, 89, 55);
IntSummaryStatistics examStats = myInt.stream()
.mapToInt(Integer::intValue)
.summaryStatistics();
System.out.println("A list of random numbers: " + myInt);
System.out.println("Highest number in the list: " + examStats.getMax());
System.out.println("Lowest number in the list: " + examStats.getMin());
System.out.println("Combined value of all numbers: " + examStats.getSum());
System.out.println("Average value of all numbers: " + examStats.getAverage());
}
}
Tương tự, một Stream có thể được ánh xạ sang một kiểu nguyên thủy (primitive type) sau đó, summaryStatistics() có thể được gọi như trong đoạn mã:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.IntSummaryStatistics;
public class SummaryStatisticsExample {
public static void main(String[] args) throws IOException {
IntSummaryStatistics sampleStat = Files.lines(Paths.get("D:/files/file.txt"))
.map(String::trim)
.filter(p -> !p.isEmpty())
.mapToInt(String::length)
.summaryStatistics();
System.out.println("Summary Statistics:");
System.out.println("Count: " + sampleStat.getCount());
System.out.println("Sum: " + sampleStat.getSum());
System.out.println("Min: " + sampleStat.getMin());
System.out.println("Max: " + sampleStat.getMax());
System.out.println("Average: " + sampleStat.getAverage());
}
}
Nhóm và phân vùng
Grouping
Bộ thu thập Grouping (groupingBy) nhóm các phần tử dựa trên một hàm cụ thể. Ví dụ, việc nhóm một tập hợp các phần tử theo chữ cái đầu tiên của tên được thể hiện trong đoạn mã:
Tạo class Movie
package streamAPI;
class Movie {
String name;
int year;
public Movie(String name, int year) {
super();
this.name = name;
this.year = year;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
}
Tạo class GroupingCollectorDemo
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class GroupingCollectorDemo {
public static void main(String[] args) {
// Create a list of movies
List<Movie> listOfMovies = createListofMovies();
// Group movies by the first character of their name
Map<Character, List<Movie>> movieMap = listOfMovies.stream()
.collect(Collectors.groupingBy(movie -> movie.getName().charAt(0)));
// Iterate through the results and display the grouped entries
for (Map.Entry<Character, List<Movie>> entry : movieMap.entrySet()) {
Character key = entry.getKey();
List<Movie> valueList = entry.getValue();
System.out.println("\nKey: " + key);
System.out.println("Values: ");
for (Movie movie : valueList) {
System.out.println(movie.getName());
}
}
}
public static List<Movie> createListofMovies() {
List<Movie> listOfMovies = new ArrayList<>();
Movie m1 = new Movie("Coma", 1996);
Movie m2 = new Movie("Peter Kong Goes to the Mall", 1975);
Movie m3 = new Movie("Martin Eden", 2020);
Movie m4 = new Movie("Clouds of Sils Maria", 2018);
listOfMovies.add(m1);
listOfMovies.add(m2);
listOfMovies.add(m3);
listOfMovies.add(m4);
return listOfMovies;
}
}
Partitioning
Phương thức Partitioning (partitioningBy) tương tự phương thức Grouping và tạo một bản đồ với 2 khóa boolean, như được thể hiện trong Đoạn mã:
Tạo class Movie
package streamAPI;
class Movie {
String name;
int year;
public Movie(String name, int year) {
super();
this.name = name;
this.year = year;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
}
Tạo class GroupingCollectorDemo
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class PartitioningCollectorDemo {
public static void main(String[] args) {
List<Movie> listOfMovies = createListofMovies();
// Partition movies into two groups: before and after 2000
Map<Boolean, List<Movie>> movieMap = listOfMovies.stream()
.collect(Collectors.partitioningBy(movie -> movie.getYear() > 2000));
// Iterate through the results and display the partitioned entries
for (Map.Entry<Boolean, List<Movie>> entry : movieMap.entrySet()) {
Boolean key = entry.getKey();
List<Movie> valueList = entry.getValue();
System.out.println("\nKey: " + key);
System.out.println("Values: ");
for (Movie movie : valueList) {
System.out.println(movie.getName());
}
}
}
public static List<Movie> createListofMovies() {
List<Movie> listOfMovies = new ArrayList<>();
Movie m1 = new Movie("Coma", 1996);
Movie m2 = new Movie("Peter Kong Goes to the Mall", 1975);
Movie m3 = new Movie("Martin Eden", 2020);
Movie m4 = new Movie("Clouds of Sils Maria", 2018);
listOfMovies.add(m1);
listOfMovies.add(m2);
listOfMovies.add(m3);
listOfMovies.add(m4);
return listOfMovies;
}
}
Parallel Grouping (groupingByConcurrent) thực hiện việc nhóm theo cách song song (không cần thứ tự). Dòng Stream phải không có thứ tự để cho phép việc nhóm song song.
Sử dụng Giao diện Chức năng với Stream API
Giao diện chức năng có thể được sử dụng với nhiều APls mới trong Java bao gồm Date-Time và Stream. Các giao diện chức năng thường được sử dụng với Stream API như sau:
Function và BiFunction: Function đại diện cho một hàm lấy một loại phần tử và tạo ra một loại phần tử khác.
Function là dạng cơ bản (generic), trong đóT là kiểu dữ liệu đầu vào và R là kiểu dữ liệu đầu ra (kết quả) của hàm. Có các giao diện Function cụ thể sẵn có để xử lý các kiểu dữ liệu nguyên thủy. Mỗi cái này đại diện cho một giao diện chức năng và do đó có thể được sử dụng làm mục tiêu gán trong biểu thức lambda hoặc tham chiếu phương thức.
Một số trong các hàm này (hoặc giao diện chức năng) bao gồm:
- ToIntFunction
- IntBiFunction
- ToLongFunction
- ToLongBiFunction
- LongToIntFunction
- LongToDoubleFunction
- ToDoubleFunction
- ToDoubleBiFunction
- IntToLongFunction
Dưới đây là các phương thức của Stream mà Function hoặc các biến thể cơ bản của nó được áp dụng:
reduce(U identity, BiFunction<? super U, ? super T, U> accumulator, BinaryOperator<U> combiner): Sử dụng BiFunction để tính toán kết quả của việc kết hợp các phần tử trong Stream. Có thể được sử dụng để tính tổng, nhưng cũng áp dụng cho các phép tính khác.map(Function<? super T, ? extends R> mapper): Áp dụng một Function để chuyển đổi từng phần tử của Stream thành một phần tử mới.flatMapToInt(Function<? super T, ? extends IntStream> mapper): Áp dụng một Function để chuyển đổi từng phần tử của Stream thành một IntStream. Tương tự cho các biến thểlongvàdouble.toArray(IntFunction<A[]> generator): Áp dụng IntFunction để chuyển đổi Stream thành một mảng.- IntStream
mapToInt(ToIntFunction<? super T> mapper): Áp dụng một ToIntFunction để chuyển đổi từng phần tử của Stream thành một giá trị nguyên. Tương tự cho các biến thểlongvàdoublecó kiểu dữ liệu nguyên cấp.
Predicate và BiPredicate: Chúng đại diện cho một mệnh đề mà các đối số của Stream được kiểm tra. Chúng được áp dụng để lọc các đối số từ Stream. Tương tự như Function, có các giao diện cụ thể cho int, long và double.
Dưới đây là các phương pháp Stream mà các phương pháp Predicate hoặc BiPredicate được sử dụng:
- boolean noneMatch(Predicate<? super T> predicate) //để lọc ra những phần tử không khớp
- boolean anyMatch(Predicate<? super T> predicate) //để lọc ra bất kỳ phần tử nào khớp
- Stream<T> filter(Predicate<? super T> predicate) //lọc trong Stream
- boolean allMatch(Predicate<? super T> predicate) //để lọc ra tất cả các phần tử khớp
Consumer và BiConsumer: Chúng đại diện cho một hoạt động nhận một phần tử đầu vào và không tạo ra đầu ra. Một số hành động có thể được thực hiện trên tất cả các phần tử của Stream.
Ví dụ:
/*
* Click nbfs://nbhost/SystemFileSystem/Templates/Licenses/license-default.txt to change this license
* Click nbfs://nbhost/SystemFileSystem/Templates/Classes/Class.java to edit this template
*/
package streamAPI;
/**
*
* @author toan1
*/
import java.util.Arrays;
import java.util.List;
import java.util.function.Consumer;
public class ConsumerDemo {
public static void main(String[] args) {
List<Employee> employees = Arrays.asList(
new Employee("John Simmons", 350000),
new Employee("Mark Smith", 413000),
new Employee("Jane Weston", 344000),
new Employee("Gillian Bush", 690000)
);
displayAllEmployees(employees, e -> e.salary *= 1.5);
System.out.println("Salaries after increment:");
displayAllEmployees(employees, e -> System.out.println(e.empname + ":" + e.salary));
}
public static void displayAllEmployees(List<Employee> employees, Consumer<Employee> printer) {
for (Employee e : employees) {
printer.accept(e);
}
}
static class Employee {
public String empname;
public long salary;
public Employee(String name, long sal) {
this.empname = name;
this.salary = sal;
}
}
}
Dưới đây là những phương thức của Stream trong Java mà Consumer, BiConsumer hoặc các giao diện nguyên thủy tương ứng của chúng được sử dụng:
- void forEach(Consumer<? super T> action): Sử dụng để thực hiện một hành động (action) trên từng phần tử trong Stream. Hành động này được định nghĩa bởi
Consumer. - Stream<T> peek(Consumer<? super T> action): Thực hiện một hành động (action) trên từng phần tử trong Stream, giống như
forEach. Phương thức này trả về một Stream mới chứa các phần tử gốc, cho phép bạn thực hiện các hành động gỡ rối (debugging) hoặc theo dõi trạng thái của Stream trong quá trình xử lý. - void forEachOrdered(Consumer<? super T> action): Giống như
forEach, nhưng đảm bảo rằng các phần tử trong Stream sẽ được duyệt theo thứ tự ban đầu, đặc biệt quan trọng khi Stream không còn có tính chất sắp xếp.
Supplier: Đây là một phương thức đại diện cho một hoạt động có thể tạo ra các giá trị mới trong Stream. Các phương thức trong Stream mà nhận các phần tử từ Supplier như sau:
- Stream.generate(Supplier<T> s): Phương thức
generatetạo ra một Stream bằng cách sử dụng một Supplier để tạo các phần tử trong Stream. - collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner): Phương thức
collectsử dụng một Supplier để tạo đối tượng kết quả và một BiConsumer để thêm các phần tử vào đối tượng kết quả. BiConsumer thứ hai được sử dụng để kết hợp các đối tượng kết quả từ các phần tử khác nhau khi thực hiện song song.
Những phương thức này cho phép bạn tạo và sử dụng Supplier để tạo các phần tử trong Stream và thực hiện các thao tác tổng hợp trên chúng.
import java.util.Arrays;
import java.util.List;
import java.util.function.Predicate;
public class FuncInterExample {
public static void main(String[] args) {
List<Integer> newList = Arrays.asList(5, 10, 15, 20, 25, 30, 35, 40, 45);
System.out.println("Displaying the array list:");
eval(newList, x -> true);
System.out.println("Displaying the odd numbers from the list:");
eval(newList, x -> x % 2 != 0);
System.out.println("Displaying the numbers smaller than 40:");
eval(newList, x -> x < 40);
}
public static void eval(List<Integer> newList, Predicate<Integer> newPred) {
for (Integer x : newList) {
if (newPred.test(x)) {
System.out.println(x);
}
}
}
}
Optional và Spliterator API
Lớp Optional và giao diện Spliterator, được định nghĩa trong gói java.util, có thể được sử dụng cùng với Stream API.
Optional là một đối tượng chứa một giá trị (không null) tùy ý. Nếu nó chứa một giá trị, phương thức isPresent() trả về true và get() trả về giá trị đó. Dưới đây là các phương thức terminal của Stream API trả về một đối tượng Optional:
- Optional<T> min(Comparator<? super T> comparator): Trả về giá trị tối thiểu dựa trên so sánh của
comparator. - Optional<T> max(Comparator<? super T> comparator): Trả về giá trị tối đa dựa trên so sánh của
comparator. - Optional<T> reduce(BinaryOperator<T> accumulator): Dùng để giảm thiểu các phần tử thành một kết quả duy nhất.
- Optional<T> findFirst(): Trả về phần tử đầu tiên trong trường hợp Stream có phần tử.
- Optional<T> findAny(): Trả về bất kỳ phần tử nào trong trường hợp Stream có phần tử.
Giao diện Spliterator được sử dụng để hỗ trợ thực hiện song song. Phương thức Spliterator.trySplit() tạo ra một Spliterator mới quản lý một tập hợp con của các phần tử của Spliterator gốc.
Cả hai Optional và Spliterator là thành phần của Java Stream API và được sử dụng để tối ưu hóa xử lý dữ liệu trong các trường hợp cụ thể.
Parallelism
Parallel computing bao gồm việc chia một nhiệm vụ thành các nhiệm vụ con, thực hiện các nhiệm vụ này đồng thời (song song), trong đó mỗi nhiệm vụ con chạy trong một luồng riêng biệt, và sau đó, kết hợp kết quả của các nhiệm vụ con thành một kết quả duy nhất. Trong Java, có sẵn framework fork/join giúp thực hiện tính toán song song một cách dễ dàng trong các ứng dụng khác nhau. Trong framework này, người dùng phải chỉ định cách chia nhiệm vụ. Các hoạt động tổng hợp được thực hiện tự động; Java runtime thực hiện phân chia và kết hợp nhiệm vụ này một cách tự động.
Việc triển khai tính toán song song trong các ứng dụng dựa trên bộ sưu tập có thể gặp khó khăn. Vì các bộ sưu tập tiêu chuẩn trong Java không được đảm bảo an toàn đối với luồng, việc thao tác bộ sưu tập bằng nhiều luồng có thể gây ra sự cố như xung đột luồng và lỗi nhớ.
Để giải quyết vấn đề này, Java Collections Framework cung cấp các wrapper đồng bộ hóa, cho phép đồng bộ hóa tự động cho một bộ sưu tập, biến nó trở nên an toàn đối với luồng. Tuy nhiên, đồng bộ hóa truyền thống có thể gây ra xung đột luồng và có thể ngăn chặn xử lý song song. Do đó, nên tránh nó.
Như một giải pháp thay thế, các hoạt động tổng hợp và luồng song song cho phép triển khai tính toán song song trong các bộ sưu tập không an toàn đối với luồng. Hiệu suất nhanh hơn của tính toán song song cũng phụ thuộc vào các yếu tố bên ngoài khác như bộ xử lý. Triển khai tính toán song song có thể đạt được một cách dễ dàng thông qua các hoạt động tổng hợp, tuy nhiên, người dùng phải quyết định xem một ứng dụng cần tính toán song song hay không. Kể từ Java phiên bản 8 trở đi, nó hỗ trợ tính toán song song và thực thi bằng cách sử dụng các luồng song song. Nó chia các luồng thành nhiều nhiệm vụ con và kết hợp chúng như đã giải thích trước đó. Bằng cách gọi lệnh parallel() trên một Stream, bạn có thể triển khai tính toán song song trên nhiều lõi xử lý.
Thêm phương thức parallel() vào Stream cho biết cho thư viện xử lý những khía cạnh phức tạp của đa luồng. Do đó, thư viện kiểm soát quá trình chia nhánh.
Thực thi Stream với Parallel
Các hoạt động tổng hợp được triển khai để kết hợp kết quả. Quá trình này được gọi là giảm cùng lúc (concurrent reduction). Có một số điều kiện sau đây phải đúng để thực hiện hoạt động thu thập trong quá trình này:
- Luồng phải là luồng song song (parallel).
- Tham số của hoạt động thu thập, bộ thu thập (collector), chứa đặc điểm bộ thu thập, collector.characteristics.CONCURRENT.
- Luồng phải là luồng không có thứ tự (unordered) hoặc bộ thu thập phải chứa đặc điểm bộ thu thập, Collector.characteristics.UNORDERED.
Ví dụ về StreamAPI:
import java.util.Arrays;
import java.util.IntSummaryStatistics;
import java.util.List;
import java.util.stream.Collectors;
public class ExamJavaStreamAPI {
public static void main(String[] args) {
List<String> clientList = Arrays.asList("Amazon", "Etsy", "Frodos", "wendys", "", "MaBeats", "Miniclip");
System.out.println("The new Client List: " + clientList);
// To receive the count of empty strings
long emptyCount = clientList.stream().filter(String::isEmpty).count();
System.out.println("Result: Number of Empty Strings: " + emptyCount);
// To receive companies with a character count length greater than 5
long lengthCount = clientList.stream().filter(x -> x.length() > 5).count();
System.out.println("Result: Number of clients with name length > 5: " + lengthCount);
// To receive the count of client names that start with the letter 'A'
long startCount = clientList.stream().filter(x -> x.startsWith("A")).count();
System.out.println("Result: Number of clients whose name starts with 'A': " + startCount);
// To eliminate all empty strings from the list
List<String> removeEmptyStrings = clientList.stream().filter(x -> !x.isEmpty()).collect(Collectors.toList());
System.out.println("Result: New Client List without empty strings: " + removeEmptyStrings);
// To display client names with length greater than 8 characters
List<String> newList = clientList.stream().filter(x -> x.length() > 8).collect(Collectors.toList());
System.out.println("Result: New client List with name length > 8: " + newList);
List<Integer> examInt = Arrays.asList(77, 66, 888, 22, 33, 7, 121, 89, 55);
IntSummaryStatistics examStats = examInt.stream().mapToInt(Integer::intValue).summaryStatistics();
System.out.println("A list of Random numbers: " + examInt);
System.out.println("Highest number in the list: " + examStats.getMax());
System.out.println("Lowest number in the list: " + examStats.getMin());
System.out.println("Combined value of ALL: " + examStats.getSum());
System.out.println("Average value of all numbers: " + examStats.getAverage());
// To convert a message to UPPERCASE and join with spaces
List<String> examTips = Arrays.asList("java8", "has", "some", "great", "features");
String joinList = examTips.stream().map(String::toUpperCase).collect(Collectors.joining(" "));
System.out.println("- To Join and Display the message in UPPERCASE: " + joinList);
// To display the cube value of the numbers
List<Integer> numbers = Arrays.asList(5, 10, 15, 20, 25);
List<Integer> cubes = numbers.stream().map(x -> x * x * x).distinct().collect(Collectors.toList());
System.out.println("- Display the cube value of the numbers: " + cubes);
}
}
Output:
The new Client List: [Amazon, Etsy, Frodos, wendys, , MaBeats, Miniclip]
Result: Number of Empty Strings: 1
Result: Number of clients with name length > 5: 5
Result: Number of clients whose name starts with 'A': 1
Result: New Client List without empty strings: [Amazon, Etsy, Frodos, wendys, MaBeats, Miniclip]
Result: New client List with name length > 8: []
A list of Random numbers: [77, 66, 888, 22, 33, 7, 121, 89, 55]
Highest number in the list: 888
Lowest number in the list: 7
Combined value of ALL: 1358
Average value of all numbers: 150.88888888888889
- To Join and Display the message in UPPERCASE: JAVA8 HAS SOME GREAT FEATURES
- Display the cube value of the numbers: [125, 1000, 3375, 8000, 15625]Đoạn mã dưới trình bày cách sử dụng API luồng để thao tác và hiển thị văn bản. Ví dụ này hiển thị một tập hợp các hoạt động luồng với danh sách tiểu bang của Úc:
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class ExamJavaStreamAPI2{
public static void main(String[] args) {
// To display the number of empty values in the state list
List<String> stateList = Arrays.asList("Victoria", "", "Queensland", "", "Tasmania");
long count = stateList.stream().filter(x -> x.isEmpty()).count();
System.out.printf("Australian state List has %d empty values%n", count);
// To display the state names with a character length more than 9
long num = stateList.stream().filter(x -> x.length() > 9).count();
System.out.printf("Australian state List has %d strings of length more than 9%n", num);
// To display the number of Australian states that start with the letter 'V'
count = stateList.stream().filter(x -> x.startsWith("V")).count();
System.out.printf("Australian state List contains %d state names which start with the letter 'V'%n", count);
// To display the Australian states list without empty values
List<String> filtered = stateList.stream().filter(x -> !x.isEmpty()).collect(Collectors.toList());
System.out.printf("Australian state List: %s, without any empty values: %s%n", stateList, filtered);
// To display and convert BRIC nations to lowercase and merge them with a comma
List<String> BRIC = Arrays.asList("BRAZIL", "INDIA", "RUSSIA", "CHINA");
String BRICNations = BRIC.stream().map(x -> x.toLowerCase()).collect(Collectors.joining(", "));
System.out.println("BRIC Nations in Lowercase: " + BRICNations);
}
}
Output:
Australian state List has 2 empty values
Australian state List has 3 strings of length more than 9
Australian state List contains 2 state names which start with the letter 'V'
Australian state List: [Victoria, , Queensland, , Tasmania], without any empty values: [Victoria, Queensland, Tasmania]
BRIC Nations in Lowercase: brazil, india, russia, china
Giới hạn của Java Stream API
Stream API bao gồm nhiều phương pháp mới để thực hiện các hoạt động tổng hợp trên danh sách và mảng; tuy nhiên, cũng có một số hạn chế trong API này. Chúng được mô tả như sau:
Biểu thức lambda không có trạng thái:
Nếu dòng luồng song song và biểu thức lambda có trạng thái, nó sẽ tạo ra một tập hợp ngẫu nhiên của đầu ra. Ví dụ:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class ExamJavaStreamLimit {
public static void main(String[] args) {
// Set of numbers in a proper order
List<Integer> numberSet = Arrays.asList(31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45);
List<Integer> result = new ArrayList<>();
Stream<Integer> stream = numberSet.parallelStream();
// To display the number set in a random manner
stream.map(number -> {
synchronized (result) {
if (result.size() < 40) {
result.add(number);
}
return number;
}
}).forEach(change -> {});
System.out.println("The jumbled number set: " + result);
}
}
Output:
The jumbled number set: [31, 34, 35, 36, 32, 33, 37, 38, 39, 40, 41, 42, 43, 44, 45]
Những cải tiến và tính năng mới trong stream API
Java 9, Java 12 và các phiên bản mới hơn đã giới thiệu một số cải tiến và tính năng mới trong API Stream.
Cải tiến Stream API
Một số phương thức mới đã được giới thiệu trong Java 9. Vì Stream là một giao diện, các phương thức được thêm vào nó là mặc định và tĩnh. Để sử dụng các phương thức này, sử dụng lệnh:
import java.util.stream.*Bảng dưới liệt kê các phương thức này cùng với ví dụ:
| Phương thức | Mô tả | Ví dụ |
| dropWhile() | Đây là phương thức mặc định và loại bỏ tất cả các phần tử của luồng cho đến khi điều kiện không còn đúng. | import java.util.stream.Stream; public class StreamDemo { public static void main(String[] args) { Stream mystream = Stream.of(18, 72, 55, 90, 100); mystream.filter(num -> num < 50).forEach(num -> System.out.println(num)); } } |
| takeWhile() | Đây là một phương thức mặc định và hoạt động ngược với dropWhile(). Phương thức này lấy tất cả các phần tử của luồng trong luồng kết quả cho đến khi “điều kiện không còn đúng”. Tóm lại, khi điều kiện không còn đúng, nó loại bỏ phần tử đó và tất cả các phần tử đi sau phần tử đó trong luồng. | import java.util.stream.Stream; public class StreamDemo { public static void main(String[] args) { Stream mystream = Stream.of(18, 72, 55, 90, 100); mystream.takeWhile(num -> num < 50).forEach(num -> System.out.println(num)); } } |
| iterate() | Đây là một phương thức tĩnh và có ba đối số, cụ thể là: Giá trị khởi tạo: luồng trả về bắt đầu với giá trị này. Predicate: việc lặp tiếp tục cho đến khi điều kiện này trả về giá trị sai. Giá trị cập nhật: cập nhật giá trị từ vòng lặp trước. | import java.util.stream.IntStream; public class StreamDemo { public static void main(String[] args) { IntStream.iterate(1, num -> num < 30, num -> num * 5) .forEach(num -> System.out.println(num)); } } |
| ofNullable() | Đây là một phương thức tĩnh và được giới thiệu để tránh lỗi NullPointerException. Phương thức này trả về một luồng trống nếu luồng ban đầu là null. Nó cũng có thể được sử dụng trên một luồng không rỗng, trong trường hợp này nó trả về một luồng tuần tự chứa một phần tử duy nhất. | import java.util.stream.Stream; public class StreamDemo { public static void main(String[] args) { Stream stream1 = Stream.ofNullable(null); stream1.forEach(str -> System.out.println(str)); Stream<String> stream2 = Stream.ofNullable(“Oranges”); stream2.forEach(str -> System.out.println(str)); } } |
Teeing Collector
Teeing Collector được giới thiệu trong Java 12. Một bộ thu thập là sự kết hợp của hai bộ thu thập con và giá trị trả về của Teeing Collector chính là sự kết hợp của hai bộ thu thập con đó. Mỗi phần tử được truyền vào bộ thu thập kết quả sẽ được xử lý bởi cả hai bộ thu thập con, và sau đó, kết quả của họ sẽ được hợp nhất bằng cách sử dụng hàm hợp nhất cụ thể để tạo ra kết quả cuối cùng. Nói một cách đơn giản, đây chỉ là một phương thức trợ giúp được thêm vào lớp Java.util.stream.Collectors, giúp giảm đi sự lặp lại trong mã khi bạn muốn kết hợp các bộ thu thập.
import java.util.stream.Collector;
import java.util.function.BiFunction;
public static <T, A1, A2, R1, R2, R> Collector<T, ?, R> teeing(
Collector<? super T, A1, R1> downstream1,
Collector<? super T, A2, R2> downstream2,
BiFunction<? super R1, ? super R2, R> merger) {
// Your method logic here
}
Ví dụ:
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TeeingDemo {
public static void main(String[] args) {
Collector<CharSequence, ?, String> joiningCollector = Collectors.joining(":");
Collector<String, ?, List<String>> listCollector = Collectors.toList();
Collector<String, ?, String[]> compositeCollector = Collectors.teeing(
joiningCollector,
listCollector,
(joinedString, strings) -> {
ArrayList<String> list = new ArrayList<>(strings);
list.add(joinedString);
String[] array = list.toArray(new String[0]);
return array;
}
);
String[] strings = Stream.of("Pink", "Blue", "Yellow", "Red")
.collect(compositeCollector);
System.out.println(java.util.Arrays.toString(strings));
}
}
Bài tập
Nghành công an cần quản lý các phương tiện giao thông gồm: ô tô, xe máy, xe tải.
Cần một chương trình quản lý phương tiện như yêu cầu sau:
Tạo interface Ivehicle, Trong interface vehicle, định nghĩa sẵn 3 phương thức
void khoiDong()
void dungXe()
void phanh()
Lớp Vehicle triển khai từ Ivehicle
3 lớp ô tô, xe máy, xe tải kế thừa từ vehicle Mỗi loại gồm các thông tin: ID, Hãng sản xuất, năm sản xuất, giá bán và màu xe.
Các ô tô có các thuộc tính riêng: số chỗ ngồi (Integer), kiểu động cơ (String).
Các xe máy có các thuộc tính riêng: công suất (Integer).
Xe tải cần quản lý thêm: Trọng tải (Integer).
Với 3 lớp ô tô, xe máy, xe tải triển khai các phương thức riêng đáp ứng y/c sau:
Với lớp xe máy khi chạy phương thức khởi động, sẽ in ra
- Khoi dong xe may
Tương tự với các lớp còn lại.
Với lớp xe tải triển khai riêng phương thức:
void choHang(Integer khoiluong)
Trong phương thức này, sẽ tính toán nếu khối lượng lớn hơn trọng tải xe thì sẽ in ra:
- Khoi luong khong phu hop
Nếu không sẽ in ra:
- Khoi luong phu hop
Với lớp ô tô triển khai riêng phương thức
Integer choKHach(Integer sohanhkhach)
Phương thức này sẽ in ra xem số hành khách có nhiều hơn số chỗ ngồi của xe hay không và return ra số hành khách bị thừa cuối phương thức.
- Yêu cầu 1: Xây dựng các lớp để quản lý các phương tiện trên sao cho hiệu
quả. - Yêu cầu 2: Xây dựng lớp QLPTGT có các chức năng:
- Thêm, xoá(theo ID) các phương tiện thuộc các loại trên.
- Gọi tính năng choHang của xe tải theo ID
- Gọi tính năng choKHach của ô tô theo ID
- Tìm phương tiện theo hãng sản xuất, màu.
- Thoát chương trình.
Hướng dẫn
Bài viết liên quan:

Dịch vụ thiết kế Wesbite


